Is it LossRecorder.on_batch_end()?
Novice here…
learn.TTA(is_test=True)?
How long this line should take on an average?(no %time)
In my case I ain’t sure whether is running or stuck ?
There was a tqdm integration done recently. It takes some time but you should see a progress bar soon.
Also, TTA on the test set takes longer than the validation set (which happens by default). 
2 Likes
How to push the accuracy further and min logloss?
tried everything what I have learned but it's not going beyond .93
Thanks in advance…
(Tried changing the models also…
Inception performs badly for some unknown reason)
I’ve trained an SENet version of resnet34 now on cifar and made the weight available at http://files.fast.ai/models/sen_32x32sen34.h5 . The model definition is in fastai.models.senet
1 Like
After getting more advice on how to manipulate fastai for our own needs or for the sake of experimentation. I tried to write a dataset class that will allow me to pass a 2d ndarray as input to fastai models. Of course my novice coding abilities and lack of understanding a code base were not enough to make this update.
So I’ve kind of figured out a work around how to pass 2 channels into SENet. Another thing is that I forgot to initialize cifar10 weights. so I kind of trained a nonsense thing from scratch. But still the point was to apply @jeremy’s advices practically (eg. allowing a model to have desired channels). Which was kind of my first post discussion here in forums, so I am very happy to be solving it now
I would ask that how can I improve this method of using custom data, and would there be any problems of using custom data as the way I did. Because basically I only made it work without thinking too much about details.
Thanks
Here is the norebook:
I am now updating it and will train with cifar10 weights.
Unrelated Request: Due to 1/8 train/test data ratio in iceberg challenge. I would like to give Semi-Supervised Learning a try. Can anyone recommend me links to learn the basics to implement the idea.
I think that looks just fine - as you say, it’s a simple and direct approach. With the change I just made today, you may be able to just use from_arrays BTW. If you can’t, I’d be interested to hear what the blocker is, so I can help.
We covered semi-supervised learning in last year’s DL course. Search wiki.fast.ai to find the lesson that covers it. I have some code floating around to do this in pytorch, but it’s not integrated into fastai. Happy to help you get that working if you’re interested.
2 Likes
@kcturgutlu If by Semi-Supervised learning you are referring to the technique pseudo labeling, I’ve also implemented this before in a Kaggle competition and got really good results, which I have to give full credit to Jeremy because I first learned it by watching fastai part 1 v1 videos
My code is in Keras but you should be able to get a better understanding for how it works and it shouldn’t be too difficult to re-implement in pytorch.
Here is the repo to my code.
6 Likes

Sorry, I don’t understand, how should I use this callback?
Oh apologies I may have misunderstood. I was showing you how to implement a callback - in this case, this file shows how callbacks are implemented to handle lr_find. Are you looking for some specific callback?
I was looking for something similar to EarlyStopping from keras
I haven’t implemented that callback, but the infrastructure is there for someone to do so if interested! The basic approach inside the learning rate finder shows how to stop learning.
1 Like
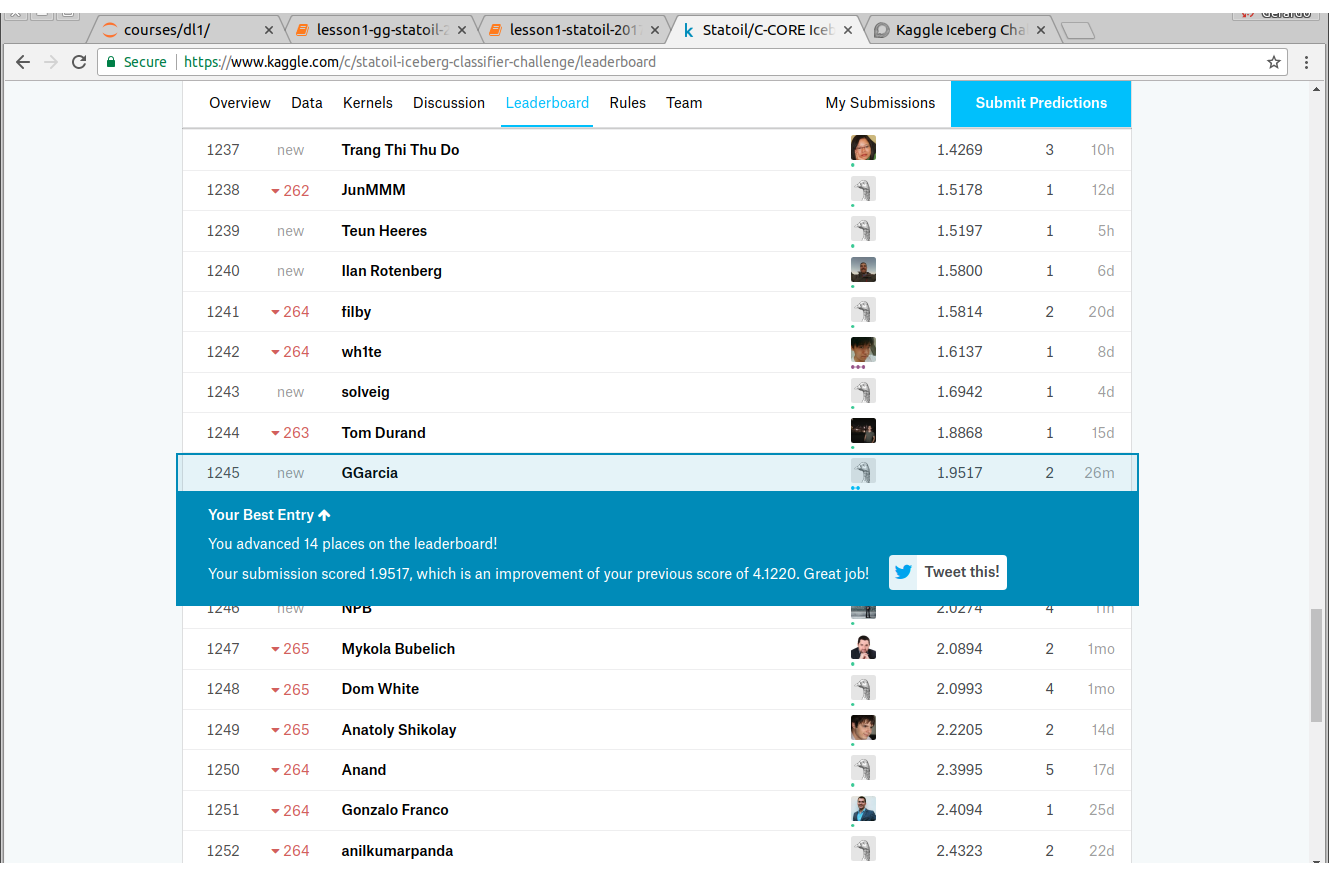
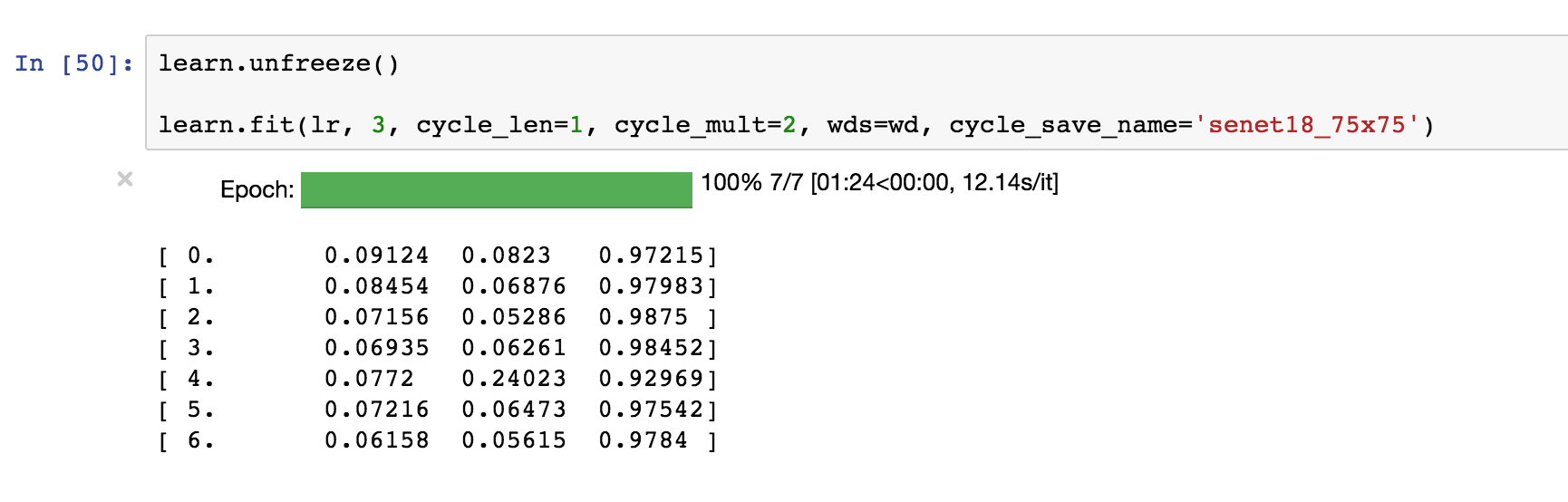
I’m getting really nice loss rates on iceberg challenge using SENet18 but when I submit to LB the score is still really poor. Not sure what could be the reason…is anyone else seeing something similar?
My final TTA on the validation set
(0.048662033940455388, 0.98618307426597585)
I can consistently get these loss rates even with different train/test splits.
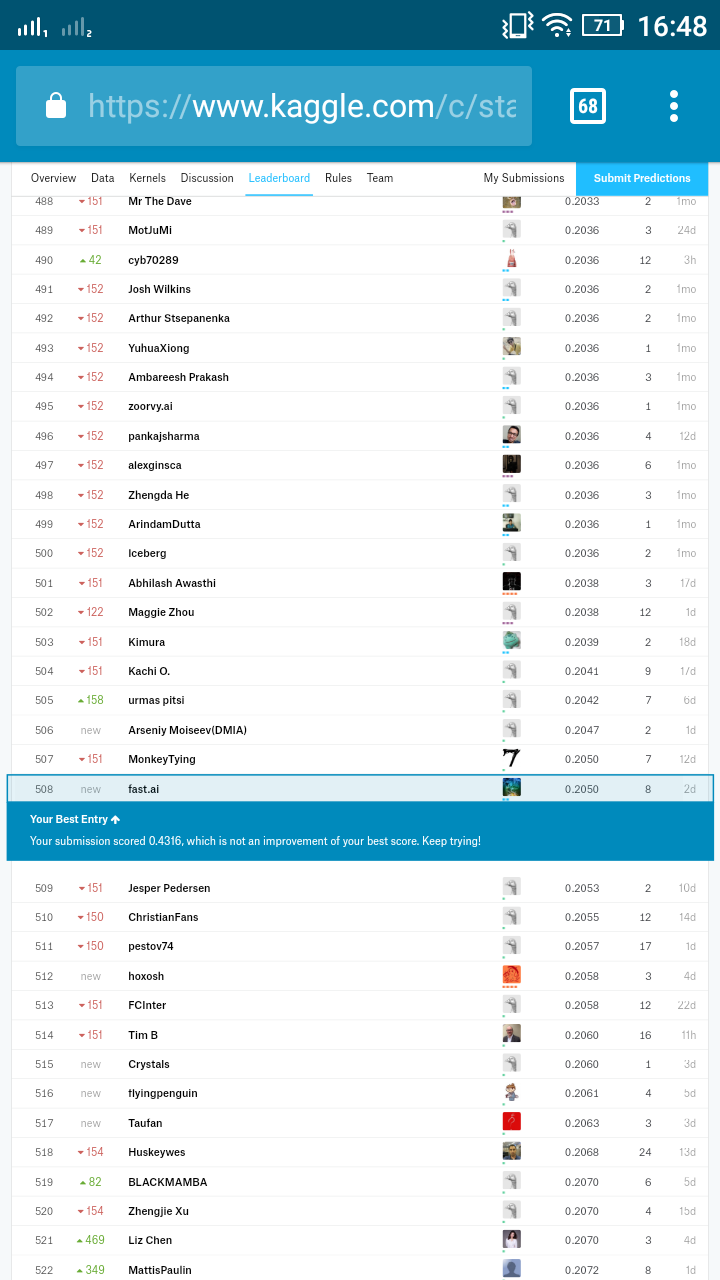
I had ended up with a logloss of .2050…
Using resnest34 and created an ensemble of 4 models and submitted the average…
Seeing other kernels out there, it seems that VGG16 plays this competition nicely…
This competition has a lot of machine generated data (using data augmentation) in the test set, to discourage hand labeling. None of that data is going to be in the private leaderboard dataset. So the public leaderboard on this competition isn’t that helpful…
3 Likes
Can you elaborate On the modification made to the last layer?
I didn’t technically make any modifications to the model. I simply used SENet18 as provided in fastai with weights pre-trained on CIFAR10. Yes this model does predict probabilities for 10 classes which are 0-9 but you can simply discard everything except probabilities for classes 0 and 1.
How can you know that(whether it’s machine generated or not??)
My best guess(limited knowledge)
Is to do clustering on images?
Have a look at the kaggle kernels and discussion where these is explained.