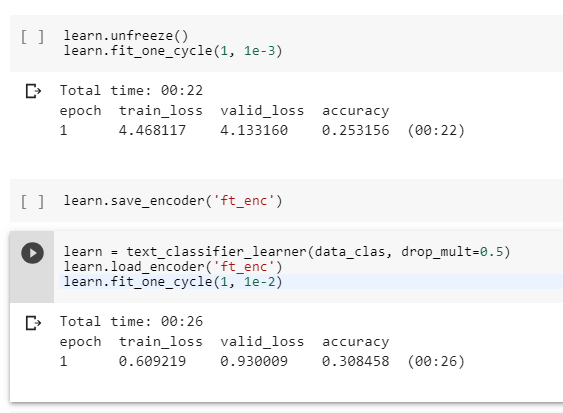
Update I switched to an older nightly pytorch version (10/25) and I still get the same error
I can’t get the text (imdb) example to run?
Is anyone else having issues with the latest fastai_v1 and nightly pytorch build?
Code:
from fastai import *
from fastai.text import *
path = untar_data(URLs.IMDB_SAMPLE)
path.ls()
df = pd.read_csv(path/‘texts.csv’)
df.head()
data_lm = TextDataBunch.from_csv(path, ‘texts.csv’)
learn = language_model_learner(data_lm, drop_mult=0.3, pretrained_model=URLs.WT103)
learn.fit_one_cycle(1, 1e-2, moms=(0.8,0.7))
Here is my error:
Downloading http://files.fast.ai/data/examples/imdb_sample
epoch train_loss valid_loss accuracy
Traceback (most recent call last):
File “text_example.py”, line 14, in
learn.fit_one_cycle(1, 1e-2, moms=(0.8,0.7))
File “/home/ubuntu/anaconda3/lib/python3.6/site-packages/fastai/train.py”, line 22, in fit_one_cycle
learn.fit(cyc_len, max_lr, wd=wd, callbacks=callbacks)
File “/home/ubuntu/anaconda3/lib/python3.6/site-packages/fastai/basic_train.py”, line 162, in fit
callbacks=self.callbacks+callbacks)
File “/home/ubuntu/anaconda3/lib/python3.6/site-packages/fastai/basic_train.py”, line 94, in fit
raise e
File “/home/ubuntu/anaconda3/lib/python3.6/site-packages/fastai/basic_train.py”, line 84, in fit
loss = loss_batch(model, xb, yb, loss_func, opt, cb_handler)
File “/home/ubuntu/anaconda3/lib/python3.6/site-packages/fastai/basic_train.py”, line 18, in loss_batch
out = model(*xb)
File “/home/ubuntu/anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py”, line 479, in call
result = self.forward(*input, **kwargs)
TypeError: forward() takes 2 positional arguments but 73 were given
My environment (aws)
ubuntu@ip-172-31-19-203:~/milestone$ python -c ‘import fastai; fastai.show_install(1)’
=== Software ===
python version : 3.6.5
fastai version : 1.0.21
torch version : 1.0.0.dev20181025
nvidia driver : 396.44
torch cuda ver : 9.2.148
torch cuda is : available
torch cudnn ver : 7104
torch cudnn is : enabled
=== Hardware ===
nvidia gpus : 1
torch available : 1
- gpu0 : 16160MB | Tesla V100-SXM2-16GB
=== Environment ===
platform : Linux-4.4.0-1070-aws-x86_64-with-debian-stretch-sid
distro : #80-Ubuntu SMP Thu Oct 4 13:56:07 UTC 2018
conda env : Unknown
python : /home/ubuntu/anaconda3/bin/python
sys.path :
/home/ubuntu/src/cntk/bindings/python
/home/ubuntu/anaconda3/lib/python36.zip
/home/ubuntu/anaconda3/lib/python3.6
/home/ubuntu/anaconda3/lib/python3.6/lib-dynload
/home/ubuntu/anaconda3/lib/python3.6/site-packages
/home/ubuntu/anaconda3/lib/python3.6/site-packages/IPython/extensions
Fri Nov 9 05:29:43 2018
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 396.44 Driver Version: 396.44 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla V100-SXM2... On | 00000000:00:1E.0 Off | 0 |
| N/A 29C P0 23W / 300W | 10MiB / 16160MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+