Version: fastai v 1.0.22
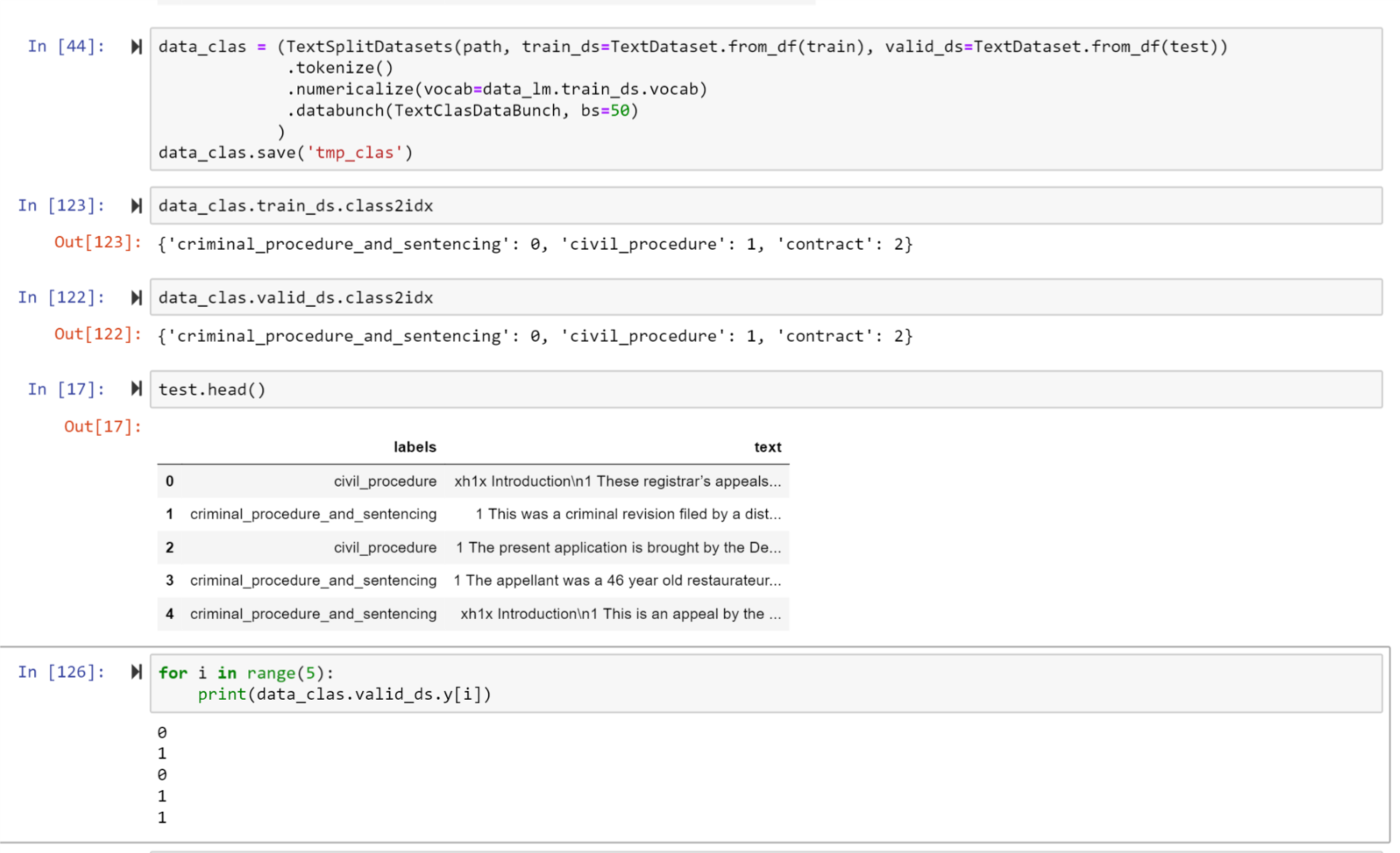
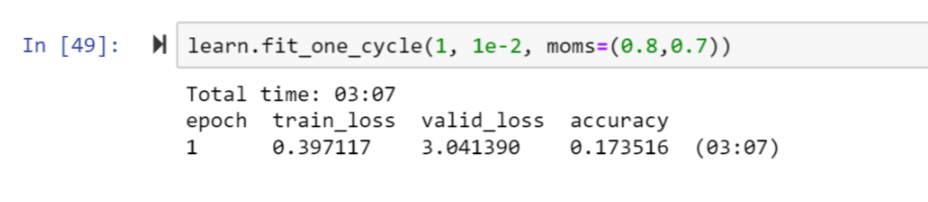
I was training a text classifier using text_classifier_learner after fine-tuning a language model on my own dataset and was surprised to see that the metrics valid_loss was huge (7.03622) and accuracy was low (0.173516) when train_loss was low (0.397117).
I then ran learn.predict on my validation set for confirmation and interestingly, the results showed about 90% of the model’s predictions were correct, so I went on to examine the TextDatasets in the TextClasDataBunch and noticed what I believe to be the y labels seemed off? Not sure whether I am on the right track but if this were the case, it would explain the unexpected training numbers.
For context, I had created the TextClasDataBunch for the text_classifier_learner using TextSplitDatasets and passing in TextDataset.from_df for the train_ds and valid_ds args.
Could anyone else confirm this?