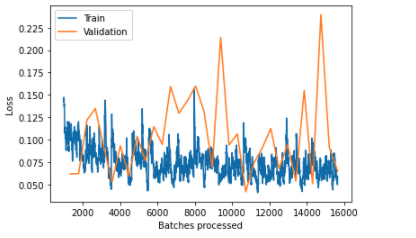
The train is pretty unstable and the validation loss goes high and then low again but generally I assume my model overfits. Pay no attention to price_accuracy since even if my model overfits for an uknown reason the accuracy of this class goes up .The problem has 3 more classes (I do seperate tests with every single class ) where when the overfits starts the accuracy of the class will not increase .So i think this behaviour is class specific.
But what I dont’t understand is does it really overfits (it s my assumption) ? (in which epoch??) or it s just the train that looks pretty unstable and maybe i have to rethink about my network architecture?
P.S the problem is an object detection problem with 2 classes (price + background) .The bounding boxes are fixed (99 background + 1 price) so my network uses (after vgg16) some convolution and roi_pool to classify the boxes . I also use a 1/100 weight in CrossEntropy loss to balance the classes .Thus the total_accuracy of 98-99% is not good at all if the price accuracy is low
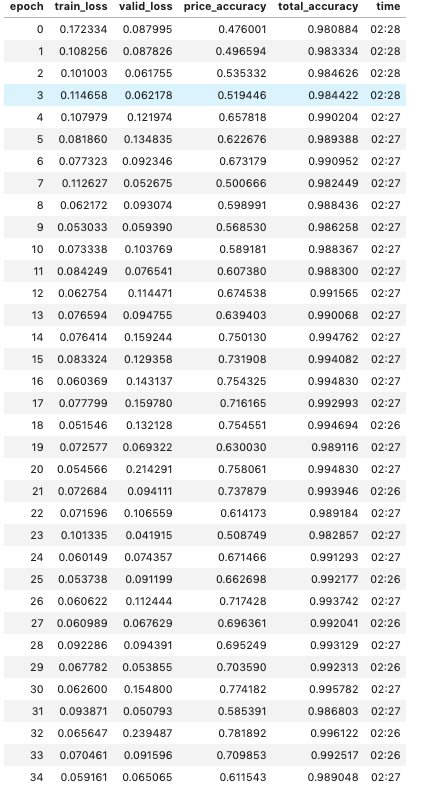
What i find the most intriguing, is that your loss (both training and validation) are quite stagnant - they’re going up and down a particular small range. Your weights are pretty much stagnant. I do believe you’re overfitting, looking at your accuracy and the fact that your loss is just not moving. But you dont need to change your network architecture. Infact, what i’d suggest is not training so far. Observe that even a few epochs of training get you to almost 100% accuracy. There’s no point in training 35 epochs.
Something important to note ( i will update my post ) its that my problem is a 2 class object detection problem (price or background) where i have 99 backgrounds and 1 price ( i use the 1/100 weights in cross entropy loss to balance the classification) .So the total accuracy is not a good indicator .
I’m not entirely sure what price_accuracy really means in your code. Can you please shed some light on it? Its meaning, and whether that is an accurate metric in your case?
I also want to tell you this- a high value of the metric in cases like yours (where the distribution of classes is so imbalanced) is not always a measure of good performance. So unless you have a ** good** metric, you should also look at how the model is performing, visually ! Maybe your model is doing well afterall, and maybe not at all! That would help you decide if your model is overfitting, or underfitting, or doing just well!
Ok . I have a CNN that get’s a screenshot from a product url (from a site) and tries to predict the price of the product.
More specifically using html I can get the bounding boxes of all text-nodes. So I have for example 100 candidate boxes, 1 of them is the price box and the other 99 are background(common object detection pattern)
My input to the network is an image and the bounding boxes I want to classify.
And my output is the predicted class for each bounding box.
The big difference with common object detection problems is that I already have the candidate bounding boxes and I have to solve just a classification problem
So my training set has images from 150 different shops (1k images) and my validation 180 images (from 60 shop).
I use weighted CrossEntropyLoss with weights [0,1 , 10] making a prediction for background class 100 times less important that a prediction for a price class. If I don’t use weights all predictions will be 0 (background) hitting a constant 99% total_accuracy
(The setup is from a paper I bought and they did a successful train with very high accuracies .Of course this is totally related to the dataset .So the CrossEntropyLoss works for their dataset .I don’t think it s the main cause of the overfitting problem)
The overfit was pretty huge before I use Dropout on the last 2 layers.
Do you have any feedback on how to detect what’ s going on wrong?
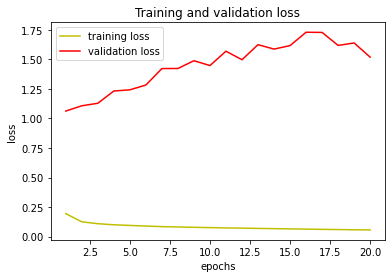
Hey I think my model is overfitting and I cant figure out how to fix it the, graphs below shows the traning loss and validation loss on the train and test sets