I often see that for vision models too, FYI.
AFAICT that won’t help our classifier though, will it?
No, it’s designed to help guess the next word by using the previous couples of (hidden state,target), whereas the classifier only uses the hidden state that reflects the general sense of the sentence.
But you can brag that you have a better perplexity for free 
5 Likes
As promised, here is my blog post about the cache pointer. And there is a notebook for the full implementation.
It made me go down from 74 to 54 in perplexity so you can see the benefit (almost at the 52 from Stephen Merity but those last two points are hard to win!)
7 Likes
How many epochs did you run, and how many did smerity do?
120-150 vs 750+? 
It’s 750 for the training and I don’t know how much epochs their finetuning step takes since it stops by itself at some point depending on how it goes.
4 Likes
Thanks so much! Great stuff.
1 Like
In your step 3, how do you know zh_yue refers to Cantonese? Asking because I am looking for the Bengali language. My intuition is bnwiki is what I am looking for but how will I verify?
The Wiki page stated that.
Hey Guys… So finally I got success in training my Sanskrit LM . But the results are suspicious.
I collected nearly 5000 text docs that contained a total 8M Words with 800K unique words. I created a vocab of 100k . And started training the NN and I got the following results…
While Learner.fit…
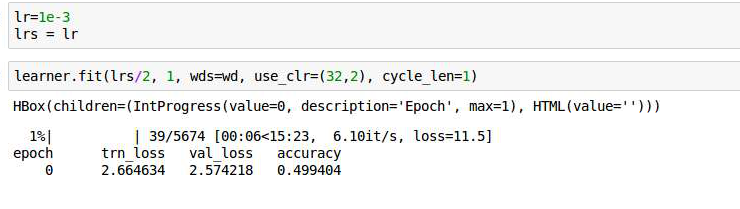
And while training…
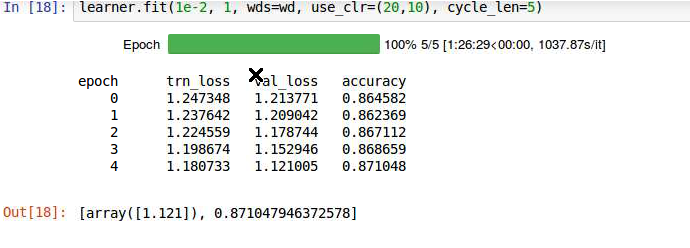
As u can see with just 5 epochs I got val_loss 1.2 on AWS P3.2xlarge
The corresponding Loss Plot is…
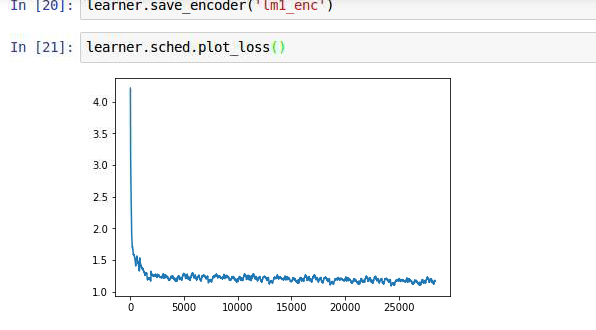
Also I tried with a little less than 20% of the data on google colab and STILL got this…
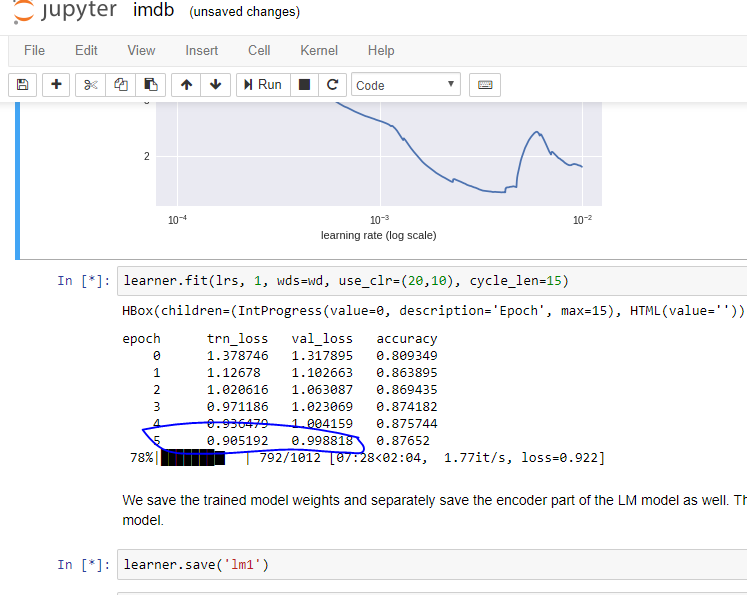
I am not understanding if my model (Actually Jeremy’s  ) is too good or am I doing something wrong…??
) is too good or am I doing something wrong…??
2 Likes
Is it possible some sentences are duplicated between train and validation?
What do you use to visualize core utilization? It looks very neat.
I finally got classification working using Sentencepiece in Chinese (will write a post about how to prepare data using Sentencepiece soon). I pre-trained the LM using a large corpus for a few days, used it as the backbone for the LM with classification data, trained the LM and the classifier for 1 epoch each to verify that the pipeline works. Since the classification model accuracy depends on the LM using classification data, what I’d like to know is, when is the LM “good enough” so I can switch to training on classification data?
Here are the results from the 3 models:
- The LM trained using a huge corpus (vocab = 32k capped by Sentencepiece, and ~200M tokens in total). I used the 1cycle option with clipping at 0.2 from @sgugger following the notebook here
Model
drops = np.array([0.25, 0.1, 0.2, 0.02, 0.15])*0.2
learner.fit_opt_sched(phases_1cycle(3, 1e-2, 10, 10, 0.95, 0.85),
best_save_name='best_sp_lm4_cycle1_20')
learner.clip = 0.2
Results (from the latest run)
`['2018-04-26 02:37:58.717671', 'epoch:', 0, ['trn_loss: ', 4.0965665464815615], 'val_loss: ', [array([ 4.03097]), 0.32691263348902139]]`
`['2018-04-26 04:53:57.105822', 'epoch:', 1, ['trn_loss: ', 3.986645947752499], 'val_loss: ', [array([ 4.03117]), 0.32691436419663644]]`
`['2018-04-26 07:09:59.895321', 'epoch:', 2, ['trn_loss: ', 3.9831622353315606], 'val_loss: ', [array([ 4.03083]), 0.32694404180923314]]`
`['2018-04-26 09:25:33.267159', 'epoch:', 3, ['trn_loss: ', 3.979517540932756], 'val_loss: ', [array([ 4.03075]), 0.32693607674602271]]`
`['2018-04-26 11:41:16.530276', 'epoch:', 4, ['trn_loss: ', 3.9849646963995706], 'val_loss: ', [array([ 4.03058]), 0.32693701100563866]]`
`['2018-04-26 13:57:01.262148', 'epoch:', 5, ['trn_loss: ', 3.979451022631513], 'val_loss: ', [array([ 4.03024]), 0.32696302014829798]]`
`['2018-04-26 16:12:56.123369', 'epoch:', 6, ['trn_loss: ', 3.979207381438585], 'val_loss: ', [array([ 4.03005]), 0.3269731315360131]]`
...
`['2018-04-27 08:06:02.427426', 'epoch:', 13, ['trn_loss: ', 3.97865690882087], 'val_loss: ', [array([ 4.02693]), 0.32713445760270948]]`
`['2018-04-27 10:22:14.637204', 'epoch:', 14, ['trn_loss: ', 3.9828539267643315], 'val_loss: ', [array([ 4.02626]), 0.327176959471564]]`
`['2018-04-27 12:38:37.941363', 'epoch:', 15, ['trn_loss: ', 4.058479350205298], 'val_loss: ', [array([ 4.02516]), 0.32722220211494046]]`
`['2018-04-27 14:54:27.116577', 'epoch:', 16, ['trn_loss: ', 3.9871506279462103], 'val_loss: ', [array([ 4.0252]), 0.32726447115032348]]`
`['2018-04-27 17:10:44.672298', 'epoch:', 17, ['trn_loss: ', 3.973794774878008], 'val_loss: ', [array([ 4.02479]), 0.32729853477216653]]`
- The LM on classification data
Model
drops = np.array([0.25, 0.1, 0.2, 0.02, 0.15])*0.2
learner.fit_opt_sched(
phases_1cycle(1, 5e-3, 10, 33, 0.95, 0.85))
learner.clip = 0.25
Results
epoch trn_loss val_loss accuracy
0 5.719708 5.533391 0.202317
- The classifier
Model
learn.fit_opt_sched(
phases_1cycle(1, 5e-3, 10, 33, 0.95, 0.85),
best_save_name='best_clf1_1cycle_cycle_1')
Results
epoch trn_loss val_loss accuracy
0 1.34154 1.101967 0.681474
The results can definitely be improved if I train longer. Each epoch takes 40min-1hr in each model on my GTX 1070, I’m leaving my model 2 running for a while and it looks like this:
epoch trn_loss val_loss accuracy
2 5.473969 5.451009 0.208819
3 5.433172 5.442846 0.209293
4 5.388279 5.43509 0.209702
5 5.457648 5.427986 0.210098
6 5.436401 5.421661 0.210445
8 5.449265 5.412729 0.21103
I know the loss and accuracy may be language specific, and there isn’t much data on Chinese that I can refer to. From the rate the current training is going at, it may take me a while to reach even 30% in the lecture notes!
Any feedback is appreciated 
PS: The classification benchmark I’m looking at is here
4 Likes
It’s a tool called htop, highly recommend it!
2 Likes
Awesome. Thank you 
That looks pretty good, although you’re under-fitting a bit. Generally best results on LM are when the trn loss is much less than the val loss. Try reducing dropout (you can do so, and then load your existing weights and continue training from there).
These losses are very high and the accuracy is very low. Is this corpus very non-standard in some way? You should normally get better loss and accuracy for the LM on your target corpus. Are you sure you’re importing the pre-trained weights and updating the vocab ids correctly?
The classifier accuracy seems quite a bit worse than the benchmarks - I’m guessing because there’s a problem with your target corpus LM training.
2 Likes
Thanks for the prompt reply Jeremy!
I will further reduce the dropout and see how much it improves. The dropouts went from *0.7 down to *0.2, but I’ll try 0.05 this time.
Is this corpus very non-standard in some way? You should normally get better loss and accuracy for the LM on your target corpus. Are you sure you’re importing the pre-trained weights and updating the vocab ids correctly?
The target corpus comes from the same source. The original corpus had 836k articles, and I used StratifiedShuffleSplit from sklearn to separate the data into train and val, then picked the first 500k in train and 50k in val for the pre-trained LM. Then I used 500k-550k in train and 50k-55k in val as the target corpus for classification, and I can double check the label distribution and see whether the data was truly shuffled. The only difference I recall is that I didn’t segment the text using bos:eos tokens from Sentencepiece in the pre-trained LM (I thought it was unnecessary), but I did use them in target corpus to train the LM (I think I’m being inconsistent here), and I used them again for classification. I see in the lecture notes that the bos:eos tokens were used in target LM and classification, but it was unclear whether they were used in the pre-trained LM.
Would that be a problem? Should I remove the bos:eos tokens in the target corpus LM, and continue with bos:eos in classification? Or should I add these tokens in the pre-trained LM and retrain the whole thing?
I think the pre-trained weights and vocab ids were imported correctly based on
wgts['0.encoder.weight'].shape == torch.Size([32000, 400])
This is the dimensions from the pre-trained weights.
len(itos2) == 32000, where itos2 is the vocab from the pre-trained LM.
new_w.shape == (33250, 400)
33250 is the vocab size of the target corpus.
I know this is probably not enough. What’s a better way to test it? So far I can only think of manually checking a few tokens that exist only in the target corpus.
With only 1 epoch of training using a crappy target LM, I’m not too surprised the classification wasn’t even close. Still plenty of hope!
1 Like
That all sounds fine - my guess is you have a bug in how you’re using the vocab or embeddings in the target corpus LM. Something’s definitely going wrong there - your initial LM looks fine, and your target corpus is very similar, so you should get at least as good results.
Yes this makes sense. Thank you. Target LM loss is indeed too high for some reason. Trying to get to the bottom of it now.
Just curious - is there something similar for monitoring GPU work load?