Hello, I’m currently working on trying to implement collaborative filtering on an e-commerce site. However, I’m getting an issue “embedding(): argument ‘indices’ (position 2) must be Tensor, not NoneType” when trying to create biases and weights in my CollabLearner. I’ve narrowed down the problem to it not making an array of tensors. However, I don’t know why it doesn’t make that array. I’m following the tutorial practically.
I’m getting the same error, but with this additional message:
“You’re trying to access an item that isn’t in the training data.
If it was in your original data, it may have been split such that it’s only in the validation set now.”
So maybe you have the problem with validation/training split?
EDIT: I was using DataFrame instead of array of titles.
I’m getting the same error and cannot get the items into a format that will feed into learn.bias()
The items are just a sequence of numbers from 0 - 99. I am not very knowledgeable about pandas but have tried creating an array of numbers to put into the function but keep getting the error “embedding(): argument ‘indices’ (position 2) must be Tensor, not NoneType”
Can anyone help? The dataframe I’m using is in the form of userid, itemid, rating.
I am facing this problem in the collaborative filtering notebook that is a part of the course of Deep learning for coders part 1. So I am unable to proceed further with what Jeremy is teaching, can someone please reply how to solve the issue.
Thanks
I’ve experienced this issue off and on for some time. I am now running fastai2 and was okay until yesterday when this once again popped up.
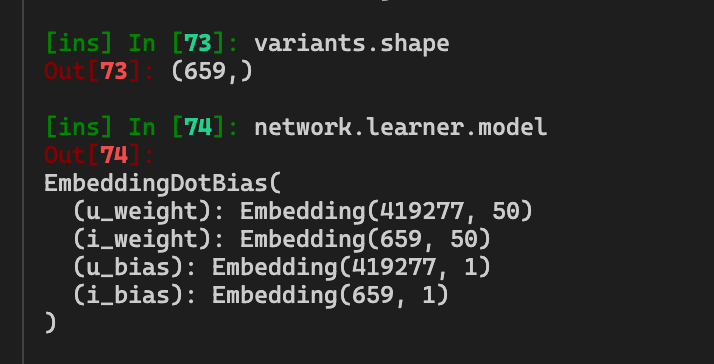
Interestingly, if I truncate the array, it will work. The size of the array is inconsistent from model to model training. But as an example, the following will work:
variants = (
ratings
.groupby('variant_id')['rating']
.count()
.sort_values(ascending=False)
.index
)
truncation_number = 4 # This changes between 0 (normal behavior) and int (the current error)
learner.model.weight(
variants[:-truncation_number], is_item=True
)