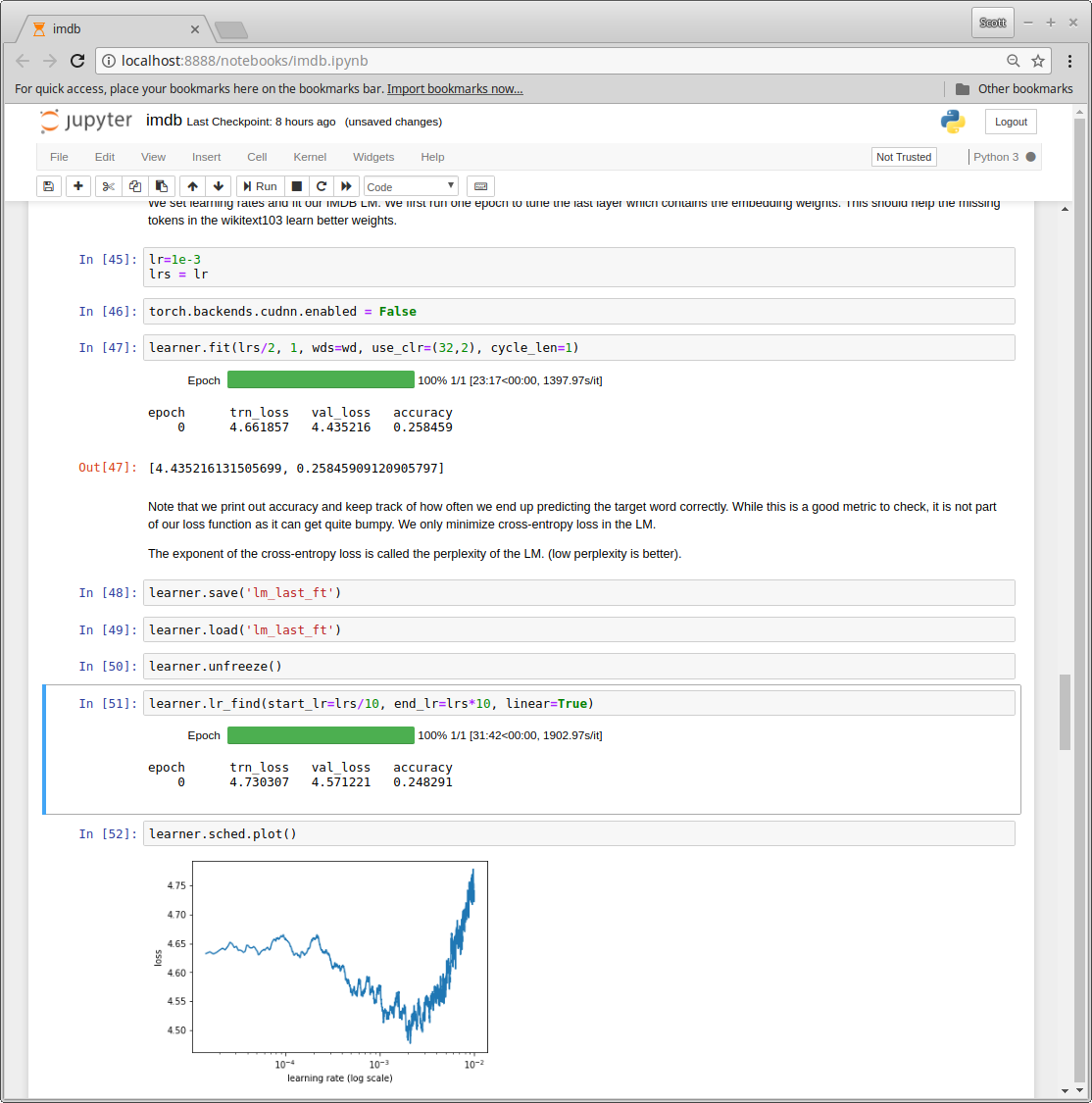
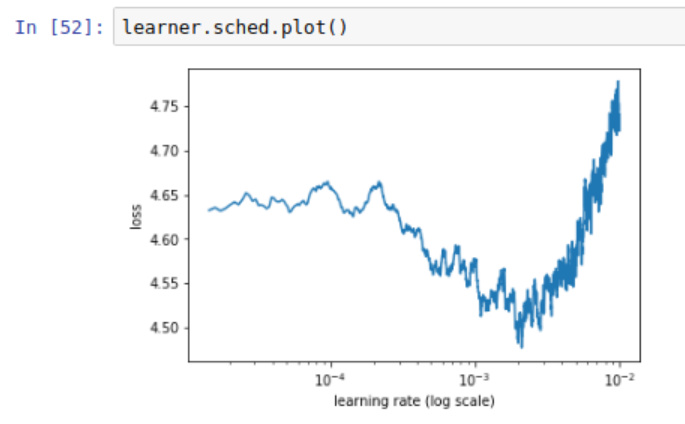
After unfreezing the learner and doing an lr_find(), the resulting plot is much more jagged than I have seen in previous exercises. I wonder if everything is okay?
Perhaps related, I had to set, in line 46, torch.backends.cudnn.enabled = False, as discussed on the forum, or learner.fit() would throw an exception.
That’s a good observation about the small range of loss in the y-axis, thanks.
To answer your question, well, probably it is a reasonably tuned model to start. This invocation comes directly from the lecture 10 IMDB notebook. It has loaded the pre-trained wiki-103 model, then it has run one epoch with the last layer unfrozen on IMDB, in order to accommodate the new tokens present in IMDB. The cross-entropy loss at the end is reasonable. So, yes, I think this qualifies as a fairly well tuned model even at this point.
Subsequent training gets the loss down modestly, from around 4.43 to around 3.9 (maybe that is better than modestly). The accuracy nudges up a bit too.
By the way, I’m interested in any details that Jeremy might provide about how he trained the wiki-103 model. I assume that it was along the lines of lecture 4, but with his new stuff replacing torch.text. But I bet there were a lot of details to get right, and it might even be the case that he’s not eager to share all the details at this time. (Or maybe he has and I haven’t seen it yet.)