Everytime I run the code from start I’m getting different answers.(Note :I’m using Co-lab)
That sounds normal, could be because of shuffling of the data set for example, or the randomness in your transforms that you’re applying. You didn’t specify what exactly “different” means, but unless you’re getting wildly varying model performance, that sounds about normal.
and I’m resetting the runtime everytime i start
I don’t think that’s necessary, unless you’re constantly getting CUDA Out Of Memory errors?
Why we are doing 4 epoch while freezing and 2 epochs after unfreezing it??Why don’t we just unfreeze the model in the start and do some 3-4 epochs.
The idea is that when you’re using a pre-trained model, and you are using the pre-trained model for a similar task, we don’t need to modify those pre-trained weights a whole lot. Remember, using pre-trained models essentially means that all you did is modify the last layer. Experimentation has shown that it’s usually best to first only train the last layer, as it has a random initialisation, and leave the rest of the model intact. This helps with faster convergence. Once the new layer “has gotten used” to predicting these images, it can be trained together with the earlier layers. It’s quite an intuitive approach. If you’re still having trouble grasping it, look up a bit more on differential learning rates and transfer learning.
How many images for each class do I need in general??
Really depends on how easy it is to distinguish between the classes that you are trying to predict. If you are trying to distinguish between red cars and blue cars, you probably need very few (50 of each?), while if you’re trying to distinguish between identical twins, you’ll need far more. Also depends on if you’re using pre-trained models. All in all, if the task is relatively straight forward, I think there’s fastai students that built models with as little as 50-75 images per class (Jeremy covers this at the start of Lesson 2 I think). It’s hard to generalise here though.
When I was running the given Lesson-2 notebook the Error rate was constant for 2,3,4 epochs and I dont understand why??
That really depends on context, we’d need to see a bit more of your code to understand what you were doing. It’s possible the model just found a local minimum and couldn’t “learn” further (at the current learning rate).
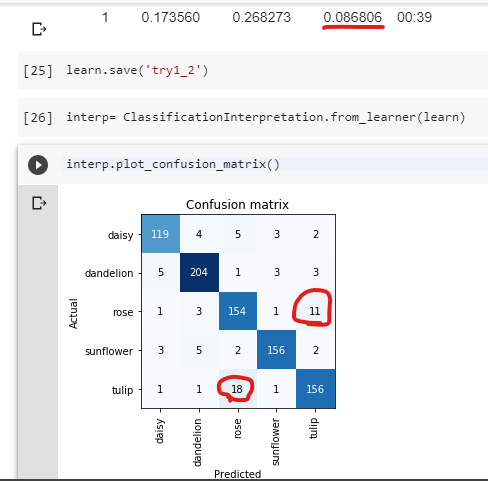
its having problem identifying between Tulips and Roses. How do I solve this problem?
I don’t entirely agree with your assessment. Misclassifying 11 tulips while your average is around 3 misclassifications sounds still on the low side of things. I agree that its more confused than usual, but not to a dysfunctional level. Have you tried checking the “most confused images” to get a feeling for why it’s misclassifying? Jeremy shows how to do this in Lesson 1 or 2 as well. Before diving into “fixing” this misclassification problem, first try to understand why the machine is getting this wrong.
Generally speaking, I’d argue quite simply more data is likely to help, so it learns to distinguish the features better. Alternatively, have you tried Test Time Augmentation? That might be an option too.
and Whats the Max accuracy I can try to get?
Take a look at the other kernels to get a feeling for what the current best score is of others playing around. I think around 90% is a good start, but I’m sure you could squeeze out a bit more with some tricks.
After completing first two lessons I tried to implement the same on similar data set ,what should I do next??
I’ve read quite a few threads on “how to fastai” and also given my own experience, I would argue the most important is to continue watching the lessons. Most people watch the whole class 2-3 times. First time is more of a global pass, second time they start to experiment, 3rd time is to really flesh out some details. So my advice would be to continue the lessons, and just experiment a bit when you come across something you think is cool.