Sure,
image_extensions = set(k for k,v in mimetypes.types_map.items() if v.startswith('image/'))
it uses a nifty built-in python library called mimetypes. It can be found here: https://docs.python.org/3/library/mimetypes.html
It uses the mimetypes.types_map function to get this output:
{'.a': 'application/octet-stream',
'.ai': 'application/postscript',
'.aif': 'audio/x-aiff',
'.aifc': 'audio/x-aiff',
'.aiff': 'audio/x-aiff',
'.au': 'audio/basic',
'.avi': 'video/x-msvideo',
'.bat': 'text/plain',
'.bcpio': 'application/x-bcpio',
'.bin': 'application/octet-stream',
'.bmp': 'image/x-ms-bmp',
'.c': 'text/plain',
'.cdf': 'application/x-netcdf',
'.cpio': 'application/x-cpio',
'.csh': 'application/x-csh',
'.css': 'text/css',
'.csv': 'text/csv',
'.dll': 'application/octet-stream',
'.doc': 'application/msword',
'.dot': 'application/msword',
'.dvi': 'application/x-dvi',
'.eml': 'message/rfc822',
'.eps': 'application/postscript',
'.etx': 'text/x-setext',
'.exe': 'application/octet-stream',
'.gif': 'image/gif',
'.gtar': 'application/x-gtar',
'.h': 'text/plain',
'.hdf': 'application/x-hdf',
'.htm': 'text/html',
'.html': 'text/html',
'.ico': 'image/vnd.microsoft.icon',
'.ief': 'image/ief',
'.jpe': 'image/jpeg',
'.jpeg': 'image/jpeg',
'.jpg': 'image/jpeg',
'.js': 'application/javascript',
'.json': 'application/json',
'.ksh': 'text/plain',
'.latex': 'application/x-latex',
'.m1v': 'video/mpeg',
'.m3u': 'application/vnd.apple.mpegurl',
'.m3u8': 'application/vnd.apple.mpegurl',
'.man': 'application/x-troff-man',
'.me': 'application/x-troff-me',
'.mht': 'message/rfc822',
'.mhtml': 'message/rfc822',
'.mif': 'application/x-mif',
'.mov': 'video/quicktime',
'.movie': 'video/x-sgi-movie',
'.mp2': 'audio/mpeg',
'.mp3': 'audio/mpeg',
'.mp4': 'video/mp4',
'.mpa': 'video/mpeg',
'.mpe': 'video/mpeg',
'.mpeg': 'video/mpeg',
'.mpg': 'video/mpeg',
'.ms': 'application/x-troff-ms',
'.nc': 'application/x-netcdf',
'.nws': 'message/rfc822',
'.o': 'application/octet-stream',
'.obj': 'application/octet-stream',
'.oda': 'application/oda',
'.p12': 'application/x-pkcs12',
'.p7c': 'application/pkcs7-mime',
'.pbm': 'image/x-portable-bitmap',
'.pdf': 'application/pdf',
'.pfx': 'application/x-pkcs12',
'.pgm': 'image/x-portable-graymap',
'.pl': 'text/plain',
'.png': 'image/png',
'.pnm': 'image/x-portable-anymap',
'.pot': 'application/vnd.ms-powerpoint',
'.ppa': 'application/vnd.ms-powerpoint',
'.ppm': 'image/x-portable-pixmap',
'.pps': 'application/vnd.ms-powerpoint',
'.ppt': 'application/vnd.ms-powerpoint',
'.ps': 'application/postscript',
'.pwz': 'application/vnd.ms-powerpoint',
'.py': 'text/x-python',
'.pyc': 'application/x-python-code',
'.pyo': 'application/x-python-code',
'.qt': 'video/quicktime',
'.ra': 'audio/x-pn-realaudio',
'.ram': 'application/x-pn-realaudio',
'.ras': 'image/x-cmu-raster',
'.rdf': 'application/xml',
'.rgb': 'image/x-rgb',
'.roff': 'application/x-troff',
'.rtx': 'text/richtext',
'.sgm': 'text/x-sgml',
'.sgml': 'text/x-sgml',
'.sh': 'application/x-sh',
'.shar': 'application/x-shar',
'.snd': 'audio/basic',
'.so': 'application/octet-stream',
'.src': 'application/x-wais-source',
'.sv4cpio': 'application/x-sv4cpio',
'.sv4crc': 'application/x-sv4crc',
'.svg': 'image/svg+xml',
'.swf': 'application/x-shockwave-flash',
'.t': 'application/x-troff',
'.tar': 'application/x-tar',
'.tcl': 'application/x-tcl',
'.tex': 'application/x-tex',
'.texi': 'application/x-texinfo',
'.texinfo': 'application/x-texinfo',
'.tif': 'image/tiff',
'.tiff': 'image/tiff',
'.tr': 'application/x-troff',
'.tsv': 'text/tab-separated-values',
'.txt': 'text/plain',
'.ustar': 'application/x-ustar',
'.vcf': 'text/x-vcard',
'.wav': 'audio/x-wav',
'.webm': 'video/webm',
'.wiz': 'application/msword',
'.wsdl': 'application/xml',
'.xbm': 'image/x-xbitmap',
'.xlb': 'application/vnd.ms-excel',
'.xls': 'application/vnd.ms-excel',
'.xml': 'text/xml',
'.xpdl': 'application/xml',
'.xpm': 'image/x-xpixmap',
'.xsl': 'application/xml',
'.xwd': 'image/x-xwindowdump',
'.zip': 'application/zip'}
Then, it loops through each of these (k = extension, v = extension type) and checks to see if the extension type (v) starts with image (image/). If it does, it adds the extension to a set.
This is what is stored in the image_extensions variable.

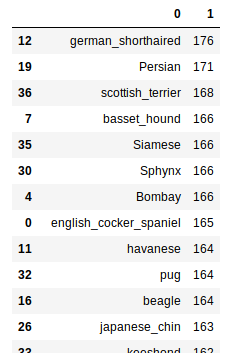
 . On looking at the images (show_batch), I found some irrelevant images. How do I remove irrelevant images from my dataset?
. On looking at the images (show_batch), I found some irrelevant images. How do I remove irrelevant images from my dataset?