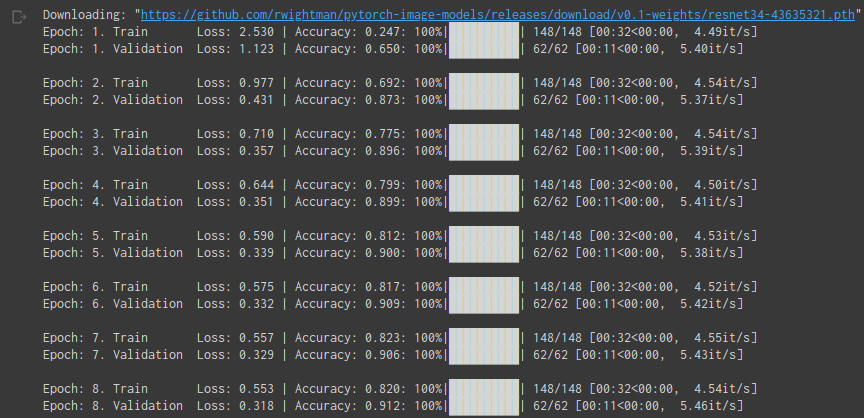
Does anyone have general recommendations to combat this case where the model hasn’t fitted the data enough?
So far, I have:
- Use a higher Learning rate and see if it improves
- Use more epochs
Any more?
Does anyone have general recommendations to combat this case where the model hasn’t fitted the data enough?
So far, I have:
Any more?
The general recommendation is to train more.
Your training and validation losses continue to decrease. That indicates more training is called for. In fact, the course suggests that training should continue as long as the validation measures continue to improve. A higher learning rate may help convergence, or it may explode the losses, but this is something you would have to try to find out. The choice of hyperparameters is yours. It is an art learned from experimentation and experience.
If you will indulge me to reply further - I understand this is not exactly your question - a given model is not necessarily “smart” enough to solve a given problem. It may top out at say 80% accuracy. Thus we have Kaggle competitions and SOTA records. If you are not satisfied with the ultimate accuracy of a model/problem, you will need to make the model architecture smarter.*
HTH,

‘*’ But not too smart, otherwise the model will eventually memorize the training set and you are dealing with overfitting!
Wow. You answer is intuitively easy to understand. Thank you.
So keep training my model as long as my metrics are still decreasing.
Fiddle with the learning rate, it may or may not help but experiment.
And if my model is not smart enough, make it smarter. (I’m assuming by using better models and training loops)
I agree with this, having finished the course and thrown myself into the deep end where I just experiment myself, I’m getting to see a lot of practical things that no one can really teach you. You have to learn then experimentally yourself.
Have a great day
You also!