Hi.
I am building a classifier using the Food-101 dataset. The dataset has predefined training and test sets, both labeled. It has a total of 101,000 images. I’m trying to build a classifier model with >=90% accuracy for top-1. I’m currently sitting at 75% and I’ve built this model using what I’ve learned from Mr.Howard so I owe him big thanks. The training set was provided unclean. But now, I would like to know some of the ways I can improve my model and what are some of the things I’m doing wrong.
I’ve partitioned the train and test images into their respective folders. Here, I am using 0.2 of the training dataset to validate the learner by running 5 epochs.
np.random.seed(42)
data = ImageList.from_folder(path).split_by_rand_pct(valid_pct=0.2).label_from_re(pat=file_parse).transform(size=224).databunch()
top_1 = partial(top_k_accuracy, k=1)
learn = cnn_learner(data, models.resnet50, metrics=[accuracy, top_1], callback_fns=ShowGraph)
learn.fit_one_cycle(5)
| epoch | train_loss | valid_loss | accuracy | top_k_accuracy | time |
|---|---|---|---|---|---|
| 0 | 2.153797 | 1.710803 | 0.563498 | 0.563498 | 19:26 |
| 1 | 1.677590 | 1.388702 | 0.637096 | 0.637096 | 18:29 |
| 2 | 1.385577 | 1.227448 | 0.678746 | 0.678746 | 18:36 |
| 3 | 1.154080 | 1.141590 | 0.700924 | 0.700924 | 18:34 |
| 4 | 1.003366 | 1.124750 | 0.707063 | 0.707063 | 18:25 |
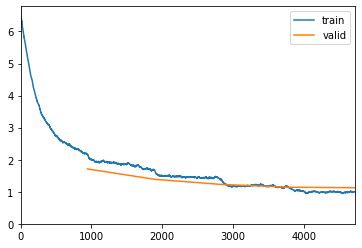
And here, I’m trying to find the learning rate. Pretty standard to how it was in the lectures:
learn.lr_find()
learn.recorder.plot(suggestion=True)
LR Finder is complete, type {learner_name}.recorder.plot() to see the graph.
Min numerical gradient: 1.32E-06
Min loss divided by 10: 6.31E-08
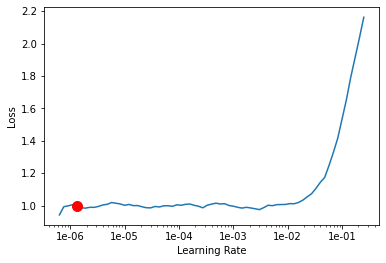
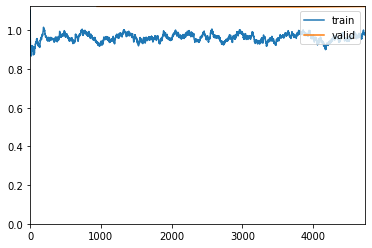
Using the learning rate of 1e-06 to run another 5 epochs. Saving it as stage-2
learn.fit_one_cycle(5, max_lr=slice(1.e-06))
learn.save('stage-2')
| epoch | train_loss | valid_loss | accuracy | top_k_accuracy | time |
|---|---|---|---|---|---|
| 0 | 0.940980 | 1.124032 | 0.705809 | 0.705809 | 18:18 |
| 1 | 0.989123 | 1.122873 | 0.706337 | 0.706337 | 18:24 |
| 2 | 0.963596 | 1.121615 | 0.706733 | 0.706733 | 18:38 |
| 3 | 0.975916 | 1.121084 | 0.707195 | 0.707195 | 18:27 |
| 4 | 0.978523 | 1.123260 | 0.706403 | 0.706403 | 17:04 |
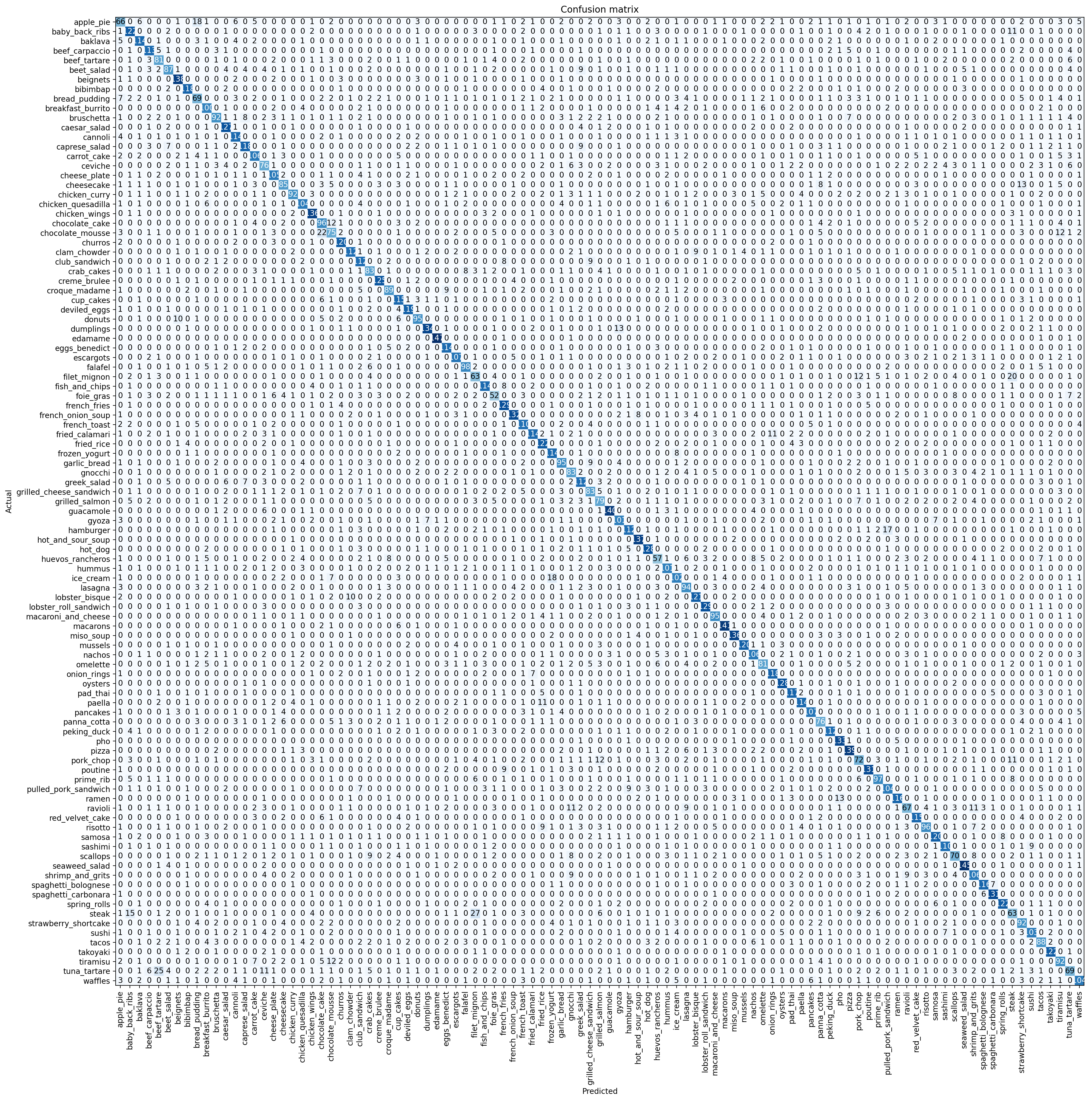
Previously I ran 3 stages altogether but the model wasn’t improving beyond 0.706403 so I didn’t want to repeat it. Below is my confusion matrix. I apologize for the terrible resolution. Its the doing of Colab. I will post the link to the full notebook.
Since I’ve created an additional validation set, I decided to use the test set to validate the saved model of stage-2 to see how well it was performing:
path = '/content/food-101/images'
data_test = ImageList.from_folder(path).split_by_folder(train='train', valid='test').label_from_re(file_parse).transform(size=224).databunch()
learn.load('stage-2')
learn.validate(data_test.valid_dl)
This is the result:
[0.87199837, tensor(0.7584), tensor(0.7584)]
This is the link to the full notebook.