Not quite - if you go back and listen to the lesson at this point, you’ll here that the first one was simply to show that a poor learning rate choice means I needed to find a better one.
1 Like
We’re not looking for the lowest error rate, but the strongest negative slope. So a bit less that 1e-5.
4 Likes
But MaxPool layers don’t retain the relative positions {what I’ve read on internet, I’m not sure though}. This is addressed in Capsule Networks. These networks work more like inverse graphics. This video covers the core content of the paper. This is a very recent area of research.
@jeremy what are your thoughts on Capsule Networks? Are they really better than ConvNets and is it worth learning them?
My understanding was when we unfreeze and fit we are trying to see if we have choosen good pretrained model or not and with this if we can go ahead and fine tune further to get the most out of this model.
Thanks for correcting me @jeremy but now I wonder is there any guideline for the model selection for eg. we have resnet34, 50, 101 etc how to choose one and when.
There’s actually a thread for that:
5 Likes
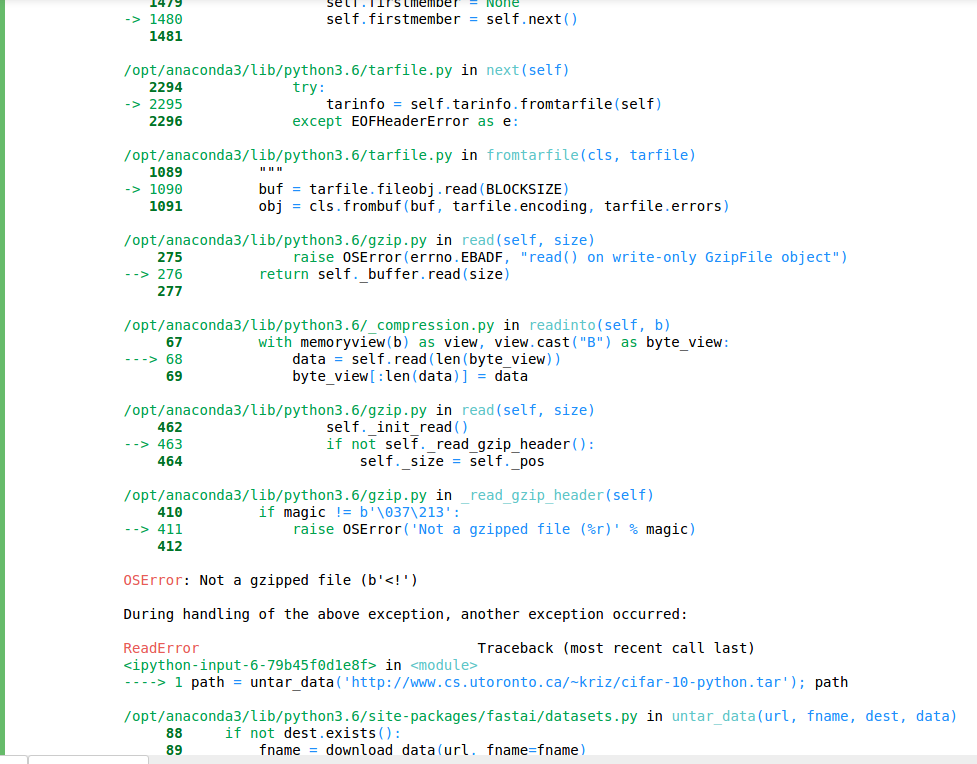
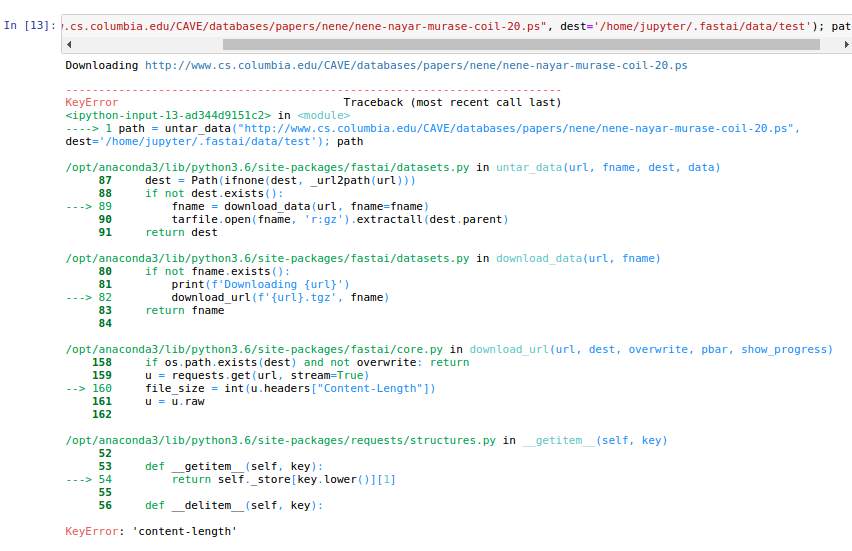
@rameshsingh - I still see the same error even after avoiding the extension while using untar_data function.
path = untar_data(‘http://www.cs.utoronto.ca/~kriz/cifar-10-python’); path
I have been digging inside the fastai library to find out where the loss function is defined for the learner in Lesson 1. The optimizer is by default “Adam” and is defined in the class Learner which is inherited by ConvLearner. But I am not able to find where the loss function which happens to be F.cross_entropy is defined. Any help is appreciated.
Thanks—maybe there is nothing better to do than what you and Michael suggested. I was just hoping there is a way to reduce the human effort. I guess in addition to checking the validation set, one could train and validate on different subsets and gradually clear up the mislabeled data on the whole dataset. I’d love it if there was any additional automation to reduce the effort in such tasks.
1 Like
Hi,
I got this resolved. The issue is because of the extension .tar.gz. untar_data function is not treating tar.gz as a gzip file. But actually .tar.gz extension means the same as .tgz. I managed to get the dataset URL with .tgz extension and using this URL excluding the extension solved my issue.
@rameshsingh - Thank you so much 
1 Like
Hi all,
Over the weekend, I have tried training a model with a different dataset and here I am to share my results
I have taken the CIFAR-10 dataset inorder to train my model.
The CIFAR-10 dataset consists of 60000 images of 10 classes, each class having 6000 images
There is a research paper(Convolutional Deep Belief Networks on CIFAR-10) which claimed that they achieved an error rate of 21.1% on training a model with CIFAR-10 dataset in 2010
Now by using fastai library as taught in Lesson1, I could achieve an error rate of 5% upon training a model with CIFAR-10 dataset
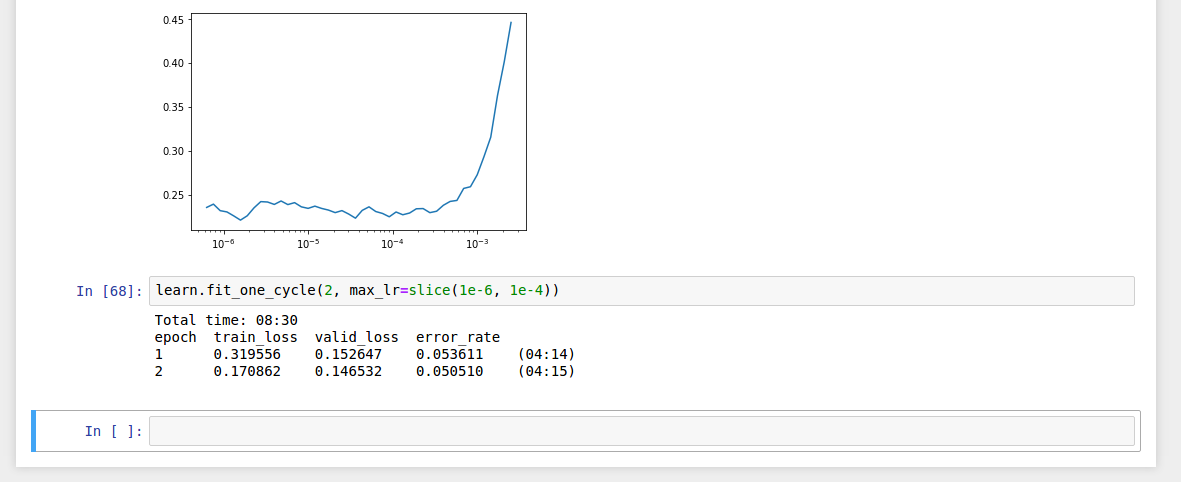
Happy to have tried this 
1 Like
@marcmuc Nice! You tagged the wrong guy though  Its @raghavab1992
Its @raghavab1992
Also, I still prefer aomething like the below as its simpler, but is there any disadvantage of using this? (speed etc)
num_train=len(data.train_ds)
trainClasses = []
for i in range(num_train):
trainClasses.append(data.train_ds.ds[i][1])
from collections import Counter
Counter(trainClasses)
2 Likes

@jeremy - sorry to bother you, but I don’t know how to get email notifications and I suspect the same thing is happening to others without them knowing. I have it set to Watching in several places but still don’t get email notifications. Am I missing something obvious? thanks
Sorry I don’t get it can you be explain a bit more?
It would certainly be useful to have some automation but would need human intervention - maybe iterate through the highest loss images with a Skip, Delete, Move option for each. It beats scrolling through the images - but haven’t had time to write it.
1 Like
Thanks for pointing that out, I corrected the tag in my post.
Well, there is nothing wrong with your code, but the disadvantage will be the speed. You may not notice it very much on small datasets, but if you have something with e.g. millions of examples this will mean a difference of waiting a few seconds vs. waiting a few minutes. The reason for that is that pandas uses optimized c code in the background and vectorized implementations, whereas your version uses a for loop in python which is much slower. Also, if you want to use a loop for some reason, your code would be more efficient if you used python set datatype instead of list for trainClasses (and len(trainClasses) instead of counter). Or a dict with key=classes and value=counters inside the loop.