We always know target labels for train and valid sets.
In not all but some cases we also know the target labels for the test set.
I see that creating ImageDataBunch.from_folder it is setting y for test to EmptyLabelList.
It is annoying when later I want to run pred_test, y_test = learn.get_preds(ds_type=DatasetType.Test)
where I would like y_test to be my target labels. But it is just 0 everywhere (EmptyLabelList).
Is there an option to give to ImageDataBunch.from_folder in order to also initialize the y for test to a CategoryList like it does it for valid and train and not to EmptyLabelList?
There are quite a few topics on this on the forum. The test set is unlabeled, if you want to validate on a second set, use a second data object: more here.
Thank you very very much for the help @sgugger (and so fast for a sunday! - really cool merci )
Being new to fastai and pytorch, I was a little confused by the posts I had seen about it (often using things like “is_test” parameter, that seems not relevant to the current fastai), I was not sure what would be or not relevant, I prefered to ask new.
Your link was very helpful! found there what was the missing piece for me: Learner.validate
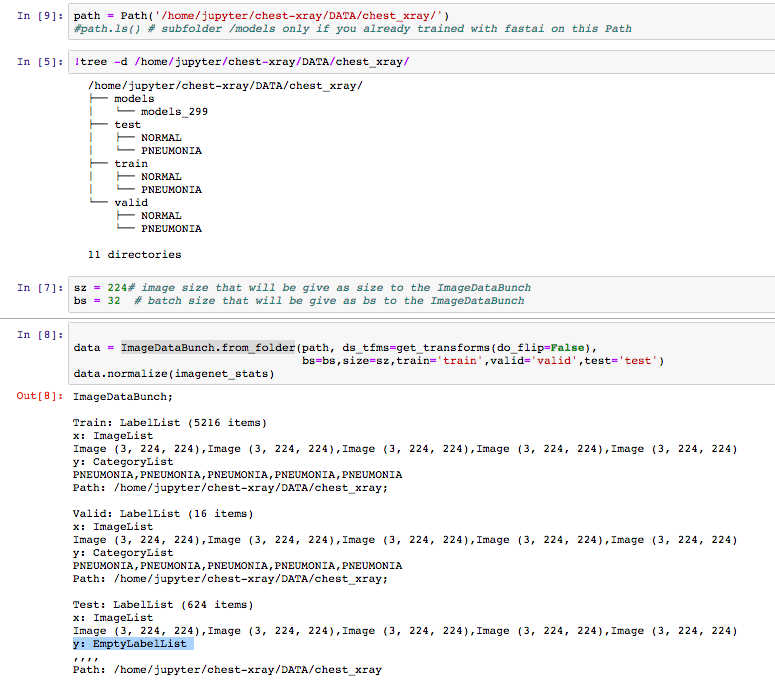
I finally opted for this solution (that works - I’m happy ) :
path = Path('/home/jupyter/chest-xray/DATA/chest_xray/')
path.ls() # subfolder /models only if you already trained with fastai on this Path
sz = 299 # image size that will be give as size to the ImageDataBunch
bs = 32 # batch size that will be give as bs to the ImageDataBunch
data = ImageDataBunch.from_folder(path, ds_tfms=get_transforms(do_flip=False),
bs=bs,size=sz,train='train',valid='valid',test='test')
data_test = ImageDataBunch.from_folder(path, ds_tfms=get_transforms(do_flip=False),
bs=bs,size=sz,train='train',valid='test')
data.normalize(imagenet_stats)
data_test.normalize(imagenet_stats)
arch = models.resnet34
learn = create_cnn(data, arch , metrics=error_rate) # create learn object with our data and given arch
learn.fit_one_cycle(4) # run 4 times through the whole dataset - default lr = 0.003 - ok with this lr_find plot
learn.validate(data_test.valid_dl)
To improve this code, is there a way to create a databunch only with my test data ? (ImageDataBunch.from_folder is expecting train batch in any case)
Interesting suggestion. For now there is none, but that could be arranged with the data block API, and it would be useful for this case. I’ll look at it tomorrow!
The tutorial I pointed out has this at the end of the first example, like I said. And it will work in any application.
You can also use the add_test method to add (or replace) a test set to any existing DataBunch.
Edit: I’m mixing this topic with another: here is the link to the tutorial.
To follow up, is there any way to save/load the Test DataBunch, so all the preprocessing on the test set doesn’t need to be re-run each time we run load_learner() for a given test set? (I’m using text data, so it has to be tokenized, numericalized etc).
Thank you for your quick response! Unfortunately that didn’t work either (“No attribute x of NoneType”). It turns out the problem is that learn.data.test_ds is only a property, and the dataset test_ds is actually contained within the dataloader test_dl. So it looks like this will work:
learn.data.test_dl = my_old_databunch.test_dl
On a related note, am I right to think that the order of the scores coming out of get_preds is the same as the class list in learn.data.train_ds.classes? (because somehow it seems it is not, even if I just use load_learner to load the databunch)
Sorry for all the questions. I now understand why the predictions didn’t seem to correspond to the databunch. This being text data, SortSampler is being used to order the samples by length for loading into batches of similar length. So the order of the predictions is not the same as the order of the databunch. It looks like get_preds with ordered=True is meant to reassemble the predictions in the order of the databunch. However this reassembly fails when n_batch is used, because it tries to provide predictions that haven’t been made. I guess it will work if I predict the whole databunch.
But otherwise is there a simple way to return/show the ordering (of the dataset) that is used for prediction? I actually need to relate the predictions back to the source dataframe for the databunch.
The predictions are in the same order as data.{your_ds}.x, except if you use a sampler to sort them (like for text). if you ask with ordered=True for text, they will be in the same order as data.{your_ds}.x.
 )
) - I’m happy ) :
- I’m happy ) :