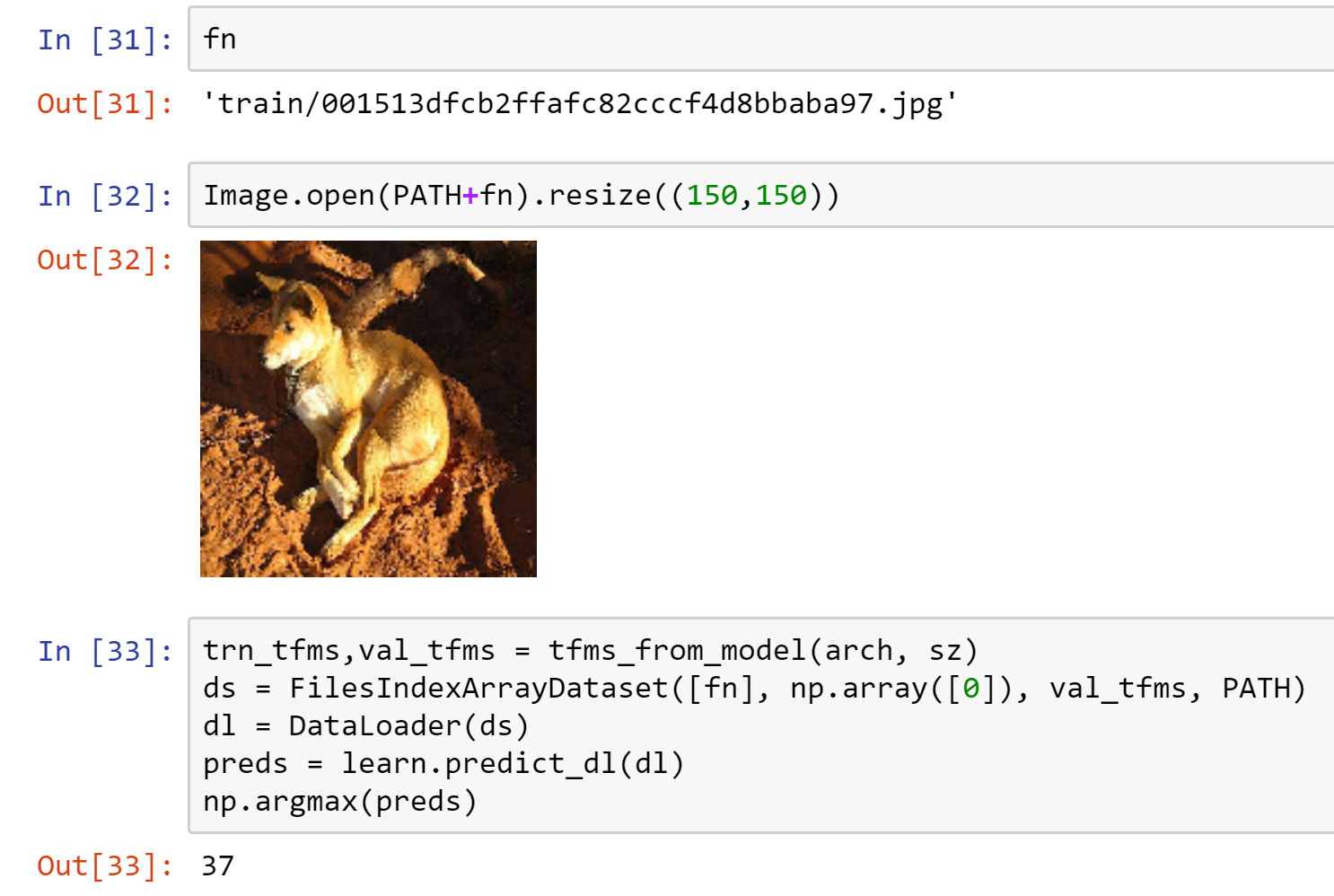
How do we take a image from your file system and use the framework to get a prediction?
I’m assuming we have to transform it into something appropriate, and then pass it into learn.model() … but not sure what transforms are needed and if this is even right.
A little more long winded, but would eliminate any dependencies on the fast.ai framework in production (which might prove helpful if trying to put this in an Android or iOS app at some point):
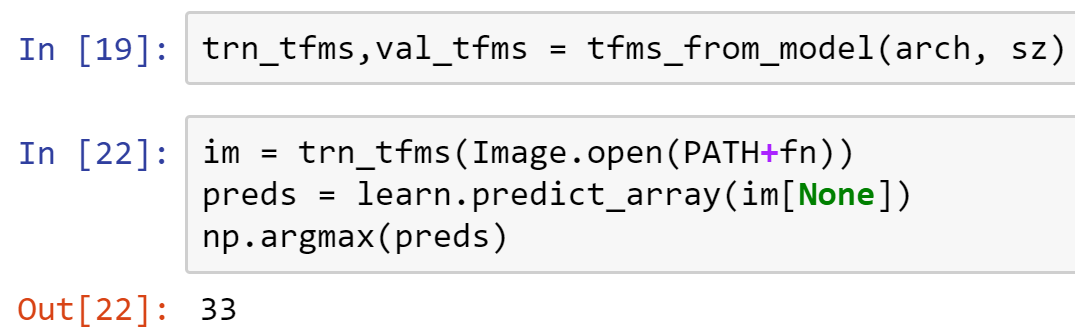
Actually my code isn’t quite right - you should use the 2nd return val from tfms_from_model. The first one includes data augmentation, e.g. for the training set. For predictions you don’t want that, so use the 2nd one.
I have a question regarding image size. If we are using RGB image of size 224, which is also an requirement of ResNet32 then does it mean that the input feature vector for that image size will be of size 224 * 224 * 3 = 150528. And these many input lines goes to CNN.
A silly question which I cannot hold: So if a dataset can have images of different sizes then how the input size of a NN is decided. On basis of what. That’s why we are supposed to bring all images to same size while training?. If this is true then I may have answered my former question.
And this is the code I am using:
trn_tfms, val_tfms = tfms_from_model(arch, sz)
im = trn_tfms(PIL.Image.open(f’data/test/320.jpg’))
preds = learn.predict_array(im[None])
np.argmax(preds)
Protocol buffers Protocol Buffers often abreviated Protobufs is the format use by TF to store and transfer data efficiently. To recapitulate, you can use Protobufs as: An uncompressed, human friendly, text format with the extension .pbtxt A compressed, machine friendly, binary format with the extension .pb or no extension at all
I am semi-familiar with android software and am able to transfer already trained models to my phone but in order for me to use my own trained model I need to be able to save my model in that format. I have been able to save it using tensorflow but it doesn’t work on my phone and its difficult to debug why.
With the in class lessons and forums I have been able to understand your code far better so would be able to debug more effectively hence the need to save in that format.