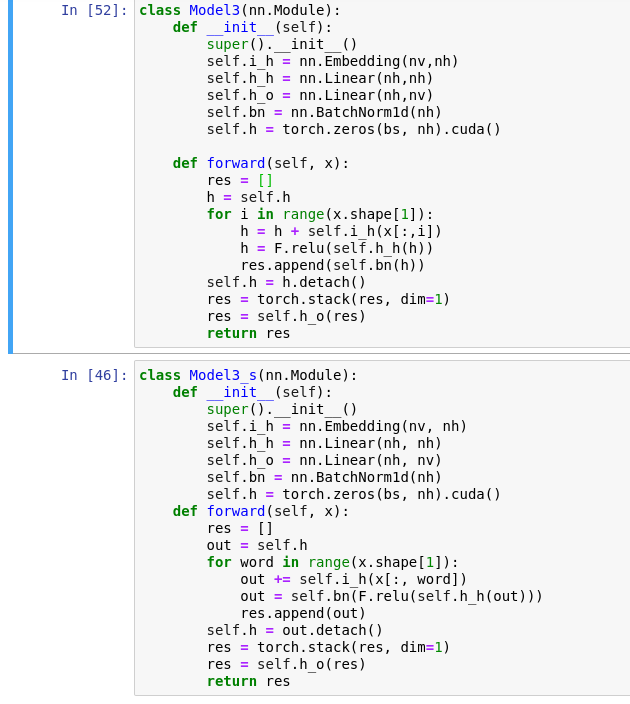
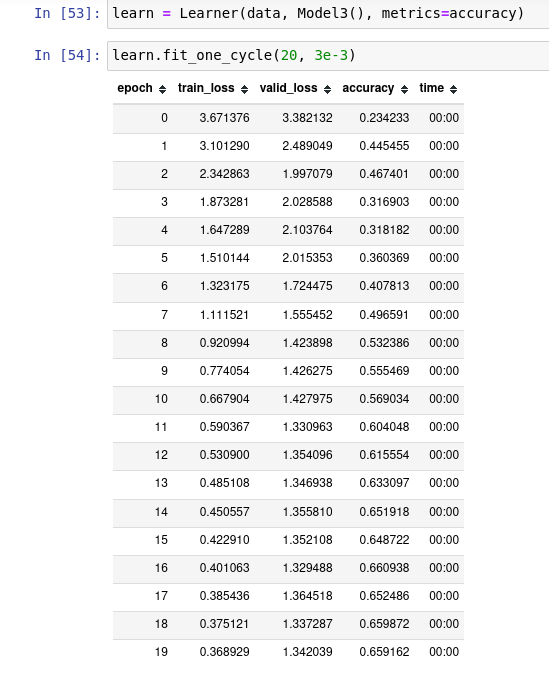
I was going through the fastai-nlp course and which reimplementing the notebook, in the maintain state section of it, just changing the placement of batch normalization placement in the code(which shouldn’t make much change) brings such a huge jump in accuracy.
In my code, I have just changed the position of self.bn to a line above, but the jump in accuracy is huge although everything is same and the validation loss looks like it is not overfitting. So can someone help in explaining this?