This is about the predicting MNIST accuracy with Gradient Descent(GD) vs Stochastic Gradient Descent(SGD).
(Here’s my notebook)
First I tried use GD to predict MNIST. Then it was amazing slow and I couldn’t arrive at any good accuracy at all.
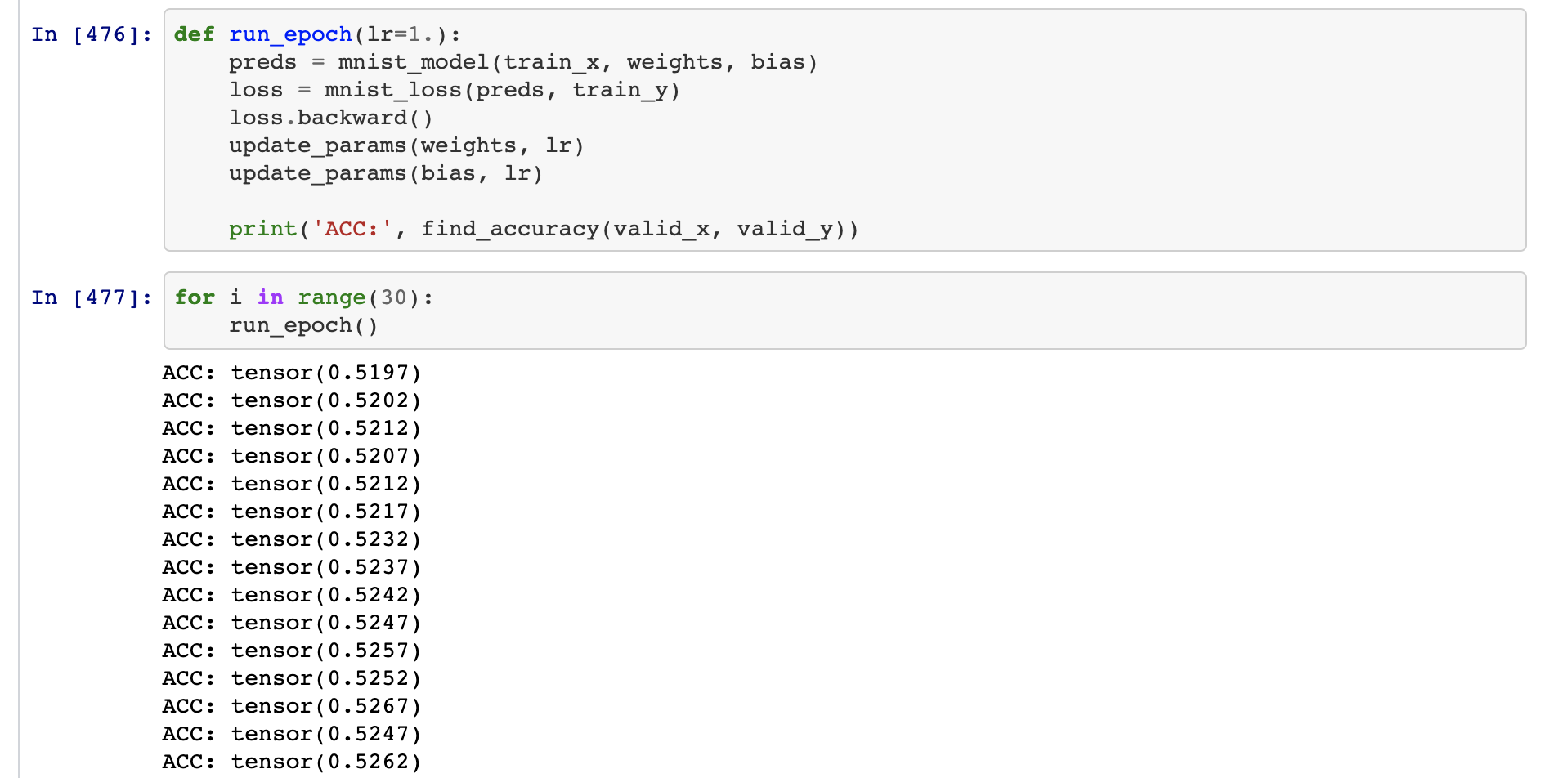
I thought, I am doing something wrong. So, I decided to use SGD with the DataLoader as mentioned in the book.
Wow. I didn’t expect this.
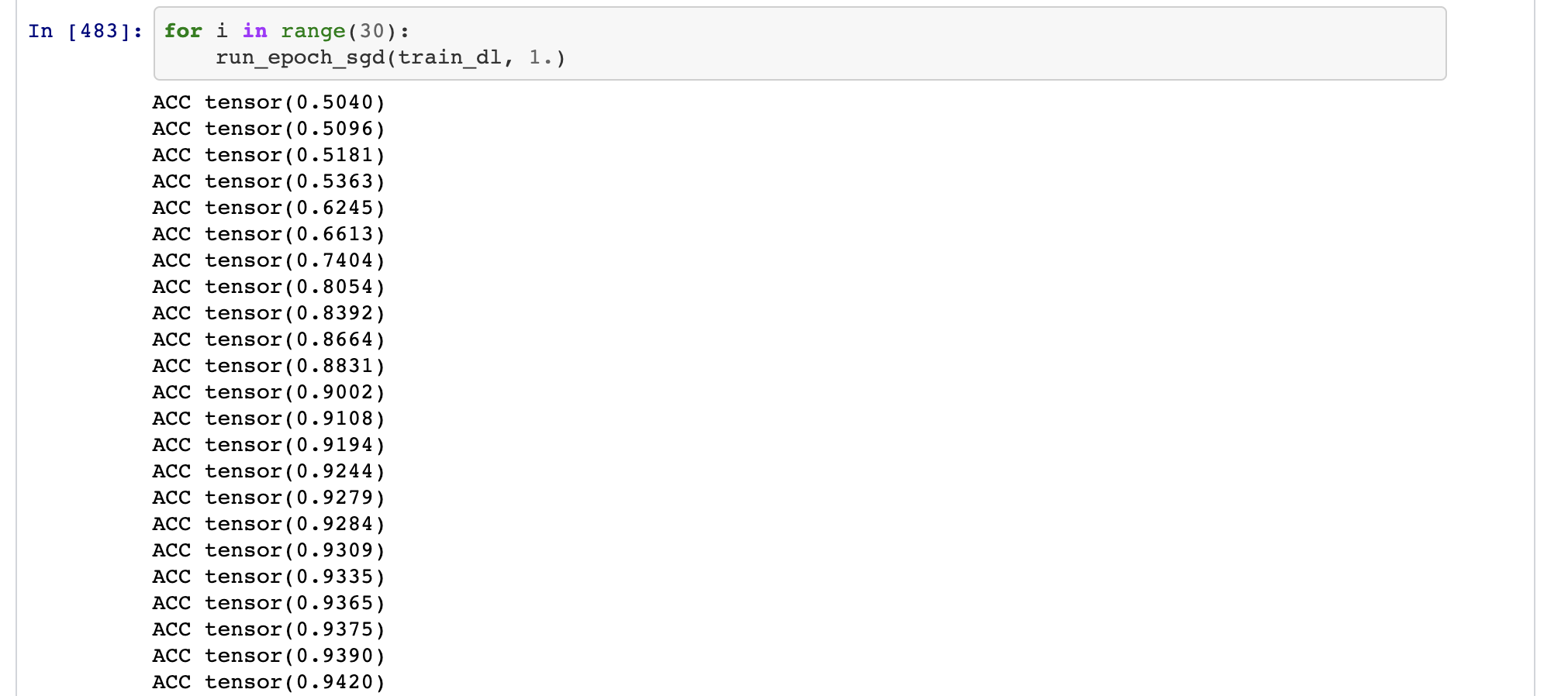
I think this is something we should include in the fastbook and the course.
This shows us really why we need to use SGD.
Also, I also want to know why we are using a learning rate like 1. With the real fastai library, we used something like 1e-5.