If you have used existing fastai image from market place then probably this is not required.
fastai uses conda for installing libs.
You need to install version 1.0.14:
conda install -c fastai fastai
1 Like
Do you have the latest fastai library (1.0.14)?
No. A git pull just updates the your local folder with the repository’s contents. We need to update the library which is a package installed in Anaconda. Even if you have the latest fastai repository in your computer, you may have an old version library installed. You either need to run the command I suggested if you are using Anaconda or if using pip:
pip install fastai --upgrade
4 Likes
I am currently working on a Happy whale dataset. This challenge gives us training set with 3000+ labels of whales. Task is to make prediction for test set. After looking at the submission file .csv I can see that this might be multi-class prediction(I am not sure what its called multi-class or multi-label) i.e. each test image might have multiple class prediction probabilities. How can I achieve this task? I know there are some changes is to be made in the final output layer (adding non-linear functions) like using softmax or sigmoid but I am not sure which one to use. After getting these probabilities we need to find like top X% of those and get’s those top X% labels and assign that to given input test Image. Is my approach correct towards this problem?
It’s basically a Multi-Label Classification… @ keyurparalkar
Check this from past versions Kaggle's Whale Competition (might help)
1 Like
Thank you it worked. But maybe we need to change it in the http://course-v3.fast.ai/update_gcp.html the command to :
sudo: sudo /opt/anaconda3/bin/conda install -c fastai fastai
because in there is still says : “sudo /opt/anaconda3/bin/conda update fastai”. SO when you follow the steps mentioned we do a git pull and then the update command which says all requirements already satisfied. (meaning it doesn’t update the repo). Please check this once
Changing the “update fastai” to install -c fastai fastai worked for me.
1 Like
You can simply do learn.load(‘my-model’) and use it for prediction.
Unfreezing the models allows all the layers to be trained.
On a machine with 1060 Ti 6 GB GPU , the unfreezed model trains in under a minute and a half for 1 epoch while the freezed model takes a less than a minute.
Shouldn’t the un-freezed model taken a much longer time given it has many more trainable parameters.
To make an inference you need to call learn.eval() first (this removes the dropout) and then learn.predict().
1 Like
To quote Jeremy, softmax likes to to pick just one thing… which makes it a good choice for multi-class classification. Sigmoid one the other hand wants to know where everything is between -1 to +1.
1 Like
I am get KeyError: 'content-length' when I try different datasets listed in the Image Classification section at the the link below:
Workflow
- Copy path from the download link.
- Use this path in
untar_data
Example
path = untar_data('https://s3.amazonaws.com/fast-ai-imageclas/mnist_png.tgz')
Downloading https://s3.amazonaws.com/fast-ai-imageclas/mnist_png.tgz
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-96-f7e93772cc8e> in <module>
----> 1 path = untar_data('https://s3.amazonaws.com/fast-ai-imageclas/mnist_png.tgz')
2 path
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastai/datasets.py in untar_data(url, fname, dest)
107 "Download `url` if doesn't exist to `fname` and un-tgz to folder `dest`"
108 dest = Path(ifnone(dest, _url2path(url)))
--> 109 fname = download_data(url, fname=fname)
110 if not dest.exists(): tarfile.open(fname, 'r:gz').extractall(dest.parent)
111 return dest
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastai/datasets.py in download_data(url, fname)
101 if not fname.exists():
102 print(f'Downloading {url}')
--> 103 download_url(f'{url}.tgz', fname)
104 return fname
105
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastai/core.py in download_url(url, dest, overwrite)
155 if os.path.exists(dest) and not overwrite: return
156 u = requests.get(url, stream=True)
--> 157 file_size = int(u.headers["Content-Length"])
158 u = u.raw
159
~/anaconda3/envs/fastai/lib/python3.7/site-packages/requests/structures.py in __getitem__(self, key)
50
51 def __getitem__(self, key):
---> 52 return self._store[key.lower()][1]
53
54 def __delitem__(self, key):
KeyError: 'content-length'
Check this out link which meant use this untar_data(URLs.MNIST_SAMPLE)
MNIST_SAMPLE
in short, the lib uses MNIST_SAMPLE , which has a different format.
1 Like
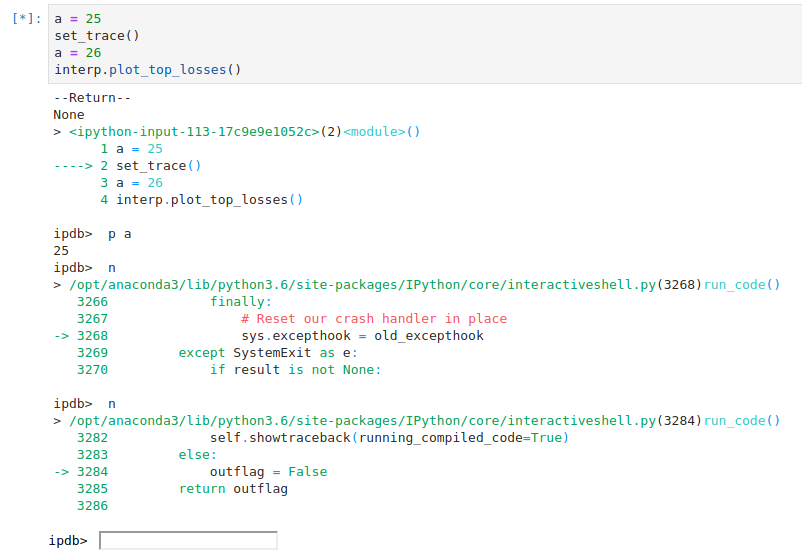
IPython Debugger gets lost in internal code after set_trace
After pressing n(ext) it just keeps going down the rabbit hole of its internal functions and I cannot get past set_trace().
you need to remove the tgz at the end of string to not get that error.
use this —> untar_data(‘https://s3.amazonaws.com/fast-ai-imageclas/mnist_png’)
1 Like
Thanks but that wasn’t really what I meant. I wanted to move my trained model to another CPU only machine to perform predictions. The learn.load method can only be called on an instantiated learner object. In order to instantiate a learner I have to provide it with a DataBunch and an architecture as a minimum. I have hacked around this with the following:
import torch
from fastai.vision import get_image_files, ImageDataBunch, get_transforms, ConvLearner, models, open_image
from pathlib import PosixPath
path_data = PosixPath('/Users/jeremyblythe/Downloads/dummy')
fnames = get_image_files(path_data)
pat = r'/([^/]+)_\d+.jpg$'
data = ImageDataBunch.from_name_re(path_data, fnames, pat, ds_tfms=get_transforms(), size=224, bs=10, flip_lr=False)
learn = ConvLearner(data, models.resnet34)
learn.model.load_state_dict(torch.load('/Users/jeremyblythe/Downloads/stage-2.pth', map_location='cpu'))
img = open_image('/Users/jeremyblythe/Downloads/test-A_29.jpg')
p = img.predict(learn)
data.classes = ['B', 'A', 'E', 'Y']
print(data.classes[p.argmax()])
My dummy directory contains one sample of each class. Note that when loading a model trained on a GPU machine into a CPU machine you cannot use learn.load as map_location='cpu' is required. Also note that you need to restore data.classes to the match the order from the original training.
The above hack has allowed me to train on a p2.xlarge in AWS and then bring the model back to my Mac to run predictions.
I think I saw a couple other people asking how to do something like this, @matwong and @danielegaliffa (questions G,H perhaps?) - I’m not saying this is a nice way to do it but it seems to work.
Wondering if anyone has a better, less hacky, way to do this?
1 Like
Can anyone tell me how to download a dataset from the UCI ML repository and use it? I have created a topic for it: How to download a dataset from a URL?
Any help is appreciated.
How do I get the number of images in each class, from the ImageDataBunch object.
Many thanks for the reminder - fixed now.
1 Like