I’m baffled here. When loading a pickled model and running the exact same code and data twice how are the exact same results not returned? Am I missing something obvious here?
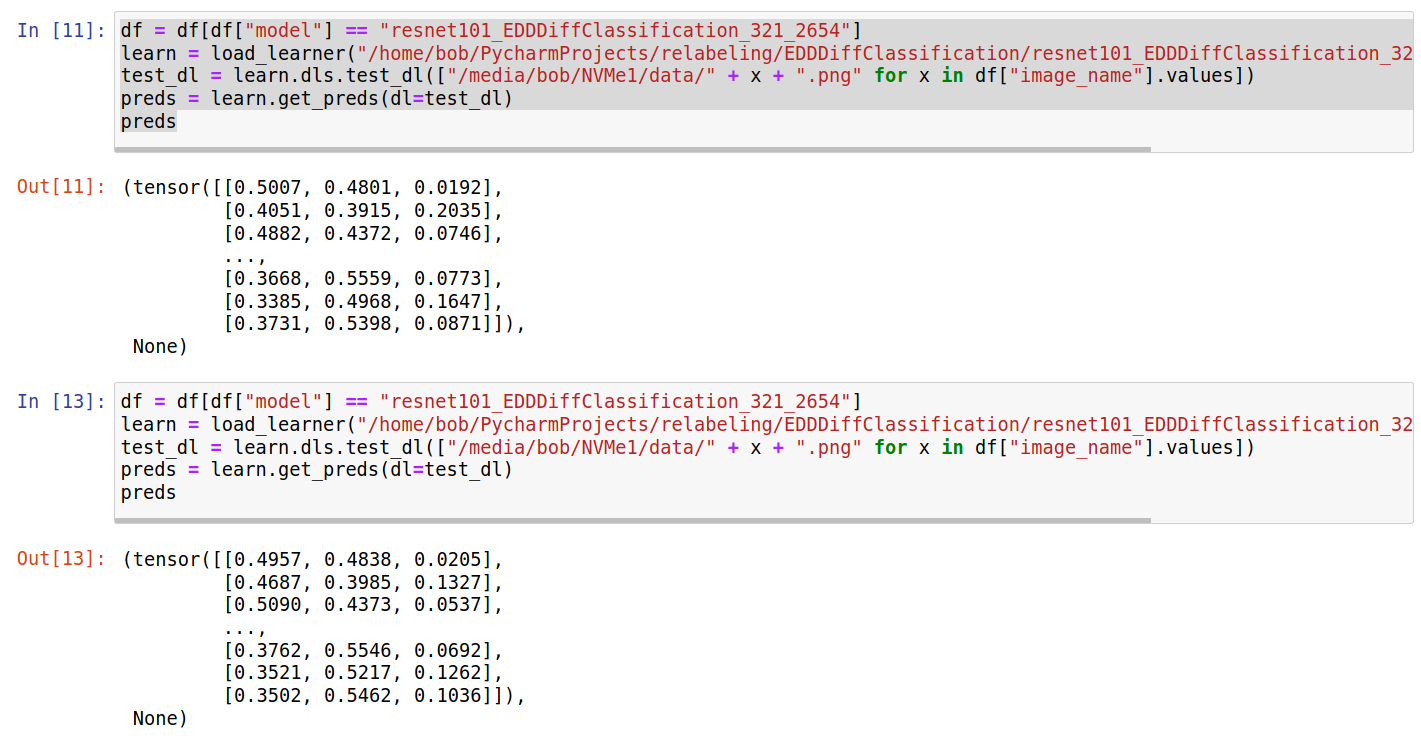
I tried this just to see if maybe dropout was still running or something like that. Still gave different results.
df = df[df["model"] == "resnet101_EDDDiffClassification_321_2654"]
learn = load_learner("/home/bob/PycharmProjects/relabeling/EDDDiffClassification/resnet101_EDDDiffClassification_321_2654.pkl", cpu=False)
learn.model.eval()
test_dl = learn.dls.test_dl(["/media/bob/NVMe1/data/" + x + ".png" for x in df["image_name"].values])
preds = learn.get_preds(dl=test_dl)
predsRunning this code twice also returns different results:
learn.predict("/media/bob/NVMe1/data/" + df["image_name"].values[0] + ".png")
Do you have any callbacks associated with your Learner object?
Here is the entire learner object used:
learn=cnn_learner(dls,
torchvision.models.resnet152,
metrics=[accuracy],
cbs=[ShowGraphCallback]).to_fp16()What version of fastai are you using?
Could you try learn = learn.to_fp32() before performing inference?
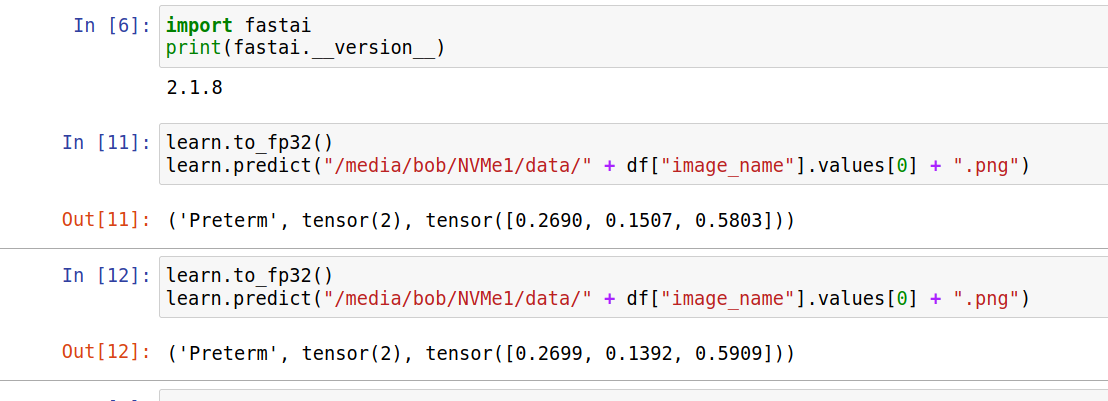
Maybe my training transforms are being run on the test_dl somehow? How do I see which transforms are being run at inference time?
Out of curiosity, can you do the following?
dl = learn.dls.test_dl([what you had for predict])
x, = dl.one_batch()
dl2 = learn.dls.test_dl([what you had for predict])
x2, = dl2.one_batch()
And does x and x2 look the exact same?
Re: transforms, only center cropping (when resize is applicable) and normalizing are performed
They do not appear to be the same. Each time I run it there is a change.
1 Like
It looks like augmentations are being applied at test-time. What augmentations do you have?
In dev at least, I can’t reproduce this. Let me try in your pip version though. This passes:
dls = ImageDataLoaders.from_name_func(
path, get_image_files(path), valid_pct=0.2,
label_func=lambda x: x[0].isupper(), item_tfms=Resize(448),
batch_tfms=[*aug_transforms(size=224)])
learn = cnn_learner(dls, resnet34, metrics=error_rate).to_native_fp16()
dl1 = learn.dls.test_dl([imgs[0]])
dl2 = learn.dls.test_dl([imgs[0]])
x, = dl1.one_batch()
x1, = dl2.one_batch()
test_eq(x,x1)
How are you building your DataLoader? As @ilovescience asked, can we see your full list of transforms?
LOL I just realized I am Normalizing twice, but not sure if that’s my problem.
tfms = [*aug_transforms(size=500, flip_vert=True, max_rotate=45, max_warp=0)] + [Normalize()]
dblock = DataBlock(
blocks=(ImageBlock, CategoryBlock),
getters=[ColReader('image_name', pref="/media/bob/NVMe1/data/", suff=".png"),
ColReader('EDD_diff_class')],
splitter=ColSplitter(),
item_tfms= [mn] + [RandomCrop(350)],
batch_tfms=tfms + [Normalize()])
dls = dblock.dataloaders(df, bs=24)
What is mn?
class AlbumentationsTransform(Transform):
def __init__(self, aug): self.aug = aug
def encodes(self, img: PILImage):
aug_img = self.aug(image=np.array(img))['image']
return PILImage.create(aug_img)
mn = MultiplicativeNoise(p=1, elementwise=True, multiplier=(0.85,1.15))That’s the ticket. That is exactly what is wrong. This is being applied to both the training and the validation set. I would recommend this version from the albumentations tutorial:
class AlbumentationsTransform(DisplayedTransform):
split_idx,order=0,2
def __init__(self, train_aug): store_attr()
def encodes(self, img: PILImage):
aug_img = self.train_aug(image=np.array(img))['image']
return PILImage.create(aug_img)
This one will only apply to the training dataset. (Notice the split_idx)
This version is from here: https://docs.fast.ai/tutorial.albumentations.html#Using-different-transform-pipelines-and-the-DataBlock-API
3 Likes
Dude! You are a genius! Let me run another model and verify, but I’m assuming you are correct here.
With each run is there any data augmentation happening?