Hello
I am testing the pretrained model from Lesson 10 IMDB on custom dataset.
Is there any requirements for these datasets?
I am using as trained data 15 rows.
All the steps run okay
but at the Classifier
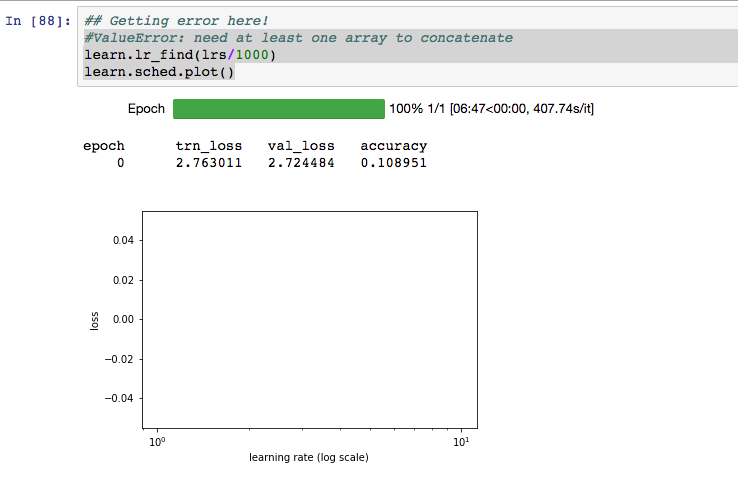
- At first I got
: ValueError: need at least one array to concatenate
learn.lr_find(lrs/1000)
learn.sched.plot()
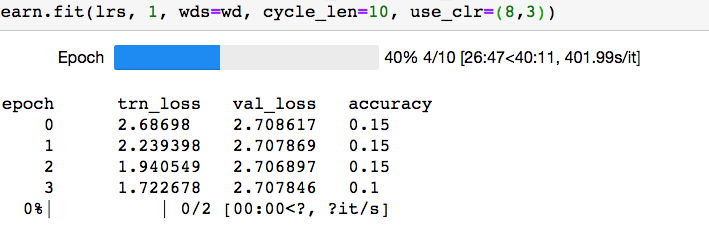
So then I concatenated my training set a couple of times just to increase the dataset size.
So then there was no error at this stage.
However there was no plot output …
- Then however in
learn.fit(lrs, 1, wds=wd, cycle_len=1, use_clr=(8,3))
I get zerodivision error.
ZeroDivisionError Traceback (most recent call last)
in ()
----> 1 learn.fit(lrs, 1, wds=wd, cycle_len=1, use_clr=(8,3))
~/lpsbigger-topic/fastai/text.py in fit(self, *args, **kwargs)
209
210 def _get_crit(self, data): return F.cross_entropy
–> 211 def fit(self, *args, **kwargs): return super().fit(*args, **kwargs, seq_first=True)
212
213 def save_encoder(self, name): save_model(self.model[0], self.get_model_path(name))
~/lpsbigger-topic/fastai/learner.py in fit(self, lrs, n_cycle, wds, **kwargs)
285 self.sched = None
286 layer_opt = self.get_layer_opt(lrs, wds)
–> 287 return self.fit_gen(self.model, self.data, layer_opt, n_cycle, **kwargs)
288
289 def warm_up(self, lr, wds=None):
~/lpsbigger-topic/fastai/learner.py in fit_gen(self, model, data, layer_opt, n_cycle, cycle_len, cycle_mult, cycle_save_name, best_save_name, use_clr, use_clr_beta, metrics, callbacks, use_wd_sched, norm_wds, wds_sched_mult, use_swa, swa_start, swa_eval_freq, **kwargs)
232 metrics=metrics, callbacks=callbacks, reg_fn=self.reg_fn, clip=self.clip, fp16=self.fp16,
233 swa_model=self.swa_model if use_swa else None, swa_start=swa_start,
–> 234 swa_eval_freq=swa_eval_freq, **kwargs)
235
236 def get_layer_groups(self): return self.models.get_layer_groups()
~/lpsbigger-topic/fastai/model.py in fit(model, data, n_epochs, opt, crit, metrics, callbacks, stepper, swa_model, swa_start, swa_eval_freq, **kwargs)
107 avg_mom=0.98
108 batch_num,avg_loss=0,0.
–> 109 for cb in callbacks: cb.on_train_begin()
110 names = [“epoch”, “trn_loss”, “val_loss”] + [f.name for f in metrics]
111 if swa_model is not None:
~/lpsbigger-topic/fastai/sgdr.py in on_train_begin(self)
269 def on_train_begin(self):
270 self.cycle_iter,self.cycle_count=0,0
–> 271 super().on_train_begin()
272
273 def calc_lr(self, init_lrs):
~/lpsbigger-topic/fastai/sgdr.py in on_train_begin(self)
135 def on_train_begin(self):
136 super().on_train_begin()
–> 137 self.update_lr()
138 if self.record_mom:
139 self.update_mom()
~/lpsbigger-topic/fastai/sgdr.py in update_lr(self)
147
148 def update_lr(self):
–> 149 new_lrs = self.calc_lr(self.init_lrs)
150 self.layer_opt.set_lrs(new_lrs)
151
~/lpsbigger-topic/fastai/sgdr.py in calc_lr(self, init_lrs)
275 if self.cycle_iter>cut_pt:
276 pct = 1 - (self.cycle_iter - cut_pt)/(self.nb - cut_pt)
–> 277 else: pct = self.cycle_iter/cut_pt
278 res = init_lrs * (1 + pct*(self.div-1)) / self.div
279 self.cycle_iter += 1
ZeroDivisionError: division by zero
To me it seems like it is an error that is caused by the dataset not satisfying certain conditions. However it is not very clear to me what it should satisfy.