The training is done with 11501 cat and 11501 dog image. What would you expect to happen if instead, we had 20% fewer dog images?
Hi Radi,
It means 9200 dogs images and 11501 cats
dogs are 44.4% of the dataset, cats are 53.6%
It’s not very unbalanced
The neural network can have a tendency to answer cats because he’s right 53.6% of the time.
Against unbalanced dataset:
8 Tactics to Combat Imbalanced Classes in Your Machine Learning Dataset
In your case, something easy is to do some data augmentation on cats images to have again a balanced dataset
I am working on it 
Trying to remove all the broken images first. New to Python so it might take me some time, but I am learning a ton in the process for sure 
You can use the existing dataset from the course and just move a few images out of the way temporarily…
1 Like
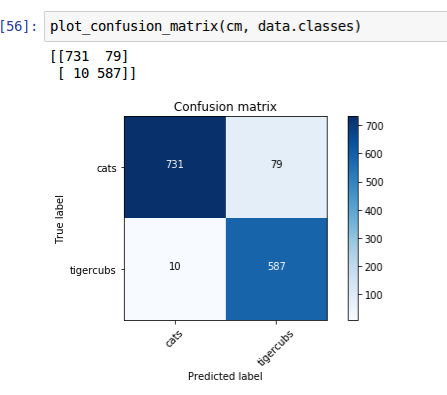
For the lesson 1 exercise I am comparing cats vs tigercubs. Carefully downloaded the images from google image search to get a mix of different sub categories of cats and tigercubs so that the differences are not just fur color.
This is the split of number of images:

I am getting a 94% accuracy. The incorrect predictions seemed very reasonable.
This is what the confusion matrix looks like:
1 Like
@radi let me know if I can help you get unstuck. For me the greatest challenge was to overcome the propensity to change something wrt Jeremy’s videos. I tried to learn to come up with a cool script to create the folders and split the images etc and finally just created the folders manually, downloaded the images directly into the directory/folders (all using GUI) and then used scp to upload the entire directory into paperspace/data. Didn’t even zip anything. I had 130Mb of data and it took about 2 min to upload using ssh. The end result is I have a working system that I can break and put together as much as I like. For example, I now want to digitally modify my test set (perhaps even try to use the autoencoders) and see what happens to the predictions. Also, in the data I downloaded, there were images of motorcycles mixed with the tigercubs!
2 Likes
Hi I have an unbalanced data set. My images are parts of a grass field. One folder contains small images of grass without a particular weed and the other contains small images of grass with a particular weed. The challenge is I have far fewer pics of just grass in comparison to the pics of grass and weeds. Does the fast Ai library automatically duplicate images in the smaller folder to balance the numbers?
I have 2700 images of grass
I have 518 images of grass plus weeds
Should I manually copy the images of the grass plus weeds to balance up?
Thanks