1 - As long as the classifier can get a sufficient number of distinct images per class to work upon, it should usually work fine. In general, more the images, better the accuracy of the results.
2 - Depends on the image classifier. Some can work with multiple types of images. The classifier software ultimately works with arrays of pixels irrespective of the image type. For the current FastAI version, the code will need to be deep dived into to check the same as regards it’s ability to handle multiple image types.
Hi! I have been trying the fastai library on a dataset from kaggle competition named Plant Seedlings Classification. I able to train the model using fastai library using resnet34 as shown by Jeremy. My question is how do I get the prediction for test data?
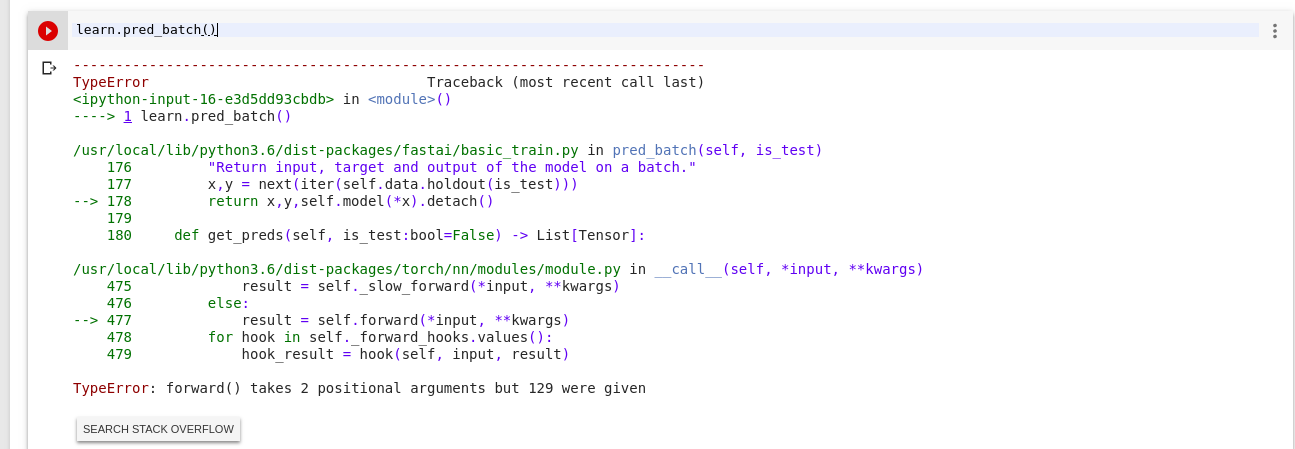
@_Ali, I think you can use learn.predict_array(), Now seems like we also have batch predictions (learn.pred_batch()). just check the documents for the arguments.
I faced same issue while I was working on my dataset of sitar and guitar classification. I just had 100 images per class. This problem occurs due to small number of images per class. I don’t know the exact reason of this problem. But increasing the cycles i.e. learn.fit_one_cycle(1) changing the value from 1 to greater than 2 might help you to solve this problem.
The above error is obviously being caused by denominator value of 0 in one of the metrics calculation code. This could happen when the number of images are too small in a particular class and the classifier may not be able to get a value for one of the categories that it is expecting - e.g. the number of predictions that it has made for a class.
As you and others have rightly inferred, increase the number of images ensuring that each class of images is represented in the training data.
thank you for the reply. I tried and it is throwing an error, which i shared below.
The Test data is in folder named as “test” and I have specified test data set using the code below. Any help is appreciated.
Is there any example available regarding using Custom head on top of ResNet50 with ConvLearner. It’s not available in docs. I have 10M (approx) images, and Resnet has reached saturation. I wanted to increase number of parameters. Also as far as docs says, there’s support for darknet and wide resnet including Unet which may not serve the purpose here.
interp = ClassificationInterpretation.from_learner(learn)
# show most confused images (with min cut off = 2)
interp.most_confused(min_val=2)
# or plot the full confusion matrix:
interp.plot_confusion_matrix(figsize=(17,12), dpi=60)
It seems that you put too much data on your GPU RAM.
Try to check with the bash command nvidia-smi (or I like to use gpustat) before and after the operation causing the CUDA memory error if this is the case.
You can call it directly from your jupyter notebook with !nvidia-smi (with “!” you can run bash commands in a jupyter notebook).
Also restart the notebook kernel (shortcut Esc+00) and if this does not help your entire system.
If it is the case, try decreasing the bs and/or the image size.