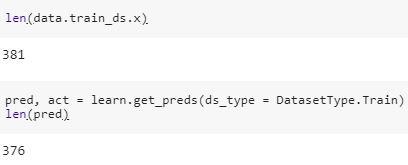
When doing image classification, I have 381 training images and I want to get predictions for these 381 images. But I am getting predictions only for 376 images.
Is anyone else facing this issue?
Why am I getting predictions on a randomly selected subset of my training data?
Is your batch size larger than 5? If yes, you probably have set up the dataloader in a such a way that only full batches are used and the remaining images are skipped.
There is no easy way to do it. If you have a look in create function of the databunch in fastai/basic_data.py you see this line:
dls = [DataLoader(d, b, shuffle=s, drop_last=s, num_workers=num_workers, **dl_kwargs) for d,b,s in zip(datasets, (bs,val_bs,val_bs,val_bs), (True,False,False,False)) if d is not None]
drop_last defines if you drop the last images. If you override this function with your own you could change the behaviour. But pay attention. Depending on your loss function, the not full batch could screw a bit with your training. As you see the validation and test set dont drop the not complete batch. perhaps this would be the easiest for you to use.
There is actually an easy way to do it: data.train_dl = data.train_dl.new(drop_last=False)
Note that you shouldn’t train in this configuration as it can cause problems with batchnorm layers.