Hey everyone,
i am working on a multiclass classification project and used a pretrained ResNet151 as a backbone. I got some good results but i am not sure if i did everthink right, specially working with a unbalanced Dataset.
The trainingdata are unbalaced and look like this:
Class 0: 1147
Class 1: 922
Class 2: 338
Interpretation of Training!..Do i need more Trainingsdata?
Best Practise for me
1.Training
learn = cnn_learner(data, base_arch=models.resnet152 , pretrained=True, metrics= accuracy)
learn.freeze()#by default if you load it from FastAi Libary
learn.summary()
learn.lr_find()
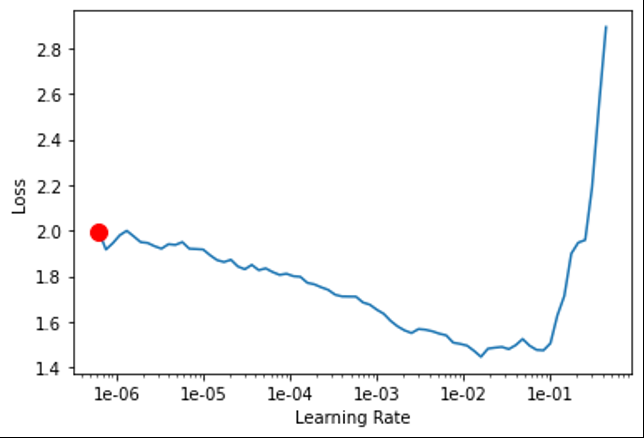
so i picked
lr = 2.5e-3 and trained it learn.fit_one_cycle(10,lr) and get this Graph
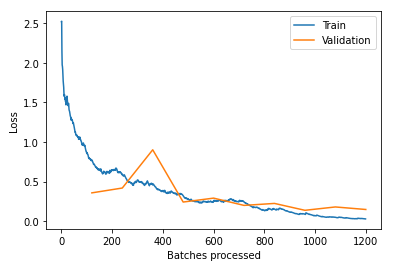
can somebody explain to me, why the jump of the valid_loss at batch=380 happens?
i think the plot looks good for me. My Model is slightley overfitting after 900 Batches but its tolerable, or not? valid_loss and valid_train continue decreasing. After 10 epochs the accuracy is 0.945946. I am super happy so i kept training. Now i want to train the pretrained weights. Therefor i used unfreeze() to make all layers trainable. Used lr_find() and get this:
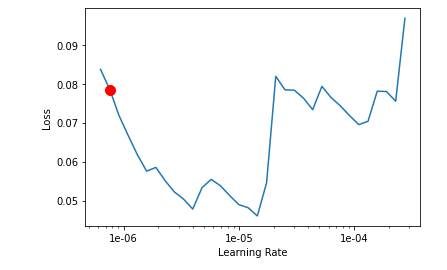
I decided to use a discriminatory learning rate lr_slicer = slice(6e-7,1e-6) and trained it for 10 epochs learn.fit_one_cycle(10, max_lr=lr_slicer). I wanted to train the body with a low learningrate to avoid.
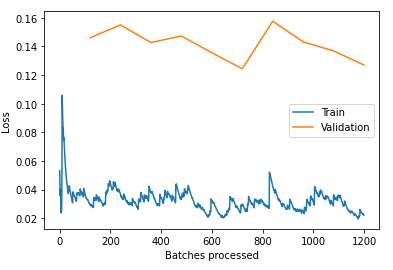
After 10 epochs the accuracy goes up 0.954262. valid_loss and train_loss keep going down so should i keep training with a very low learning rate? not sure about this.
interpretation results
with interp.most_confused(min_val=2) i get this.
[(‘1’, ‘0’, 6),
(‘1’, ‘2’, 6),
(‘0’, ‘1’, 5),
(‘2’, ‘1’, 4)]
Next to improve the Model
- finetunning model with a Dataset with classes 1, so that the model can learn more features of this class? This woult be my next step what do you think guys?
.
TestDataset
Do be honest i am super happy with this but i wasent sure because of my unbalaced Dataset. I decided to create a TestSet which look like this:
Class 0 : 104
Class 1: 143
Class 2: 276
The accuracy of the TestSet is 86%
What would be the next step to make my model better?
For me: Generate more Trainingimages of class 0, like mention above.
Please feel free to correct me and suggestions are very welcome