I cannot download using kaggle-cli as the value I am trying for competition name “Dog Breed Identification” is not recognized as the competition name. Does anyone know the name that is used for downloading?
I think the best way to check the competition name is to go on Kaggle’s website to the competition and use what is in the url. Like this one https://www.kaggle.com/c/dog-breed-identification so probably try using dog-breed-identification
I found an interesting description of a cropping strategy in the following (now rather old) paper which introduced InceptionNet: https://arxiv.org/pdf/1409.4842.pdf
“During testing,we adopted a more aggressive cropping approach than that of Krizhevskyet al… Specifically, we resize the image to 4 scales where the shorter dimension (height or width) is 256, 288, 320 and 352 respectively, take the left, center and right square of these resized images (in the case of portrait images, we take the top, center and bottom squares). For each square, we then take the 4 corners and the center 224×224 crop as well as the square resized to 224×224, and their mirrored versions. This results in 4×3×6×2 = 144 crops per image. A similar approach was used by Andrew Howard in the previous year’s entry, which we empirically verified to perform slightly worse than the proposed scheme. We note that such aggressive cropping may not be necessary in real applications, as the benefit of more crops becomes marginal after a reasonable number of crops are present (as we will show later on).”
This strategy is in relation to the original training of the InceptionNet, so not really the same as our post-hoc augmentation process. But I wonder if @jeremy or anyone else experienced in this cares to comment on this approach of creating a great many crops - can it be applied to the augmentation approach?
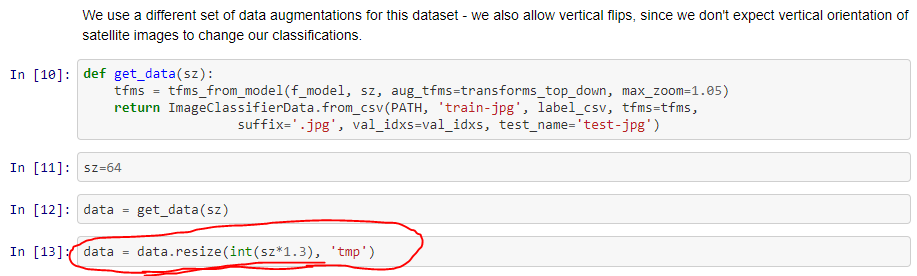
Can anyone clarify something I saw in Jeremy’s notebook for the Dog Breeds compeition: After using the ps parameter to 0.5 he only did 2 cycles - was this just to save time while evaluating the change, or is something else going on - I remember him saying that too many cycles lead to overfitting, but is that what is being done here?
ps and the use of 2 cycles vs more is something we’ll talk about later, but basically we’re trying to avoid overfitting, since this architecture is a lot bigger.
num_workers just says how many CPU cores to use for preprocessing - it’s not a big deal and doesn’t effect anything except speed.
Thanks Jeremy, yes I understand that we are randomly cropping, but this strategy indicates rather severe cropping, including corners, and 144 crops per image. It was in relation to this extreme approach I was asking my question.
A (mini) batch vs a cycle / epoch and learning rate
Can anyone explain what @jeremy means around 38 minute mark of lesson 2 about changing the learning rate every mini batch? What is a mini batch, in our learn.fit() method we pass learning rate, number of epochs, cycle length - is a batch an amalgamation of these settings?
We have batch size as part of our model, so is a batch how many images we feed to the model at a time within an epoch? If so, is Jeremy saying that the learning rate changes after every bunch of images are passed in?
If learning rate changes based on the presence of a new batch, what influence does cycle length have on changing the learning rate? Jeremy there talks about resetting it.
So, changing vs resetting learning rate - what is the difference?
Instead of going through all of the items one by one in one loop, we process items in small batches e.g. bs = 64 (default). This is the power of GPU. In one epoch, we process ‘X’ mini-batches. The total number of mini-batches is given by:
total_mini_batches = total_items/batch_size
So, as you continue to process these mini batches we continue to reduce ‘lr’. An iteration would then be going once through the loop, which I believe would be processing one ‘mini-batch’.