Hey thanks so much Daniel! There were definitely some mistakes there!!
I’ve updated the classifications and run again but its not really any better.
Maybe there is some other basic error I’m making?
Hey thanks so much Daniel! There were definitely some mistakes there!!
I’ve updated the classifications and run again but its not really any better.
Maybe there is some other basic error I’m making?
I’m having troubles understanding ImageDataBunch.from_folder(). The documentation reads:
from_folder(path:PathOrStr, train:PathOrStr='train', valid:PathOrStr='valid', valid_pct=None, classes:Collection[T_co]=None, **kwargs:Any) → ImageDataBunch
And lists as an example:
data = ImageDataBunch.from_folder(path, ds_tfms=tfms, size=24)
However, aside from path which was given, ds_tfms and size don’t even exist, so I’m having trouble understanding how they work and what they do. Could anyone explain this to me?
As explained here, this approach is to create a DataBunch object which you can use to train a classifier.
The ImageDataBunch.from_folder() is one approach to creating such an object, assuming that your data is organized in an Imagenet style like this:
data
| -- train
|-- category1
|-- category2
...
| -- valid
|-- category1
|-- category2
...
The ImageDataBunch.from_folder() takes some parameters among which:
Thank you for the answer @raimanu-ds, this solves the problem. However, in the while time, I also digged a bit into the source code (vision/data.py) and after a python refresher, I remembered about **kwargs.
I definitely think that the most useful **kwargs should be listed in the docs under the from_folder method.
I’m not sure about whether you’re making a basic error, but you should keep testing around a little. I had a project where the actual part that I wanted to classify was only 2-3% of the (very large) image, so I first did object detection and then classification (but I think there are methods to combine the two, just don’t know which). My challenge was that there were tiny defects in the 2-3% area, so I cropped it and then had a classification running on the cropped images.
One thing that might help is to somehow tell the network what area it should focus on (so give some kind of coordinates or bounding box / polygon to the network). I’m not entirely sure how to do that though. My friend Ting Ting wrote a paper where she supplied the network with a human attention data - maybe you can get some idea from that, too.
Anyway, I’m very curious how you’ll progress! Please keep me / us posted! I’m a big time photovoltaics nut - what are you using the project for?
I managed to get to around a 14% error rate. I removed the image transforms when preparing the image bunch (this seemed to help) and spending more time tuning the number of epochs and learning rate.
Then I just saw this posted: https://www.engineering.com/DesignerEdge/DesignerEdgeArticles/ArticleID/18348/How-Do-You-Count-Every-Solar-Panel-in-the-US-Machine-Learning-and-a-Billion-Satellite-Images.aspx. Article says “about 10 percent of the time, the system missed that an image had solar installations” so if that is state of the art maybe I’m not way out of the ballpark? Although their billion images is slightly more than my 100!
I’ll read their paper and keep playing around!
Good job! 

I’m curious to know what project you have in mind with your solar-roof identifier?
Awesome! I have spent the last few hours trying to translate the lesson to work on Windows.
It’s more just an interesting problem as a learning exercise for now. But being able to ‘survey’ properties for existing solar is useful as a sales prospecting tool for energy companies, and if you also can get hold of the meter data for a property you could do some fault detection … it looks like you have solar on the roof, but your energy usage isn’t consistent with a working solar system (looking at things like the relationship between energy usage and local solar irradiance for example).
Very interesting indeed!
I’ve found the Standford project website for DeepSolar and the GitHub repo and a dataset for the project are linked from there
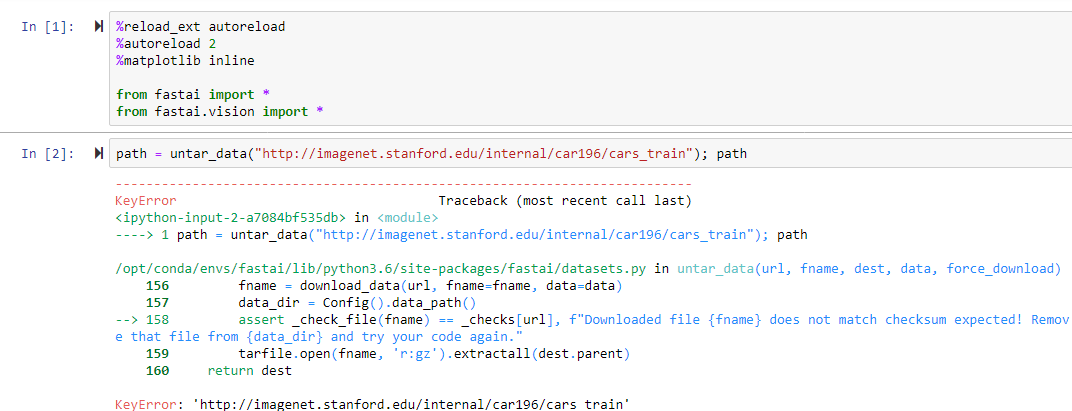
Hi everyone! I am trying to download a dataset using path = untar_data(‘http://imagenet.stanford.edu/internal/car196/cars_train’); path
but I am getting the following error:
KeyError Traceback (most recent call last)
in
----> 1 path = untar_data(‘http://imagenet.stanford.edu/internal/car196/cars_train’); path
/opt/conda/envs/fastai/lib/python3.6/site-packages/fastai/datasets.py in untar_data(url, fname, dest, data, force_download)
156 fname = download_data(url, fname=fname, data=data)
157 data_dir = Config().data_path()
–> 158 assert _check_file(fname) == _checks[url], f"Downloaded file {fname} does not match checksum expected! Remove that file from {data_dir} and try your code again."
159 tarfile.open(fname, ‘r:gz’).extractall(dest.parent)
160 return dest
KeyError: ‘http://imagenet.stanford.edu/internal/car196/cars_train’
I can see when it downloads the file and it is in the data folder with the extension .tgz but it seems it does not decompress it. Im I doing something wrong or it is just a problem with the dataset?
Thanks!
Hi raimanu-ds, did you solve the problem? Im having the same issue.
Thanks for the reply! Im also able to download the .tgz file but it gives me an error when decompressing it. Let me know if yours work.
yes, it unzipped automaticallyt too

Hello There,
I am fasi.ai beginner who just started the online course. I am trying to run "lesson1-pets" on AWS Deep learning AMI (Ubuntu) Version 21 on p2.xlarge instance. I keep getting “The kernel appears to have died. It will restart automatically.” when i try to run "create_cnn"
# https://github.com/fastai/course-v3/blob/master/nbs/dl1/lesson1-pets.ipynb
learn = create_cnn(data, models.resnet34, metrics=error_rate)
My conda list - https://gist.github.com/ndchandar/f2b18d3e62dd38dc6d51d8542e912338
I tried changing “bs” value and also instance types (p2.xlarge, p2.8xlarge) and CUDA 9/10 but keep getting the same error. Could you pls let me know what i am missing ?
Using pytorch-nightly fixed the problem.
Hi everyone!
I’ve got a problem with getting through first Lesson. The URLs.PETS cannot download on Kaggle kernels. The link https://s3.amazonaws.com/fast-ai-imageclas/oxford-iiit-pet does not contain any data. I can use different data set, but IMHO links from lib should be working.
Should we report it to fastai lib as an issue?
Furthermore, network connection does not work in Kaggle kernels by defatult, would be useful to add this to setup docs. Where could I report/contribute to to fix that?
Thanks again but not luck on this side… Tried writing your exact code and the same error pops up. I guess I will just go on without using a new dataset.
Thanks again!
Hello! Does anyone know whether learn.fit_one_cycle is addititive?
Does it hold that
learn.fit_one_cycle(a)
learn.fit_one_cycle(b)
is the same as
learn.fit_one_cycle(a+b)
?
number crunching seems this to be sort off the case, but then the error rates do not seem to go down monotonously… there seems to be a little jump at the beginning of each
learn.fit_one_cycle
?? anyone knows how this works?