Yup Can’t believe it either Thanks @jeremy and @jamesrequa
So top 4 is officially fastai students and community.
This I didn’t even used the whole training set…I think i can still get a bump using Kstratified CV
and using my full training set.
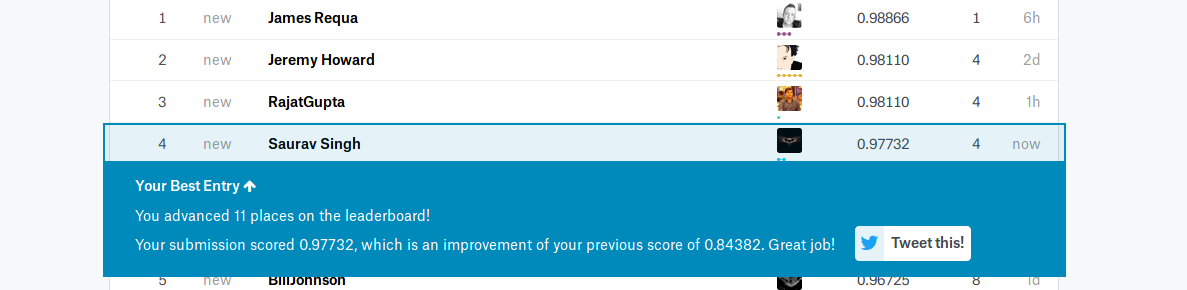
4 Likes
Hi,
Can someone share the accuracy / top 1 error rate for their model?
Regards
Here’s mine:
best validation loss 0.08718
best accuracy 0.97656
5 Likes
Should we remove all the folders in the train/folder and extract their files together and then use from_csv
Keep the images, remove the folders.
@ecdrid: Yes, first move all the images to the parent folder i.e train.
user@computer:~/fastai/courses/dl1/data/plant-seedlings-classification$ mv train/**/*.png train
and then, remove all the species folders:
user@computer:~/fastai/courses/dl1/data/plant-seedlings-classification$ rm -r train/**/
5 Likes
Getting the following traceback
/io/opencv/modules/imgproc/src/color.cpp:10606: error: (-215) scn == 3 || scn == 4 in function cvtColor
The notebook is attached
How to fix this??
PS-:Can someone confirm whether the following directory structure is correct or not?
~/data/planet/
test train labels.csv
test - containing files as it is downloaded
train - containing files from all species folder(species folders removed)
labels.csv(mapping of training image names to classes)
1 Like
/io/opencv/modules/imgproc/src/color.cpp:10606: error: (-215) scn == 3 || scn == 4 in function cvtColor
Are you sure you have deleted the species folders after moving the images?
The errors says that cvtColor with the COLOR_BGR2RGB expects an image with 3 or 4 channels, but got something different. Most likely, you haven’t deleted the folders.
Also, when you create labels.csv, do replace the relevant part with the following:
df = df.append({
"file": file_,
"species": species.replace(" ", "_")
}, ignore_index=True)
There are spaces in the species name. Replace them with underscores.
And, when you finally generate predictions and submission file, do the reverse:
log_preds_test = np.argmax(log_preds_test, axis=1)
preds_classes = [data.classes[i].replace("_", " ") for i in log_preds_test]
probs = np.exp(log_preds_test)
submission = pd.DataFrame(preds_classes, os.listdir(f'{PATH}test'))
4 Likes
According to the docs…
suffix: suffix to add to image names in CSV file (sometimes CSV only contains the file name without file
extension e.g. '.jpg' - in which case, you can set suffix as '.jpg')
I shouldnt pass suffix then as the labels files has it
This solves the problem…
Hi,
I was looping through the dataset and I see that the image sizes are varying a lot (49 to 3000+) . I need to scale them. torchvision.transforms.Resize is not working. What is the strategy to handle this? Border padding or thumbnail transformation?
Mine was.
best validation loss 0.12573
best accuracy 0.95814
1 Like
You don’t need to do that - that’s just a time saver. The best way is to use fastai lib transforms. We don’t use torchvision. See any of the lesson notebooks for lots of examples. We’ve been using sz for the size variable BTW.
What happen with the size?
The seedlings images are 1380x1380 pixels
The model from cats and dogs is 224x224.
What’s the best way to tackle this issue?
When I changed the sz=1380 the whole model never finished until I had to stop the whole notebook.
You can set sz to any size you want and all of the images will be resized to that same consistent image size. Personally, I tried both 224x224 and 300x300.

When I put the conffusion matrix
plot_confusion_matrix(cm, data.classes)
Something like this shows up
[[ 54 0 0 0 5 0 4 0 0 0 0 0]
[ 1 189 0 0 0 0 0 0 0 0 0 0]
[ 0 0 85 0 2 0 0 0 0 0 0 0]
[ 0 0 0 403 1 0 1 0 4 2 0 0]
[ 0 0 0 0 21 0 0 0 0 0 0 0]
[ 2 4 0 1 3 265 0 0 0 0 0 0]
[ 63 0 0 0 1 0 387 1 2 0 0 0]
[ 0 0 0 0 0 0 0 21 0 0 0 0]
[ 1 0 2 9 0 0 0 0 301 3 0 0]
[ 0 0 0 0 0 0 0 0 1 30 0 0]
[ 0 0 2 0 0 0 1 0 0 0 293 0]
[ 0 1 1 2 12 0 1 3 0 0 0 165]]
I would like to run the model only on those elements that are out of the diagonal

I’m not looking for answers I’m looking for guidance on best practices to analyze those cases and try to fix them if possible.
2 Likes
I hate you all! 
11 Likes
So I have been trying climb up the leaderboard and seem to have stagnated a bit. Currently @ 12th on LB with 95.34 score.
Tried the following:
- couple of resnet architectures, tried inception but the accuracies on validation was not in the same league
- using data-aug
- played around with dropout (trained separate models with and without dropout)
- used two image sizes, 300 and 400. Maybe I should try 200? most of the images seem to be sub 300x300
- did not unfreeze early layers ( the model was giving an OOM if I try to unfreeze and train at bs=64 on aws-p2)
- used all the training data (somehow if I hold back some of the training data, model predictions seem to be doing better, smells like overfitting)
- ensembled models
What else can I try?
- Wonder what it takes to get to 98% accuracy some of you have been seeing?
- Meaning to try: pseudo-labeling, k-fold cv
- or need to up my ensembling game?
I got 96% accuracy, using resnet50 (based on comments here) and using all of the techniques i know (including resizing images and a final training step of removing the validation set). I’ll go through tomorrow and see if I missed anything from the lectures. 
I have a ton of questions (apologies for so many at once):
I had an issue with my model where it appeared it was “overfit” pretty early on in my training process. Does it make sense in this case to discard your model and restart your training? I wound up with what looked like overfitting in step 3 of 7 that I did and model showed “overfit” numbers the rest of the way through my training steps. I figured the model would eventually “correct” itself, I’m not confident if this was the right approach.
I noticed that the model seemed to make it’s biggest improvements when unfreezing and training earlier layers. Intuitively, this makes sense since the image set is quite different from image net. I thought perhaps I should put some more training epochs into the earlier layers than what I wound up doing. How often do you adapt your training procedure based on this sort of in-training observation?
Finally, with discarding the validation set, is there any heuristic as to how to decide how much training to do? Since I can’t compare training with validation, I can’t tell if the model is overfitting or not. I was pretty conservative and only did 1 training step
learn.fit(.1, 3, cycle_len=1, cycle_mult=2)
I thought to possibly unfreeze and train earlier layers as well discarding the validation set because that seemed to work better for the model but I didn’t wind up doing it.
Finally, since the model seemed to overfit pretty quickly, is this at all because the training set is pretty small (iirc, 4500 images over 12 categories) and should we tweak number of epochs based on training set size?