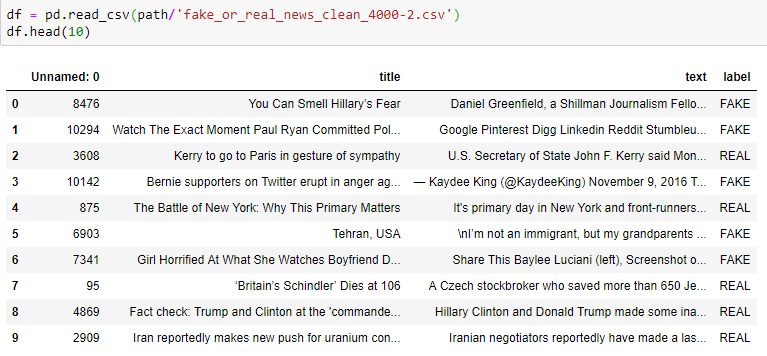
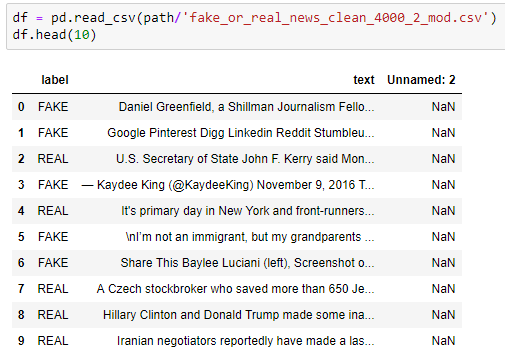
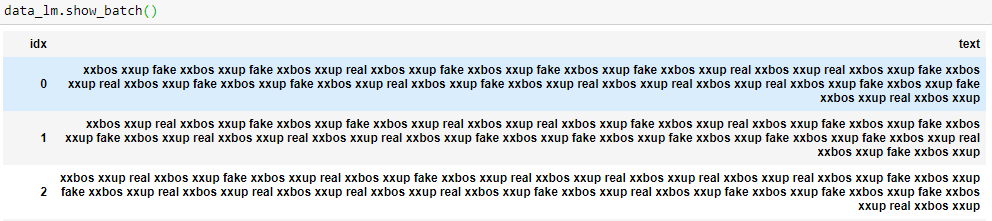
Can someone tell me what’s wrong with this? I get
TypeError: must be str, not int
from
.label_from_df(cols='label')
I get the same error if I use (cols=3), which works in the IMDB nb.
data = (TextList.from_csv(path, 'fake_or_real_news.csv', col='text')
.random_split_by_pct(0.2)
.label_from_df(cols='label')
.databunch())
TypeError Traceback (most recent call last)
/opt/conda/envs/fastai/lib/python3.6/site-packages/pandas/core/ops.py in na_op(x, y)
1011 try:
-> 1012 result = expressions.evaluate(op, str_rep, x, y, **eval_kwargs)
1013 except TypeError:
/opt/conda/envs/fastai/lib/python3.6/site-packages/pandas/core/computation/expressions.py in evaluate(op, op_str, a, b, use_numexpr, **eval_kwargs)
204 if use_numexpr:
--> 205 return _evaluate(op, op_str, a, b, **eval_kwargs)
206 return _evaluate_standard(op, op_str, a, b)
/opt/conda/envs/fastai/lib/python3.6/site-packages/pandas/core/computation/expressions.py in _evaluate_numexpr(op, op_str, a, b, truediv, reversed, **eval_kwargs)
119 if result is None:
--> 120 result = _evaluate_standard(op, op_str, a, b)
121
/opt/conda/envs/fastai/lib/python3.6/site-packages/pandas/core/computation/expressions.py in _evaluate_standard(op, op_str, a, b, **eval_kwargs)
64 with np.errstate(all='ignore'):
---> 65 return op(a, b)
66
/opt/conda/envs/fastai/lib/python3.6/site-packages/pandas/core/ops.py in radd(left, right)
112 def radd(left, right):
--> 113 return right + left
114
TypeError: must be str, not int
During handling of the above exception, another exception occurred:
TypeError Traceback (most recent call last)
/opt/conda/envs/fastai/lib/python3.6/site-packages/pandas/core/ops.py in safe_na_op(lvalues, rvalues)
1032 with np.errstate(all='ignore'):
-> 1033 return na_op(lvalues, rvalues)
1034 except Exception:
/opt/conda/envs/fastai/lib/python3.6/site-packages/pandas/core/ops.py in na_op(x, y)
1022 mask = notna(x)
-> 1023 result[mask] = op(x[mask], y)
1024
/opt/conda/envs/fastai/lib/python3.6/site-packages/pandas/core/ops.py in radd(left, right)
112 def radd(left, right):
--> 113 return right + left
114
TypeError: must be str, not int
During handling of the above exception, another exception occurred:
TypeError Traceback (most recent call last)
<ipython-input-62-09c1b499b3ab> in <module>
1 data = (TextList.from_csv(path, 'fake_or_real_news.csv', col='text')
2 .random_split_by_pct(0.2)
----> 3 .label_from_df(cols='label')
4 .databunch())
/opt/conda/envs/fastai/lib/python3.6/site-packages/fastai/data_block.py in _inner(*args, **kwargs)
316 self.valid = fv(*args, **kwargs)
317 self.__class__ = LabelLists
--> 318 self.process()
319 return self
320 return _inner
/opt/conda/envs/fastai/lib/python3.6/site-packages/fastai/data_block.py in process(self)
360 def process(self):
361 xp,yp = self.get_processors()
--> 362 for i,ds in enumerate(self.lists): ds.process(xp, yp, filter_missing_y=i==0)
363 return self
364
/opt/conda/envs/fastai/lib/python3.6/site-packages/fastai/data_block.py in process(self, xp, yp, filter_missing_y)
428 filt = array([o is None for o in self.y])
429 if filt.sum()>0: self.x,self.y = self.x[~filt],self.y[~filt]
--> 430 self.x.process(xp)
431 return self
432
/opt/conda/envs/fastai/lib/python3.6/site-packages/fastai/data_block.py in process(self, processor)
58 if processor is not None: self.processor = processor
59 self.processor = listify(self.processor)
---> 60 for p in self.processor: p.process(self)
61 return self
62
/opt/conda/envs/fastai/lib/python3.6/site-packages/fastai/text/data.py in process(self, ds)
275 def process_one(self, item): return self.tokenizer._process_all_1([item])[0]
276 def process(self, ds):
--> 277 ds.items = _join_texts(ds.items, self.mark_fields)
278 tokens = []
279 for i in progress_bar(range(0,len(ds),self.chunksize), leave=False):
/opt/conda/envs/fastai/lib/python3.6/site-packages/fastai/text/data.py in _join_texts(texts, mark_fields)
334 if is1d(texts): texts = texts[:,None]
335 df = pd.DataFrame({i:texts[:,i] for i in range(texts.shape[1])})
--> 336 text_col = f'{BOS} {FLD} {1} ' + df[0] if mark_fields else f'{BOS} ' + df[0]
337 for i in range(1,len(df.columns)):
338 text_col += (f' {FLD} {i+1} ' if mark_fields else ' ') + df[i]
/opt/conda/envs/fastai/lib/python3.6/site-packages/pandas/core/ops.py in wrapper(left, right)
1067 rvalues = rvalues.values
1068
-> 1069 result = safe_na_op(lvalues, rvalues)
1070 return construct_result(left, result,
1071 index=left.index, name=res_name, dtype=None)
/opt/conda/envs/fastai/lib/python3.6/site-packages/pandas/core/ops.py in safe_na_op(lvalues, rvalues)
1035 if is_object_dtype(lvalues):
1036 return libalgos.arrmap_object(lvalues,
-> 1037 lambda x: op(x, rvalues))
1038 raise
1039
pandas/_libs/algos_common_helper.pxi in pandas._libs.algos.arrmap_object()
/opt/conda/envs/fastai/lib/python3.6/site-packages/pandas/core/ops.py in <lambda>(x)
1035 if is_object_dtype(lvalues):
1036 return libalgos.arrmap_object(lvalues,
-> 1037 lambda x: op(x, rvalues))
1038 raise
1039
/opt/conda/envs/fastai/lib/python3.6/site-packages/pandas/core/ops.py in radd(left, right)
111
112 def radd(left, right):
--> 113 return right + left
114
115
TypeError: must be str, not int