Deep learning models are easy to overfit and transfer learning with pre-trained models with Fastai / Hugging Face solve vision and NLP problems faster. The weights inherited from these massive trained models make all this possible. Yet a lot of the talk around K-fold type training seems to point to expensive and or helpful in choosing a model types only. Setting aside the expense part, if the objective is to prevent overfitting and have a model that has the best weights for a particular problem, can it be approached this way:
- Initialize the weights from the pre-trained model on the first fold (resnet34 as is weights)
- After that, use the weights from fold1 as the validation for fold two across folds with minimal # of epochs
- Sweep all folds once before testing against the validation set?
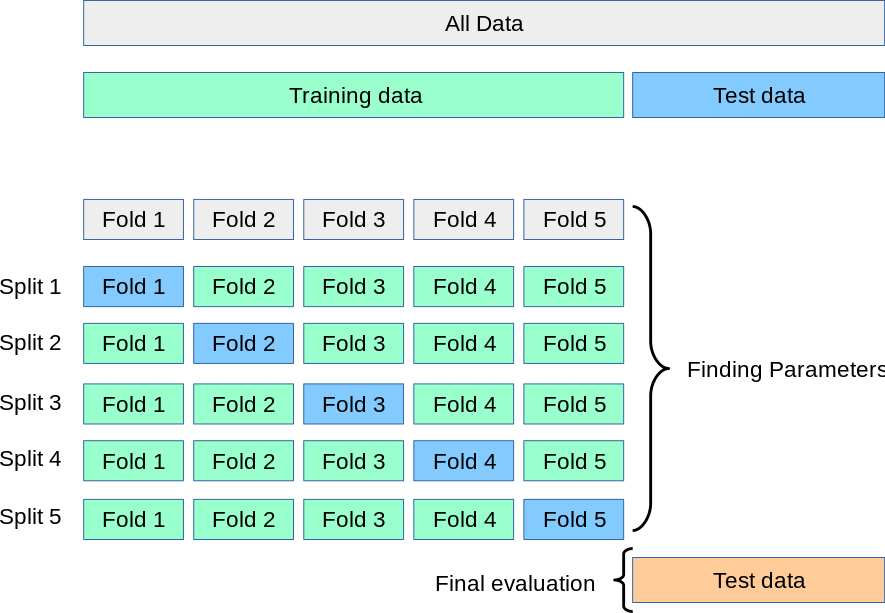
Would such a model built from a pre-trained model overfit compared to an 80-20 random split of the training data?