I wonder if I should add something in my code to use “better” or “more” my GPU (if it is possible)
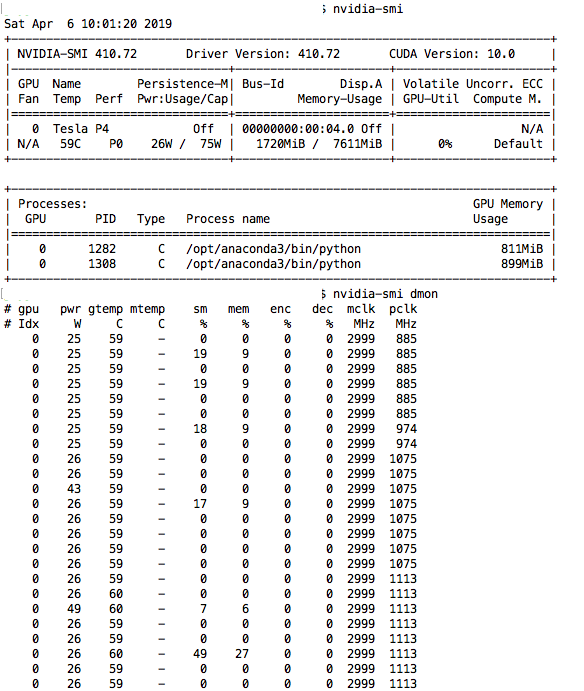
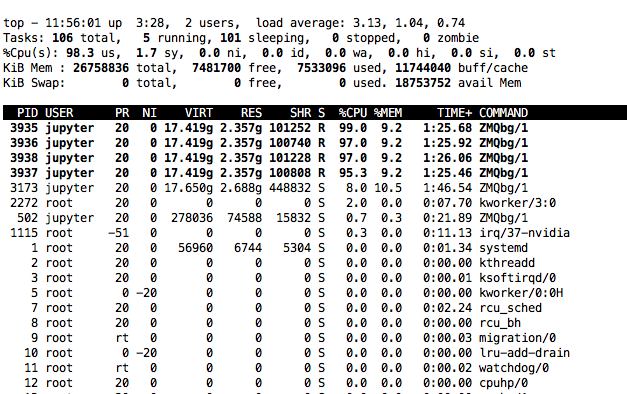
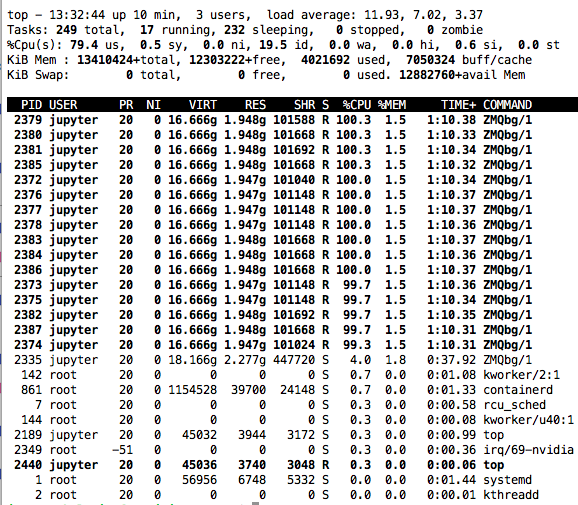
This is screenshot of nivida-smi and nivida-smi dmon while running from a notebook a learner.get_preds on a bunch of 70K images. Isn’t there too many “0” values ? It looks like the script is not using full power of the GPU. Or is it?
Probably not. It is only certain parts of the code that can run on the GPU.
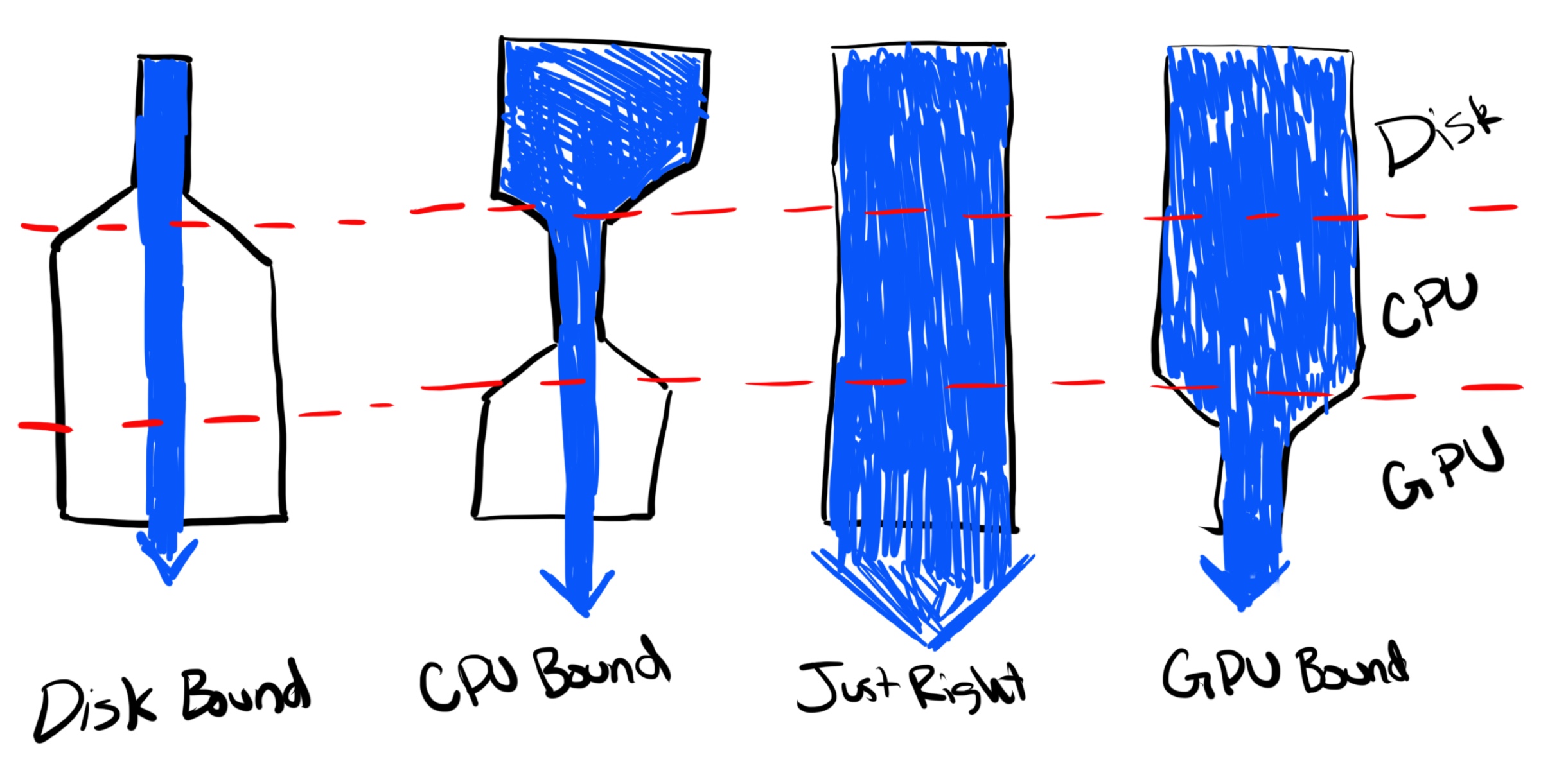
Think of it like a funnel. Each layer of the funnel is only so wide. The CPU feeds the GPU. If the CPU’s width (speed) is narrower than the GPU then it doesn’t matter how big the GPU is, it won’t increase the flow of results coming out of the bottom because your system is only as fast as its slowest part.
Hopefully this makes sense: (the blue is supposed to be your data)
If GPU usage is low and CPU is high you’re probably CPU bound. If GPU usage is high and CPU is low you’re probably GPU bound. If both are low you’re probably disk bound. And if both are high you’re probably just right.
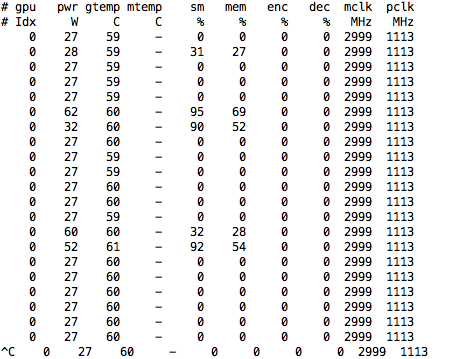
This is interesting. When you were using 4 vcpus your mem util was about 8GB, after upping the cpus to 20 your mem util has actually come down to ~4GB … while 16 out of 20 vCPUs are pegging … your GPU is still not being utilized all of the time.
I’d be interested in knowing what kind of processing can create this type of usage pattern. Seems to me that your CPUs are still working hard while the GPU isn’t doing much “most” of the time.
So, either, the way the work is being parceled out to the GPU isn’t giving it much to work with or the bottleneck is somewhere else … ie in the pathway between the GPU and the CPU
I’m not sure if there is a way to look for queueing on the PCI lanes to see if there’s a backlog there?
What image size are you using? Looking at your numbers, i suspect the image resizing and augmentation operations are bottle necking your cpu. Generally you should not need a 20 thread process to get the most out of your gpu.
If you are using large raw images, a solution is to resize your images to the input size of the cnn (or slightly larger) in a separate preprocessing step.
I am not sure anymore what notebook I was running exactly but image size was either 68 or 128.
and default tfms = get_transforms()
original imsize 1024x750
you recommend to resize the 200k images of the dataset to 128 and save them as 128 on the disk?
(I wouldn’t have. Is that “known” practice to optimize GPU usage? seems weird)