I am working on Porto Seguro winning solution but before going through the final solution all together, rather I am developing this approach step by step. So far I’ve written helper py files which has data construction, models and so on. But I think I have a bug in my attempt of writing a cross validation fit function since my custom gini metric (1 is max) gradually increases and finishes nearly at 1 after each fold training.
I’ve spent some time to understand what might be the mistake that causing this but couldn’t find it. I hope your insights can help me figure this out.
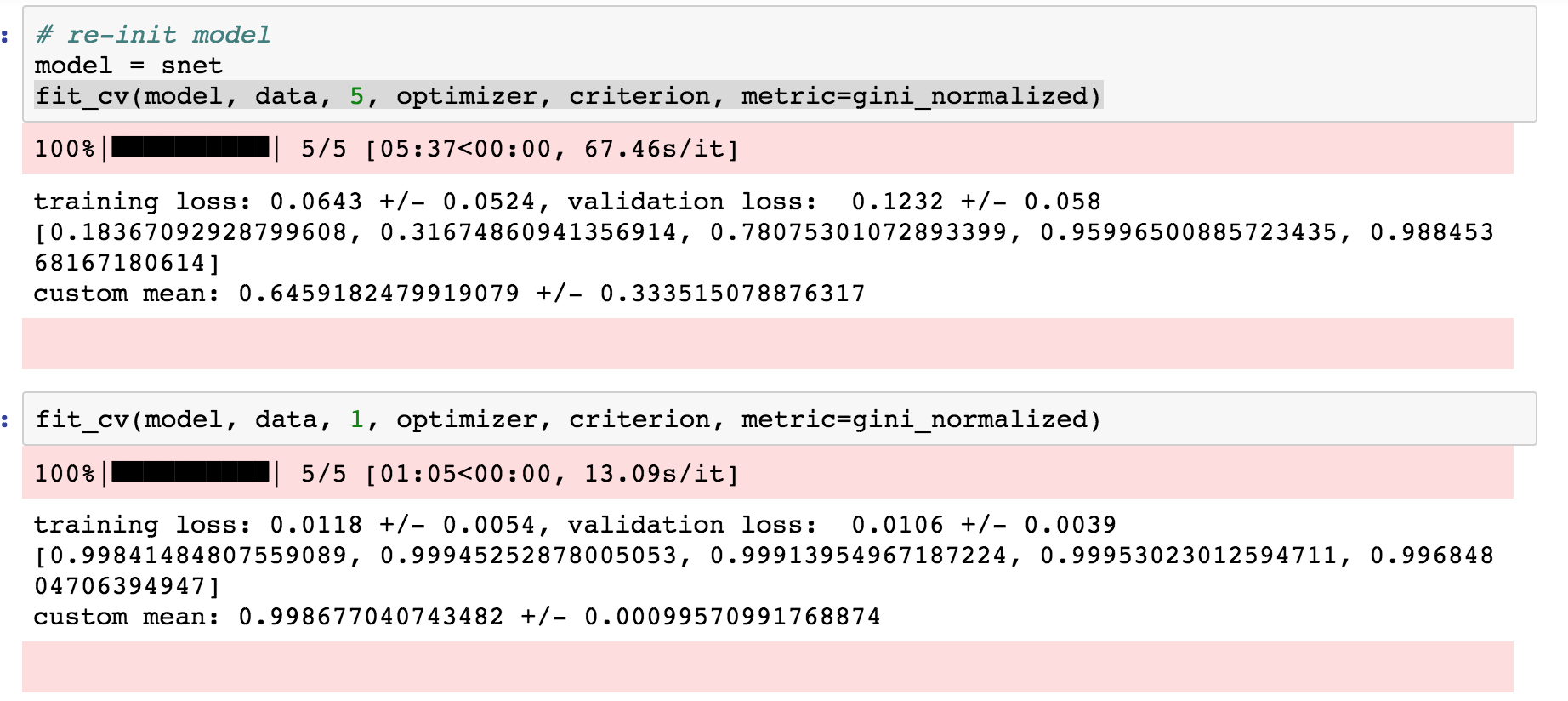
@kcturgutlu - It’s great to see you trying to replicate the winning results. I learnt a lot of doing CVs through your code and trying to look for the error. But I don’t think you have an error. I ran the fit_cv again for 1 Epoch (of all 5 cv) and as you can see, the score stabilized at 99%.
So if you had run for 20-25 Epochs in your original run, you would have seen the scores even around 99% in all 5 CVs. Your initial runs were Under-fitting, that corrected as you ran for more epochs, that’s all.
First, thank you for replying and helping out as always, I really appreciate it. The reason why I am being skeptical about this is that 1 is the perfect score and getting 0.99 increasingly indicates as if each previous fold leaks data into the next one.
Ohh wait…, while I am writing this I’ve noticed the bug… this technique had a name in debugging but forgot it (talking to peers helps a lot in )
During cross validation we are training with folds but eventually our model sees every data point during training. So I should’ve initialized the model weights before each training phase inside cv loop.
Normally, having just training and validation is allowing us to iteratively experiment by running the same fit as many times as we want, but here we should first pick params like lr and epochs before hand and initialize weights before each cv training.
But still need to investigate until being 100% sure…
Yes…The training process does see ALL the data in your method, because it’s the same model being updated in each of CV split. If you truly want to cross validate, you have to re-initialize the model or have 5 Models that are independently trained with their own Train and Validation set that are obtained from CV.
I have not done any CV with Neural Nets myself and mostly have one model and one train-validation split that I try to fit and regularize. So you may want to seek other opinions on this topic
At fastmail.com we had a teddy bear in the office. Before asking for help from a colleague, we had a rule that you had to tell the teddy bear your problem - in the process, you’d often figure out the answer. This was our “help desk teddy”. I know of other companies that have a “help desk rubber ducky”. I don’t know which is better, however, since I’m not sure it’s been rigorously studied.
 )
)

