in your example the correct order to read should be:
1,5,9,2,6,…
you can convert the matrix of tokens into words and see what does it contain and in what order
but this will change the order of the word in the sentence.
as i said here:
And by that we need read it from a column and not row.
No?
why don’t you just start again from the very beginning. Take your example (copied from above):
next(iter(md.trn_dl))i
(Variable containing:
12 567 3 … 2118 4 2399
35 7 33 … 6 148 55
227 103 533 … 4892 31 10
… ⋱ …
19 8879 33 … 41 24 733
552 8250 57 … 219 57 1777
5 19 2 … 3099 8 48
[torch.cuda.LongTensor of size 75x64 (GPU 0)], Variable containing:
35
7
33
⋮
22
3885
21587
[torch.cuda.LongTensor of size 4800 (GPU 0)])
convert it to words and see what is the result
Sound good, sorry if it inefficient.
OK, This is when I take row:
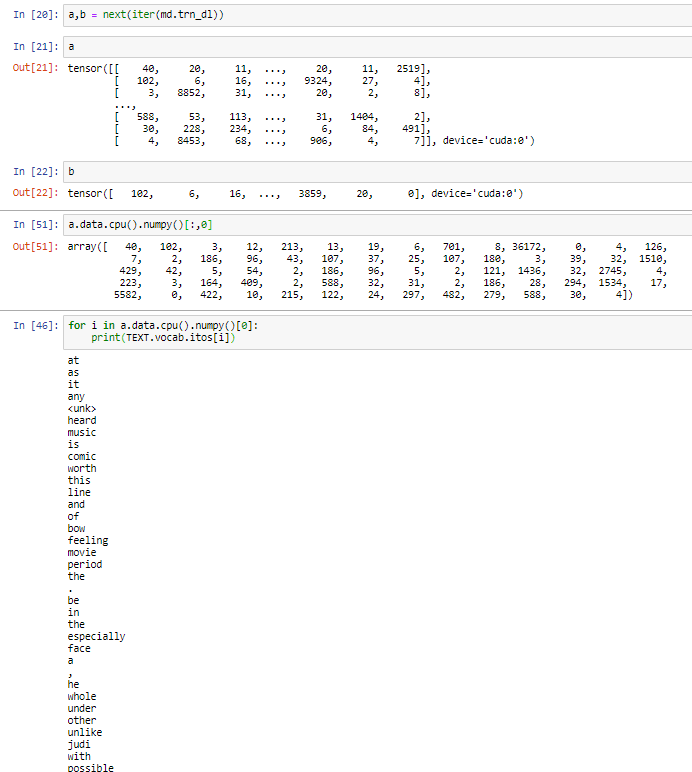
the order of the words is not right.
when I take the column:

looks right.
and as I expected the order of the words in the flattened matrix isn’t correct
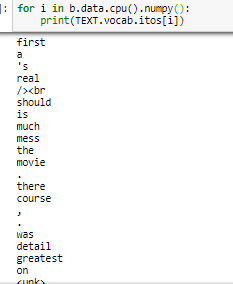
and again I really appreciate your time and for helping me to understand.
no problem, I am learning as well. Seems my understanding was wrong: sentences are indeed in columns. Double checked the source code: nlp.py, line 144:
def batchify(self, data):
nb = data.size(0) // self.bs
data = data[:nb*self.bs]
data = data.view(self.bs, -1).t().contiguous()
if self.backwards: data=flip_tensor(data, 0)
return to_gpu(data)
data gets transposed, so sentences appear in columns.
So the logic is that sentences are in columns (read top-down) -> to get a batch we slice it with length of ‘sequence_len’ -> we get some parts of many sentences, this is our ‘x’.
For ‘y’ we do the same, only difference is that we slice starting 1 row later -> then we flatten y.
As sentences are in columns, then flattened y doesnt make sense for our eyes. But for neural net it does not matter. Important is that they are consistent with each other. If we would transform y back to matrix then it would be similar to x, and vice verca if we would flatten x, then it would be similar to y. Maybe that helps to understand it better?
take a look at a get_batch function below
nlp.py line 151:
def get_batch(self, i, seq_len):
source = self.data
seq_len = min(seq_len, len(source) - 1 - i)
return source[i:i+seq_len], source[i+1:i+1+seq_len].view(-1)
1 Like
I happy to hear we understand each other now 
OK, I understand now but do you understand why we even should flatten y.
because we want to have only one item (token) as a prediction for each input (word sequence)