The model is unaffected by the images passed in for prediction - unless you set up some kind of score and retrain process. The image will just get predicted as best the model can do (and probably finds some dog breed even with low probability). I don’t know about flask and react - but there are some samples of how to deploy in the share your work forum - and the production section of the landing page - https://course.fast.ai/index.html
1 Like
You are using an updated version of fastai that adds heatmaps that demonstrate what part of the image the CNN is focusing on. Please see the documentation for more information:
When
heatmapis True (by default it’s True) , Grad-CAM heatmaps (http://openaccess.thecvf.com/content_ICCV_2017/papers/Selvaraju_Grad-CAM_Visual_Explanations_ICCV_2017_paper.pdf) are overlaid on each image.
I was going over the images in the pets dataset and realized that some of them are PNG files but have a JPG file extension. I do understand that Python would be able to imread both types of files, but it is a hassle to open the files in the OS. Is this done on purpose (except for the fact that an simpler regular expression can be used)?
For machine learning, data is split into three parts: the train set, the validation set or usually dev set, and the test set. The train set is used to train the model, so the model will be updated according to the loss on this data set, hence, train_loss. The dev set or validation set is used to see how well the model performs on data it has not seen before. This is used to prevent over-fitting. Hence, loss on this data set is your valid_loss. Finally, we want to compare our model’s performance with other models, so we have a test set that everybody uses for testing. This is like a benchmark for your model. The loss on this data set is the error_loss.
Thanks totally missed production section
So does it mean I need to pass a lot of pictures of same dog for the model to recognise the breed?
I suggest you watch the lectures - you train the model with whatever you expect it to be able to recognize.
1 Like
What is the homework for week1??
Hi, I’m really curious about how learn.lr_find() works. How does it calculate loss for a particular learning rate without running the full training using that learning rate? (I assume it does not, because if it does, then it would take much longer for the method to return its value).
lr_find() runs an epoch, while changing the learning rate for each batch. Also, if I understand correctly, lr_find() will stop early if the loss is increasing too high. So it could run an entire epoch with different learning rates for each batch, or it could stop early.
I would recommend reading Sylvain’s great blog post on the topic if you want to dig into the details.
Doubt: in the video at 1: 23: 50, picking a LR range…
At after 1e-4 on the horizontal axis… the Loss gets worse… for the resenet 34 model
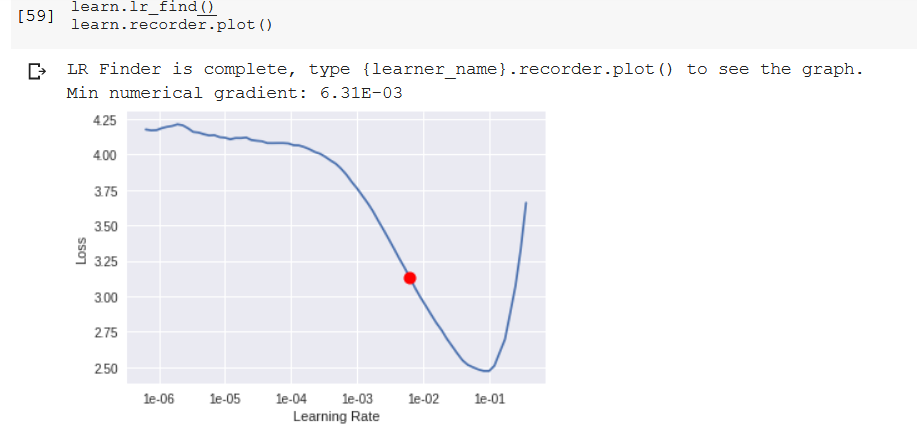
How do I apply a similar line of reasoning for arriving at the LR slice for the resnet 50 model…?
i.e :: learn.fit_one_cycle(3, max_lr=slice(1e-6,1e-4))
based on the LR graph- plot I got… as seen above…
Ah, thanks for your explanation. I’ll read the blog post.
Q about interp.plot_top_losses
It returns plots and how should the probability reported be interpreted? I assume it is the probability the model give the ground truth label, so most of them should be low.
Did you figure it out? Do we create test and validation sets automatically from the downloaded data and if yes, what is the size of validation set? 20%?
I run the model on my data several times, every time I get a different result, could it be because each time different files go into automatically created validation and test sets?
Anyone know how to swap out the default optimizer AdamW for others?
ok i guess this was explained in Lesson 2… around 25th minute…
Hi Kelvin,
You can give it a different optimizer by using the argument opt_func when creating your Learner.
See: https://docs.fast.ai/basic_train.html#Learner
Thanks.
Yijin
Thanks. The doc itself didn’t list the type of supported optimizer?
Learner can just use any of the PyTorch optimizers (e.g. Adam, SGD, RMSprop, etc.), using a wrapper to simplify modifications of parameters.
Thanks.
Yijin
2 Likes
Hi, I was wondering to know why when I get PosixPath from:
from pathlib import Path
xpath = Path(’/content’)
Does not have ls() method
but when I get from fastai.datapath4file(’/content’)
I have ls() method from it?
xxpath = datapath4file(’/content’)
print(xxpath.ls())
both of them are PosixPath