Hi guys,
Can you help me understand the theory behind my models outcome?
It is a RNN. I am modeling a bioreactor. There are 37 outputs, mainly concentrations of nutrients. The only output that really matters is the concentration of a specific protein (titer). More specifically, the last point of that prediction.
The picture below is the concentration of this protein across 24 bioreactors over time (each curve is a bioreactor).
If I take the epoch with lowest error on protein prediction, it looks like this:
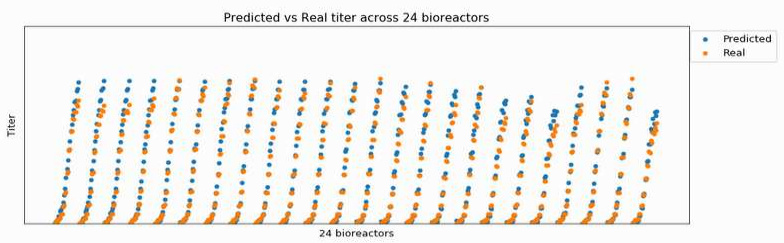
However, as I keep training, my prediction converges to a “mean”, and loses the ability to adjust to each bioreactor, as below.
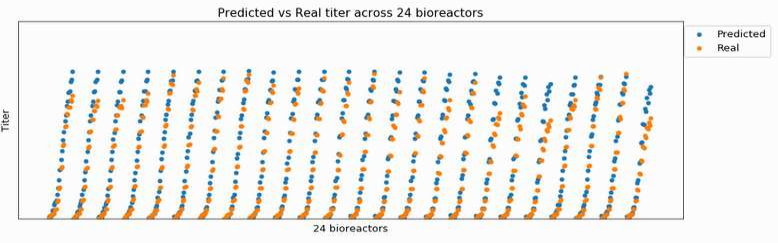
How can I interpret it in terms of bias and variance?
Why overfitting to the train set means that my predictions converge to a mean?
If I had to change the architecture of my NN, should I increase or decrease complexity/regularization?
This is the loss function optimizing all 37 targets:
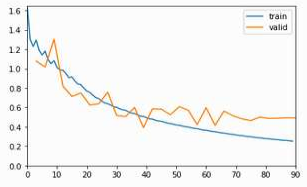
Any inputs are welcome! Thanks in advance!!