I am trying to do pixel wise segmentation of text in images. For that, I am using images without text and then synthetically adding text on them with random transforms. I would want to generate the segmentation mask based on the text I added to the image without needing to generate x examples and storing to disk.
My code:
class DanbooruImage(ItemBase):
def __init__(self, image, fileDir, idx):
self.data = idx
self.image = image
self.fileDir = fileDir
def __str__(self): return str(self.image)
def apply_tfms(self, tfms, **kwargs):
for tfm in tfms:
tfm(self, **kwargs)
return self
class DanbooruSegmentationList(SegmentationItemList):
@classmethod
def from_textInfo(cls, textInfo: dict, maxItems=10, maxArea=0, **kwargs):
gen = filter(lambda k: textInfo[k] <= maxArea, textInfo.keys())
items = [x for _, x in zip(range(maxItems), gen)]
return DanbooruSegmentationList(items, **kwargs)
def get(self, i):
fileDir = self.items[i]
image = self.open(fileDir)
return DanbooruImage(image, fileDir, i)
def open(self, fileDir):
return pilImage.open(fileDir).convert('RGB')
fonts = Fonts.load(Path('fonts'))
train_fonts, valid_fonts = Fonts(fonts[len(fonts)//10:]), Fonts(fonts[0:len(fonts)//10])
ds = DanbooruSegmentationList.from_textInfo(text_info, maxItems=1000).split_by_rand_pct(0.1, seed=42).empty_label()
data = ds.transform(([partial(textify, fonts=train_fonts)], [partial(textify, fonts=valid_fonts)]))
data = data.databunch(bs=64, collate_fn = custom_collate).normalize(imagenet_stats)
data.c = 2
def getSegmentationMask(dan):
y, x = dan[0].y_tensor, dan[0].x_tensor
res = ((y[0] == x[0]) + (y[1] == x[1]) + (x[2] == y[2])) == 3
res = res.unsqueeze(0)
return res
def custom_collate(batch):
State.resetRandomSize()
return torch.stack(list(map(lambda x: x[0].x_tensor, batch))), torch.stack(list(map(getSegmentationMask, batch))).long()
Note that textify is a function that takes a DanbooruImage and a font and adds text to it, storing the text edited version in x_tensor and the original version in y_tensor.
data.show_batch appears to be working:

But then trying to train unet gives an error:
learn = unet_learner(data, models.resnet18)
learn.lr_find()
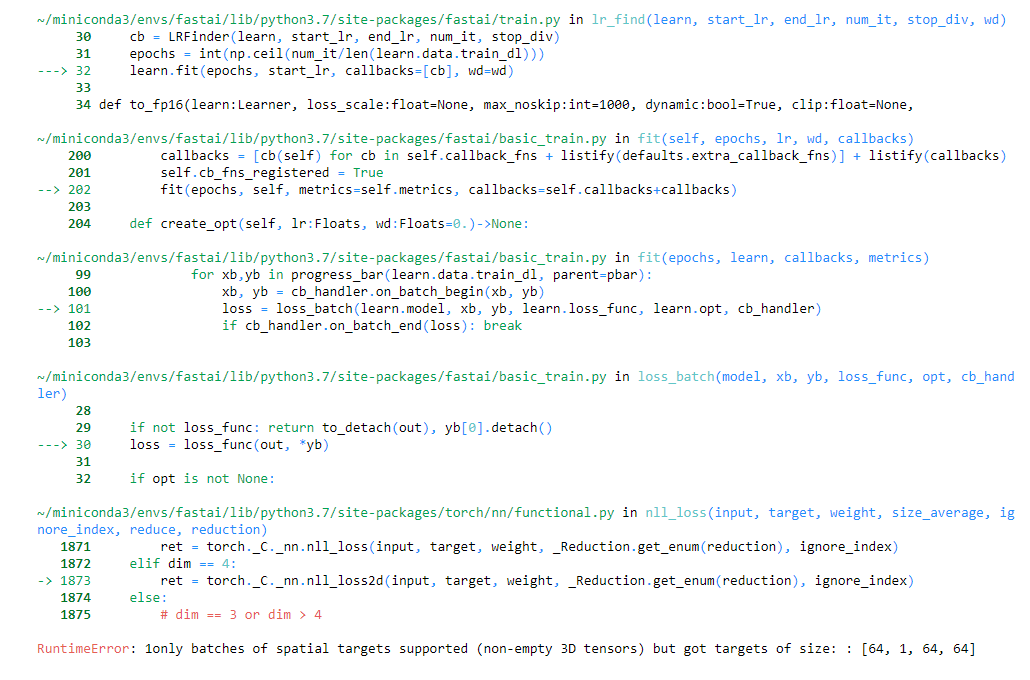
Am I doing something wrong in custom_collate or there is another issue?