Hi everyone, im new here. i have some background on on DL but all on tf, keras i see the first lesson and im really interesting on complete all the course. wich material u recommend to read to be up to date with fastai lib and Pytorch? only docs will be ok?
In another hand, any chance to be online assistant of part 2 of the course?
Hi,
I am reading train and test imagelists from pandas.dataframe and loading it into a databunch.
But, I want to get the dataset object for train and test sets. How can I do that?
You chose “1e-6 to 1e-4” in which the losses are between 4.00 to 4.25 and the variation is not much.i.e. losses seems to be unaffected by the learning rate in that range.
And when you use “1e-1” the losses rise exponentially from there.
Try using the optimum value “1e-02”
Hope it helps
Hi , when I log to the machine in for fast AI template, I should see a data directory among other directory (anaconda3 data downloads fastai), I do not see it, I don`t know why? looking for your help. Thank you
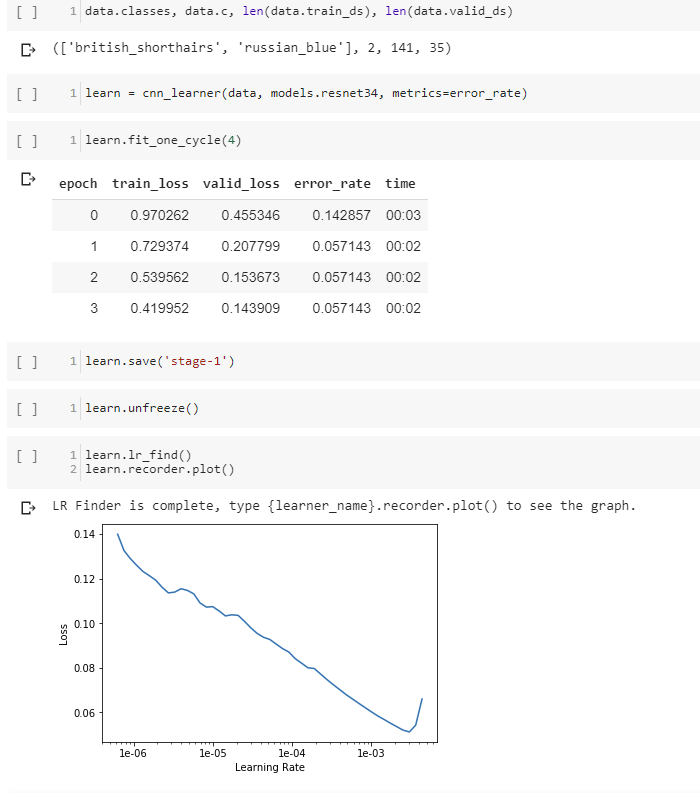
Hi all, new to DL here. I got some decent results from comparing 2 cat breeds, but unfreezing made everything worse. The lecture said to try and look at the plot and pick a low loss point so we can increase accuracy. My chart looks a bit different from the other ones I’ve seen after running learn.recorder.plot(). Can someone help me figure out how to get better results after unfreezing? Also, the lines aren’t the clearest, so is it okay to just eyeball where that dip is on my chart?
I’ve just finished week #1.
One question: Can we use single label for classification, in a boolean sense? Like in category or not in category?
What I’m trying to do as practice is to train a model with images of a single city and when given an image as an input, it should tell if the image is that city’s or not.
I have only rudimentary computer science knowledge so I apologize if this is a simple question, but I am stuck on untar_data(). Specifically, the first argument is (url:str,…). If I pass an external url to untar_data, I get an error. It seems that the example used in the course (“URLs.PETS”) is part of the class “URLs”, and when I call help, it provides a list of available datasets. Why can I not pass an external URL to untar_data? How do I modify an external URL (eg. CIFAR-10 [https://www.cs.toronto.edu/~kriz/cifar.html]) so that I can use it in the Jupyter notebook? I am getting an error that it is not a tar zip file (sorry I forget the exact errror).
Also, the paths for the pets dataset is ‘/home/ubuntu/.fastai/data/oxford-iiit-pet’. I have found this path on the terminal but cannot find it in the Salamander GUI directory. I am seeing “cifar-100.tgz.tgz” and cifar-10-python.tar.gz.tgz" in this directory, so it must have uploaded at some point when I entered the URL.
Finally, in the Image_Data_Bunch.from_name_re () method, why do we need to specify both path and fnames? Both seem to be path objects, and the fnames argument is just longer, with the file names. Does Image_Data_Bunch subtract path from fnames to determine the file name and apply the regular expression?
Sure! Let’s say your city is New York City. You’d have 2 labels: nyc and not_nyc. As far as the model is concerned, that’s no different than the labels dog and cat. In fact, you could find New Yorkers who’d say the difference between nyc and not_nyc is bigger than between cars and dogs.
Another ex: hotdog and not_hotdog, which was featured on an app on the TV show Silicon Valley.
Here’s an example of someone recreating it using fastai:
Thank you very much Anders, never thought of it this way, training non_city with images of different cities. I was more thinking in terms of not training non_city at all.
Beginner question: When I use the imageDataBunch method from folder, classes are numbered alphabetically (i.e. clas1 is 0 in the predictions, clas2 is 1 etc). How could I change this order? In my case (anomaly detection), I have 2 classes (‘good’ and ‘bad’) and I would like ‘bad’ to get index 1 and ‘good’ index 0 as it is usually the convention. Thanks a lot!
You’re welcome! I’m still very new at this, but I think one of the major pieces of doing deep learning or any machine learning is figuring out, how do I get turn my problem into something computers are good at doing?
It’s like cooking on an outdoor grill. Grills are great at cooking food that’s a certain size, like a burger. They’re not great at cooking small pieces of meat or vegetables — they’ll fall through the grill. That’s why people use skewers/kabobs: they use the skewer to “transform” several too-small pieces into one big enough piece, and now you can grill it.
Similarly, if a deep learning method needs more than 1 value, you change the way you’re defining your problem to give it 2 values.
I’m totally new at this so please forgive me if I’m asking obvious questions. I’ve gone through the first lesson a few times now and although I can shift+enter to run the code, I don’t feel like I know what I’m doing. I feel like I need an introductory course, maybe with some history of how deep learning works. That aside, I do have a specific question.
Regarding most_confused(), if the system is able to tell me which ones it got wrong, why didn’t it just adjust and get them right? And how does it know which ones it got wrong?
Really sorry if this is obvious but I don’t see this explained anywhere in the first lesson.
Hi Ted, I’m a beginner as well but I’ll try to explain things the best I can.
most_confused() gives us the instances it got wrong from the validation set. The model can not adjust and get them right, because it does not “read” (train) from the validation set. Validation set is kept aside to determine how good our model is doing.
Regarding how it knows which ones are wrong: Items in the validation set actually have their label. Our model first predicts what the item label is (with a certain confidence value) then looks at the actual label and determines whether it predicted right or wrong.
To sum it up, we have two sets of data :
Training set
Validation set
The model first looks at the training set items with its labels. Then predicts the labels for items in the validation set. Then checks whether it predicted correctly and how wrong (or right) it was in predicting.

 -I might use it some day-
-I might use it some day-