There are many optimizers available in keras library, so, how do we decide upon which optimizers to use for my particular application. Sometimes Jeremy uses Adam, RMSprop, SGD etc.
So, what are their strength and weaknesses in order to decide optimal optimizer?
1 Like
I switch around in Cats and Dogs between Adam and RMSprop. Everything else being equal my results on the Kaggle board were a little better with RMSprop. Other than that, I don’t have any direct experience to share.
I’m feeling like they are all pretty close to each other and that the things like batch normalization will make a much bigger difference in how quickly your model is able to find the minimum.
I’m interested in what people have to say about this as well.
1 Like
The performance of the optimization algorithms can be seen below. It doesn’t contain Adam but it is faster than the rest of them.
SGD is the slowest and as far as I know, hardly anyone uses it. People in general go for Adam. There is also an improved version of Adam (I think it is Adam+Momentum. Not sure! )
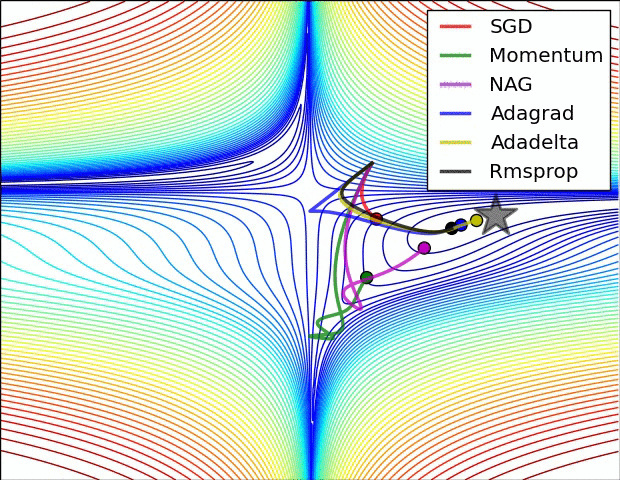
1 Like
It is the search space of the problem. The starting point is where the optimization has begun and star is where the minima is.
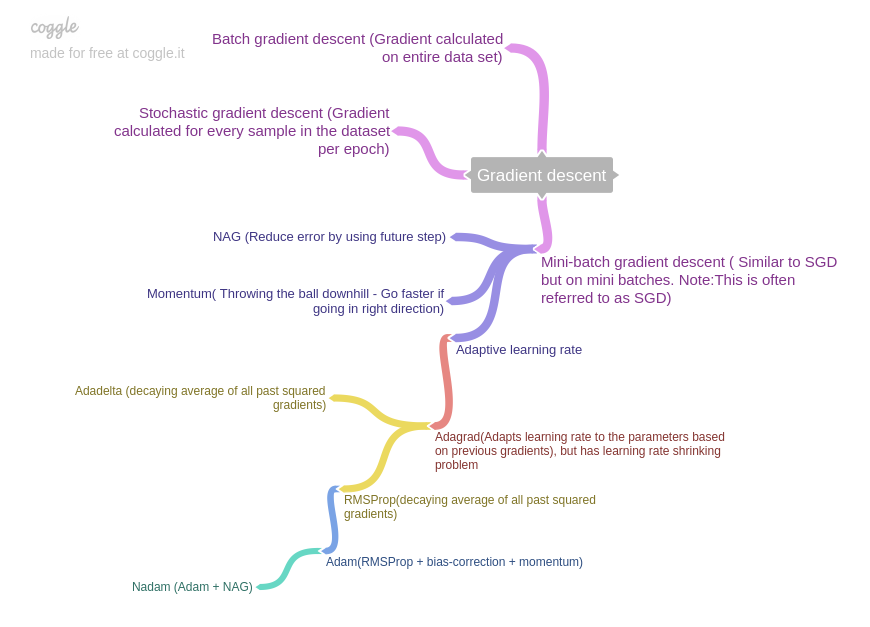
Here is another mind map I created which shows relation between different optimizers. From this, seems like Nadam is the best, but Adam is the most popular right now.
11 Likes
A great chart that helps visualize the progress of the different algorithms. Of course in large n-dimensional spaces there are many “features of the landscape” that could affect how each of them works. I’ve read that some of the algos are designed to be more effective in “ravines” or other features that cause others to converge more slowly.
really gr8 chart