[Solved] - There’s uncontrollable randomness due to the state of shuffling your training items. This is not a problem with fastai or the saving / loading functionality. (see bottom for full write-up)
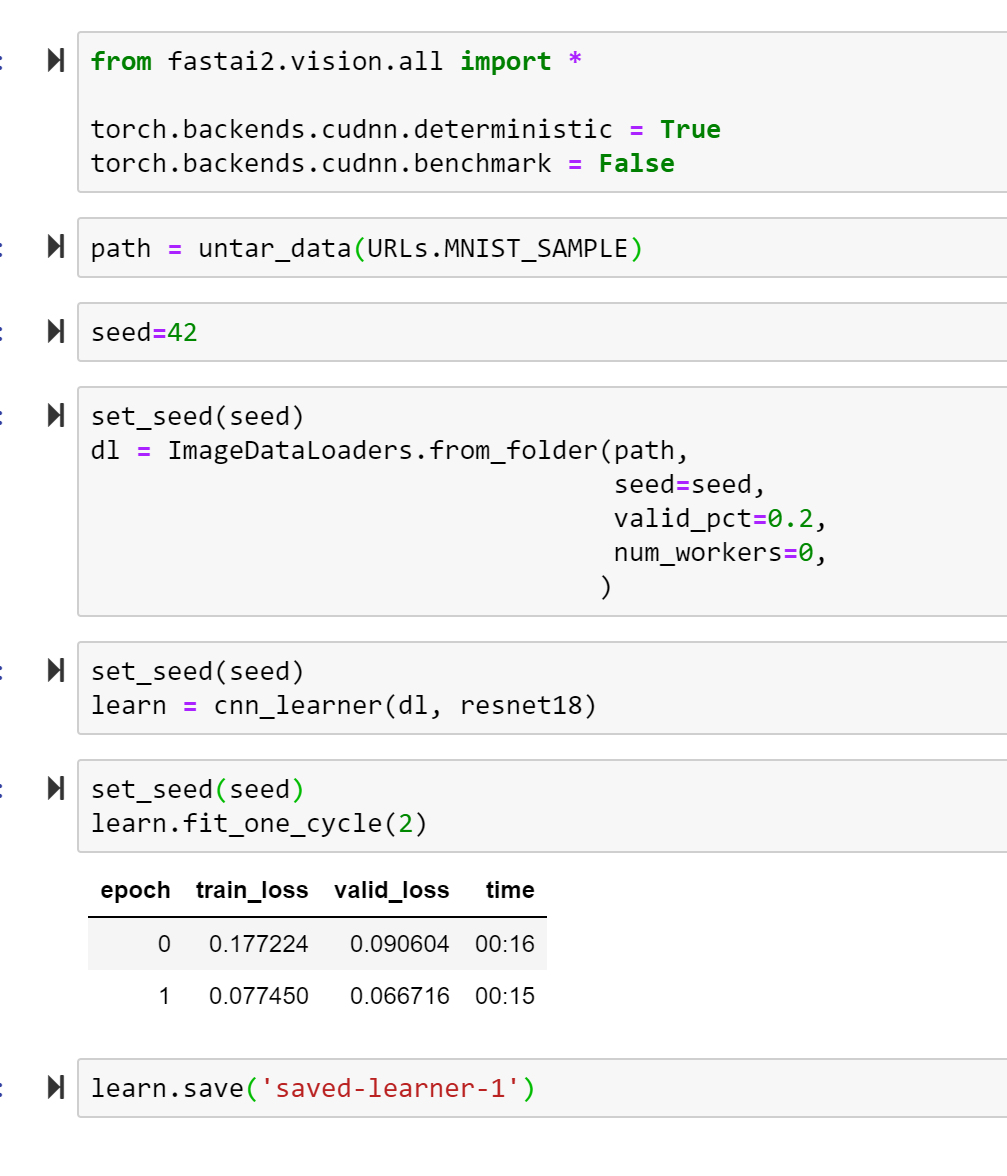
I’ve reduced my problem down to a toy MNIST example.
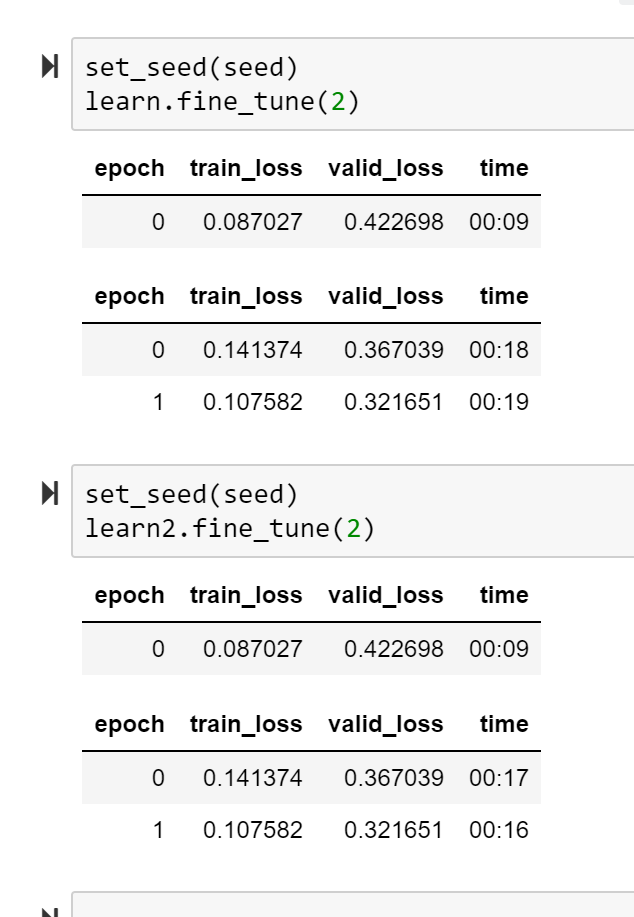
Step0: we’ll use reproducible settings like torch to deterministic mode, and set_seed(42) before each step. Step1: we’ll initialize the data, model, and quickly fit it. Then we’ll .save() this model. Step2a: we’ll initialize the same model and data as learn2 and dl2. Meanwhile learn and dl are still available. Step2b: Now we’ll do more fitting on learn and learn2 using the same params and setting seed before we do so. As you can see, the results are different. Why?
I don’t know what’s going on here exactly, but I would warn against putting too much time into trying to guarantee fully identical runs. Some CUDA/cudnn operations are themselves nondeterministic (although I’ve read that recently they’ve been adding more deterministic operations) so you’re never going to be able to reproduce the run exactly as long as you’re depending on those.
You might be right. For my example it was 96% vs 89% on a benchmark I cared about. So the “fresh” learner seemed better than the “loaded” learner. I’m looking to make sure the loaded representation is not missing any critical. But also maybe I’m doing something subtly wrong?
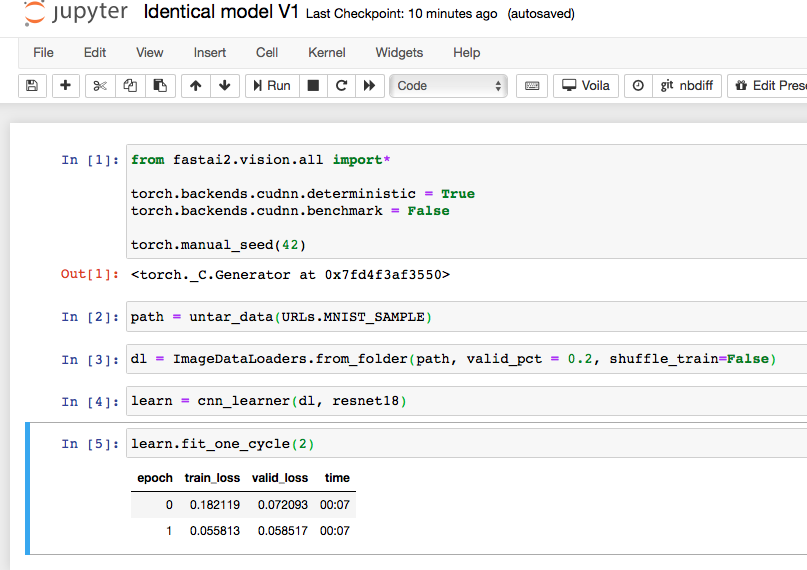
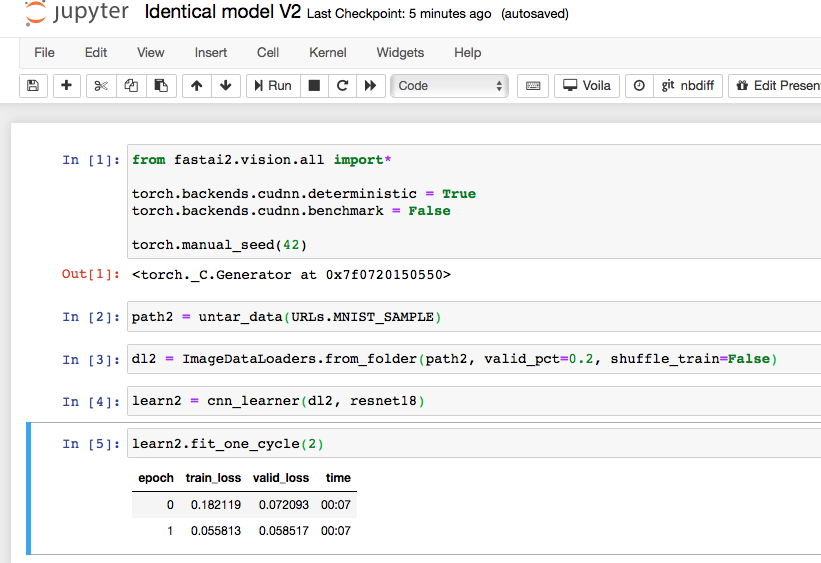
The un-reproducibility can be removed by setting shuffle_Train=False when building the DataLoaders for each learner. When this is performed, like here, we get identical results on subsequent fitting.
Yes, shuffle_Train = false is where I ended up also after looking over the docs for ImageDataLoaders. Thanks for posting the initial issue, it was fun to go through it and find out what was happening under the code. https://dev.fast.ai/vision.data#ImageDataLoaders
Good find! But does that mean there’s some additional seed that could be set to make it deterministic? The shuffle part of shuffle_train has got to depend on something
Setting random.seed(0) or random.Random(0) doesn’t help. It looks like something how in .randomize method of DataLoaders uses random.Random(). From it’s doc:
Used to instantiate instances of Random to get generators that don’t
share state.
So, we can’t affect that random seed of this generator globally (?)
Setting learn.dls.rng = random.Random(0) seems like it should work but it doesn’t work either.