Hi all,
First time post - love the community
I am trying to train a language model on a set of tweets - dataset can be downloaded here:
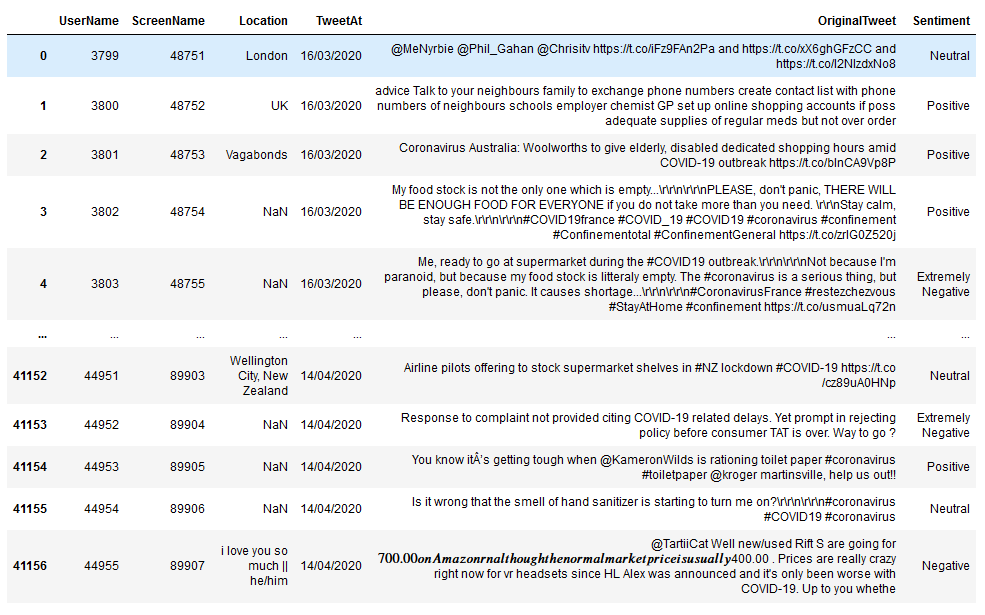
I have manually downloaded the train dataset (a .csv), saved as utf-8 encoding and uploaded it into paperspace notebook environment (Paperspace + Fast.ai container, free GPU).
After creating a TextDataLoader, dls_lm.show_batch() provides the following result:
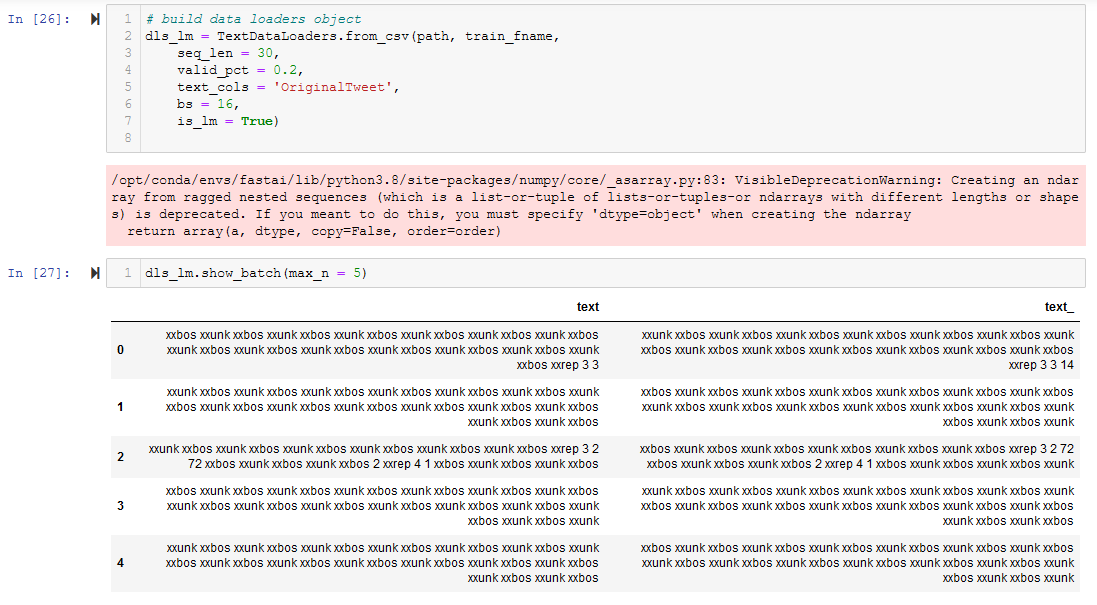
Ignoring what appears to be an obvious .show_batch() issue, when I train the language model I return an absurd accuracy -
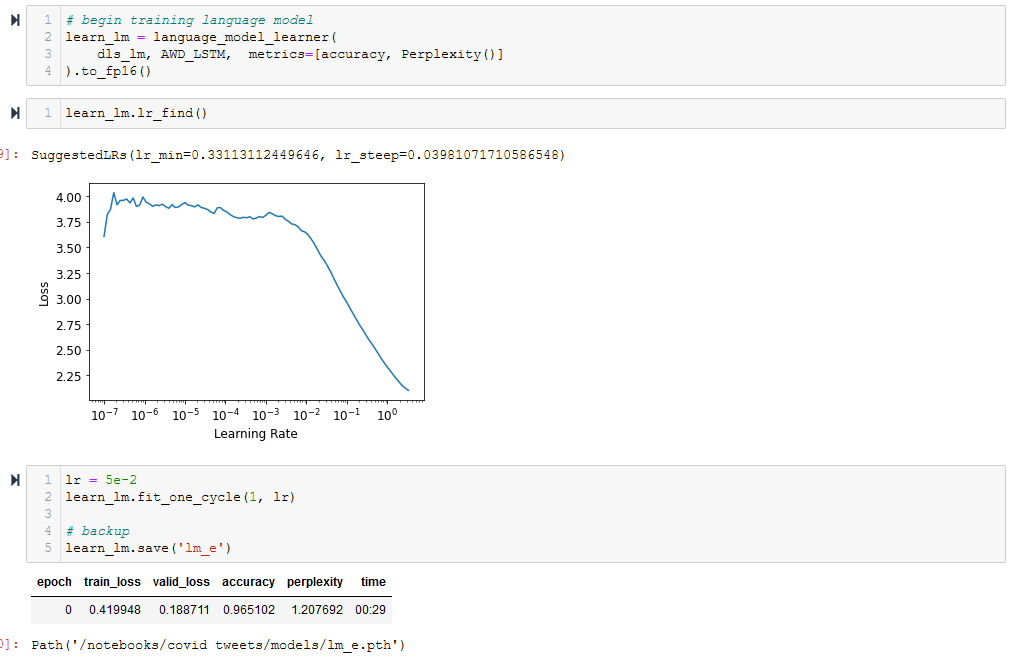
When I run .predict() with the trained language model, the output confirms that the data used for training is the corrupted junk displayed in show_batch() - all the prompts are selected from the training data, so they shouldn’t be xxunk

I have experimented with the original file, a manually saved UTF-8 encoding file, TextDataLoaders from_csv and from_df, yet the results are consistent - the data loaded into the language_model_leader appears to be corrupted.
Where might the error be occuring? What can I do to resolve the issue, or further narrow down the source of the error?
Thanks a lot in advance. Can provide more configuration information if necessary.