indeed, that would be a lovely addition
@simonw asked the question before I got to that in the video FYI.
Having said that, please be sure that your answers are helpful to the person asking the question. i.e. instead of just saying “it’s in the video”, try providing a link to the relevant time-stamp, or just answer the question yourself.
I’ve been having problems regarding using custom models with create_cnn.

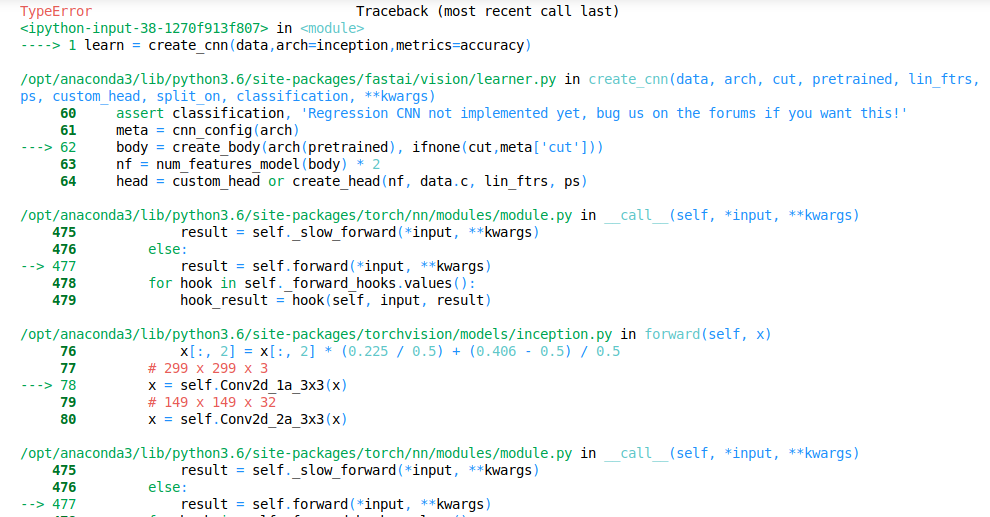
I am getting this error
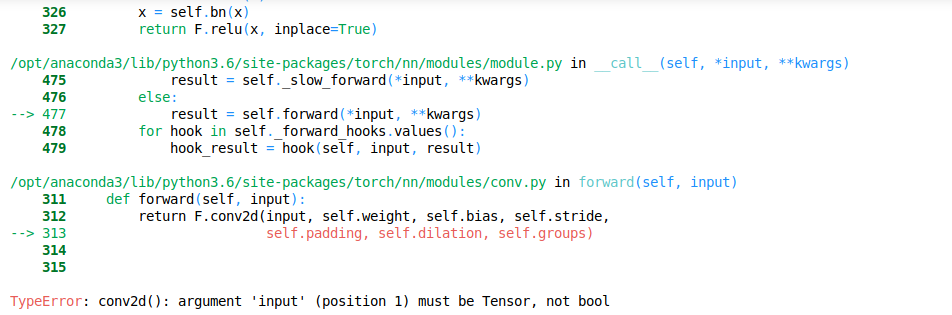
I found that in this body = create_body(arch(pretrained), ifnone(cut,meta['cut'])), create_body takes pretrained(bool value) as input here and doesn’t pass a Tensor in this case.
While this method works with resnet (models.resnet18(True)), ResNet defined in models takes only pretrained bool value as input (pretrained=True,**kwargs). it may not be applicable with custom models always. Models usually takes (input,**kwargs)``#input Tensor
What can be the fix ?
1 Like
File Deleter is a very cool tool but, as others comment here apparently by now it can not clean train set, only validation set.
I think to address label noise issue train cleaning is at least as important as validation cleaning. Otherwise we are just cleaning noise in validation set what is ok but will make subsequent -certain- validation improvement only due to cleaning. In other words, we are helping the model by a more reliable validation but not a more reliable training set.
A hacky workaround to clean all data is possible with the tool in its current state: Before doing “real” training you can set a bigger validation ratio, say 0.5 and run the model + cleaning tool three/four times, with different random seeds each time for validation split. After that you can do real training with an -almost- completely clean dataset.
4 Likes
We are working on this. For the moment you can use this function:
def get_toploss_paths(md, ds, dl, loss_func, n_imgs=None): if not n_imgs: n_imgs = len(dl) val_losses = get_preds(md, dl, loss_func=loss_func)[2] losses,idxs = torch.topk(val_losses, n_imgs) return ds.x[idxs]
Where you can either feed in Training or Validation Dataset and Dataloader. For the lesson 2 notebook you can call it like this:
train_toploss_fns = get_toploss_paths(learn.model, data.train_ds, data.train_dl, learn.loss_func)
You can then feed train_toploss_fns to FileDeleter.
We are also working on showing and being able to change the labels in the widget.
14 Likes
I’ve extended the sgd notebook of lesson 2 to polynomial fitting:
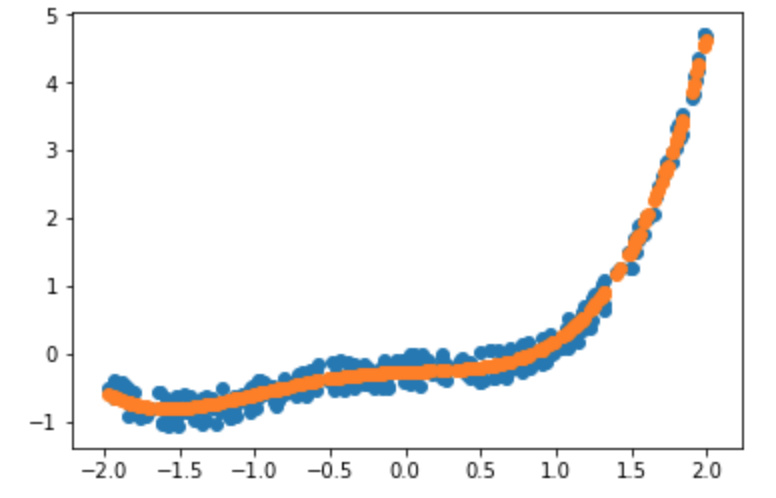
That wasn’t easy and I was stuck with an error on the “update” function…
But solving it, I 've got a better understanding of PyTorch mechanics: in particular the difference between constant tensors (without gradient) and parameters (differentiable - with “gradient”).
8 Likes
Can someone suggest me a tutorial for developing web app please ?  , I don’t understand clearly the instruction I find in Scarlette web site. Thank you in advance.
, I don’t understand clearly the instruction I find in Scarlette web site. Thank you in advance.
2 Likes
I’m also having trouble install starlette from their instructions:
$ pip3 install starlette
Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection broken by 'ConnectTimeoutError(<pip._vendor.urllib3.connection.HTTPConnection object at 0x10eeb0630>, 'Connection to 52.39.238.16 timed out. (connect timeout=20.0)')': /repository/pypi-all/simple/starlette/
Could not find a version that satisfies the requirement starlette (from versions: )
No matching distribution found for starlette
I would suggest using a different web app with better documentation, maybe Flask.
Here’s a tutorial.
2 Likes
I’m not sure which part of web app you would like to know better but there are more tutorials about flask which i fairly similar to starllet
you can try those ones
M
2 Likes
Thank you @Michal_w, @astronomy88 . So I switch to Flask now. Maybe I will comeback to Starlette later but at this moment, it’s hard to undertand from their instructions.
Yes.
Thanks.
Is there web app tutorials written by students? It might be easier to understand when they use fastai.
1 Like
I’m getting error name ‘verify_images’ is not defined while running
verify_images(path/c, delete=True, max_workers=8)
That should be the ideal goal of a neural network. To act as the most efficient lookup table.
2 Likes
I’m not sure if anyone has encountered this but when I run FileDeleter it disconnects me from my remote server and sort of kills it in a bad way. Only option is to stop instance => re-launch => re-run notebook (and skip FileDeleter).
Tried it on AWS, Colab and GCP. Every time the same result.
Update[11/4/18]: @sgugger bringing this to your attention as I couldn’t find any answer on the forum, still trying to understand the issue better with the code.
Always try using models.$MODEL as your arch, fastai.vision.models has most of it.
I think you can also look at the part where jeremy talks about how models.resnet34 is just a functional way of defining a resnet type arch and not actually using the resnet34 model, for which we use pretrained=True.
Interesting, I too found a similar situation (in fact a little more mind boggling).
My guess for this situation is
- The error_rate is just the miss classification rate and if it stays the same, then for every epoch, your model is miss classifying the same number of images if not the exact same image
- You val_loss bumps up a little as your train_loss goes down, this doesn’t look like a problem since both are in a similar range and the loss_func only helps the model find better weights w.r.t the given data. In every epoch, the loss_func tries the same with minor weight adjustments which fluctuates the avg loss over the epoch BUT the marginal changes doesn’t really affect the FC layers(in this example) eventually leading to same/similar classification tags ( This is to best of my knowledge)
- You many also find situations where the error_rate drops then goes huge then drops a couple of times in ~20 epochs, I found this happening today and still trying to figure out how to improve. But my learning stands
Loss function is helping the model learn, metrics is my specific way of checking how exactly the model learned, these two are related but not coupled
Could you add a snippet showing how will you use models other than resnet (custom models) (that aren’t defined in fastai). As of now it only has support for Resnet, wideresnet and Unet.
1 Like
Hi, I have been trying BooldCell classification and I am having trouble inferring losses of the model prepared.
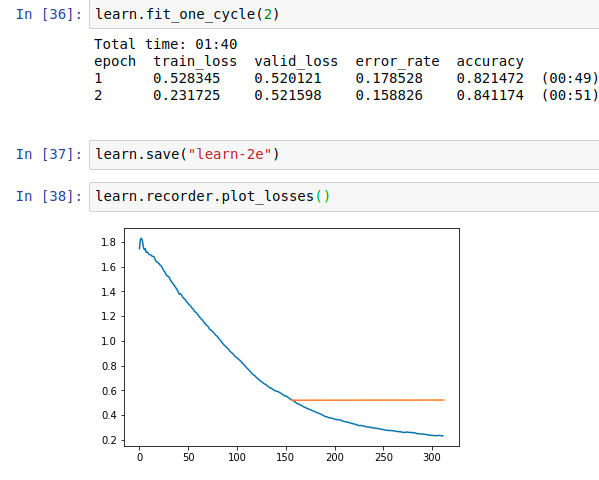
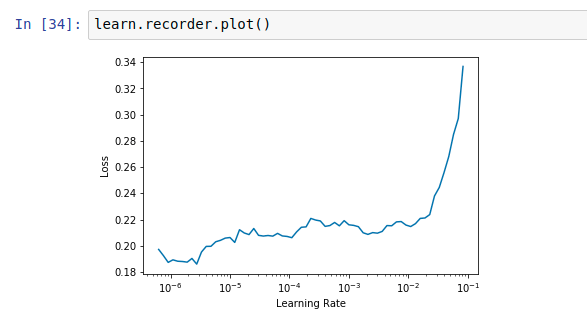
I was wondering should we consider the epoch exactly where the error rate starts getting worse. The lr_find() for resnet34 or resnet50 is also not giving any clear trend in the range of 10e-6 and above.
Resnet34
Resnet50
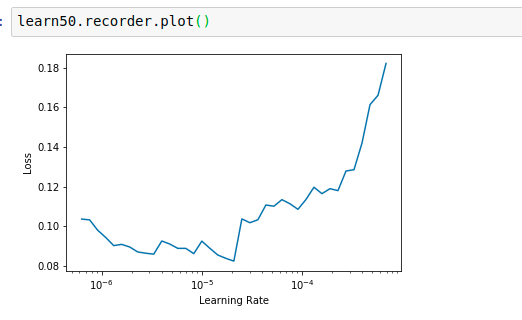
The default value seems to be doing fine for 1-2 epochs. Is there any logic in increasing the LR. If anyone can help me understand how to deal with such a situation please let me know. When I unfreeze and fit with default LR the error drops but it doesn’t improve after 1 epoch.
Also Jeremy mentioned about the error rate might be good indicator of over-fitting but as the error rate improves if the validation loss starts getting worse should we consider it positive or negative effect.
If I am not clear anywhere please let me know.
It looks like you are fitting better to the training data (train loss < valid loss) but your accuracy is still increasing/error rate still is going down, so not a real overfitting.
Based on your lr_find results, try to setup your learning with a max_lr parameter like this:
learn.fit_one_cycle(x, max_lr=1e-6) (x = number of epochs)
When you don’t supply a max_lr parameter it uses 0.003, which is maybe too much in your case and you end up “going down the minima valley jumping around or jumping out of it” (nice animation, see the last two images).
I would be curious about what happens when you train a couple of epochs on top with a max_lr?
2 Likes