DataParallel is causing me with unet_learner. DataParallel seems to work fine in my other learners.
It looks like it the answer is below, but I don’t understand how I would be able to implement this in the Fast.ai code and unet_learner in particular.
Error Code Below
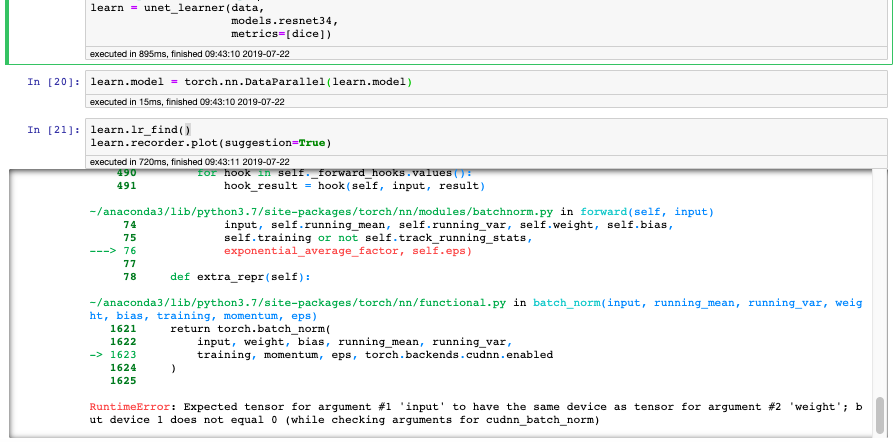
The Model works fine without DataParallel. Here is the whole error.
LR Finder is complete, type {learner_name}.recorder.plot() to see the graph.
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-21-399ce5aa3598> in <module>
----> 1 learn.lr_find()
2 learn.recorder.plot(suggestion=True)
~/anaconda3/lib/python3.7/site-packages/fastai/train.py in lr_find(learn, start_lr, end_lr, num_it, stop_div, wd)
30 cb = LRFinder(learn, start_lr, end_lr, num_it, stop_div)
31 epochs = int(np.ceil(num_it/len(learn.data.train_dl)))
---> 32 learn.fit(epochs, start_lr, callbacks=[cb], wd=wd)
33
34 def to_fp16(learn:Learner, loss_scale:float=None, max_noskip:int=1000, dynamic:bool=True, clip:float=None,
~/anaconda3/lib/python3.7/site-packages/fastai/basic_train.py in fit(self, epochs, lr, wd, callbacks)
198 callbacks = [cb(self) for cb in self.callback_fns + listify(defaults.extra_callback_fns)] + listify(callbacks)
199 if defaults.extra_callbacks is not None: callbacks += defaults.extra_callbacks
--> 200 fit(epochs, self, metrics=self.metrics, callbacks=self.callbacks+callbacks)
201
202 def create_opt(self, lr:Floats, wd:Floats=0.)->None:
~/anaconda3/lib/python3.7/site-packages/fastai/basic_train.py in fit(epochs, learn, callbacks, metrics)
99 for xb,yb in progress_bar(learn.data.train_dl, parent=pbar):
100 xb, yb = cb_handler.on_batch_begin(xb, yb)
--> 101 loss = loss_batch(learn.model, xb, yb, learn.loss_func, learn.opt, cb_handler)
102 if cb_handler.on_batch_end(loss): break
103
~/anaconda3/lib/python3.7/site-packages/fastai/basic_train.py in loss_batch(model, xb, yb, loss_func, opt, cb_handler)
24 if not is_listy(xb): xb = [xb]
25 if not is_listy(yb): yb = [yb]
---> 26 out = model(*xb)
27 out = cb_handler.on_loss_begin(out)
28
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
487 result = self._slow_forward(*input, **kwargs)
488 else:
--> 489 result = self.forward(*input, **kwargs)
490 for hook in self._forward_hooks.values():
491 hook_result = hook(self, input, result)
~/anaconda3/lib/python3.7/site-packages/torch/nn/parallel/data_parallel.py in forward(self, *inputs, **kwargs)
141 return self.module(*inputs[0], **kwargs[0])
142 replicas = self.replicate(self.module, self.device_ids[:len(inputs)])
--> 143 outputs = self.parallel_apply(replicas, inputs, kwargs)
144 return self.gather(outputs, self.output_device)
145
~/anaconda3/lib/python3.7/site-packages/torch/nn/parallel/data_parallel.py in parallel_apply(self, replicas, inputs, kwargs)
151
152 def parallel_apply(self, replicas, inputs, kwargs):
--> 153 return parallel_apply(replicas, inputs, kwargs, self.device_ids[:len(replicas)])
154
155 def gather(self, outputs, output_device):
~/anaconda3/lib/python3.7/site-packages/torch/nn/parallel/parallel_apply.py in parallel_apply(modules, inputs, kwargs_tup, devices)
81 output = results[i]
82 if isinstance(output, Exception):
---> 83 raise output
84 outputs.append(output)
85 return outputs
~/anaconda3/lib/python3.7/site-packages/torch/nn/parallel/parallel_apply.py in _worker(i, module, input, kwargs, device)
57 if not isinstance(input, (list, tuple)):
58 input = (input,)
---> 59 output = module(*input, **kwargs)
60 with lock:
61 results[i] = output
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
487 result = self._slow_forward(*input, **kwargs)
488 else:
--> 489 result = self.forward(*input, **kwargs)
490 for hook in self._forward_hooks.values():
491 hook_result = hook(self, input, result)
~/anaconda3/lib/python3.7/site-packages/fastai/layers.py in forward(self, x)
134 for l in self.layers:
135 res.orig = x
--> 136 nres = l(res)
137 # We have to remove res.orig to avoid hanging refs and therefore memory leaks
138 res.orig = None
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
487 result = self._slow_forward(*input, **kwargs)
488 else:
--> 489 result = self.forward(*input, **kwargs)
490 for hook in self._forward_hooks.values():
491 hook_result = hook(self, input, result)
~/anaconda3/lib/python3.7/site-packages/fastai/vision/models/unet.py in forward(self, up_in)
31 if ssh != up_out.shape[-2:]:
32 up_out = F.interpolate(up_out, s.shape[-2:], mode='nearest')
---> 33 cat_x = self.relu(torch.cat([up_out, self.bn(s)], dim=1))
34 return self.conv2(self.conv1(cat_x))
35
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
487 result = self._slow_forward(*input, **kwargs)
488 else:
--> 489 result = self.forward(*input, **kwargs)
490 for hook in self._forward_hooks.values():
491 hook_result = hook(self, input, result)
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/batchnorm.py in forward(self, input)
74 input, self.running_mean, self.running_var, self.weight, self.bias,
75 self.training or not self.track_running_stats,
---> 76 exponential_average_factor, self.eps)
77
78 def extra_repr(self):
~/anaconda3/lib/python3.7/site-packages/torch/nn/functional.py in batch_norm(input, running_mean, running_var, weight, bias, training, momentum, eps)
1621 return torch.batch_norm(
1622 input, weight, bias, running_mean, running_var,
-> 1623 training, momentum, eps, torch.backends.cudnn.enabled
1624 )
1625
RuntimeError: Expected tensor for argument #1 'input' to have the same device as tensor for argument #2 'weight'; but device 1 does not equal 0 (while checking arguments for cudnn_batch_norm)