I’ve tried classifying papers into single categories. Eventually there was so much overlap between categories that I switched to using multiple tags/keywords.
I found the paper An Embarrassingly Simple Approach for Transfer Learning from Pretrained Language Models to be very interesting:
Here is a 5 minute summary that I’ve written about the paper.
Quick TL;DR:
The authors have shared their approaches of performing Transfer Learning in NLP and with these tricks, they claim to perform better than the ULMFiT approach on a few datasets, specially when using lesser training examples .
Most interesting one was defining an auxiliary loss ,by adding a new layer and also accounting for the orignal loss value
Loss = Loss (Aux) + Loss (LM)
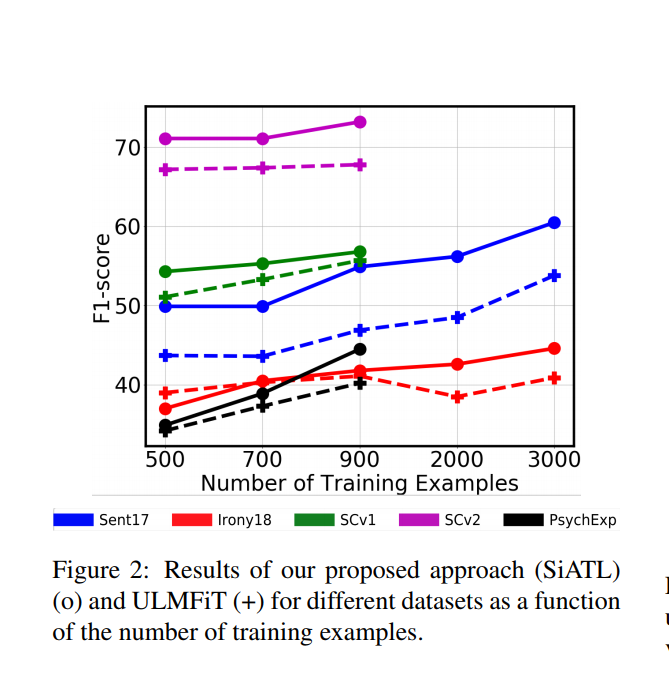
7 Likes
This paper had mentioned an interesting approach of using “Two loss terms” that allowed interestingly better performance.
Thanks to @lesscomfortable who discovered that the Wavenet paper had mentioned an exactly similar method of using two loss values to generalize better

TIL, if you want to do 2 tasks using 1 NN or if you’re doing 1 task using a NN, you can create 2 loss values that you want to optimize and that would lead to better performance!
Edit: Here is the amazing explanation of the “2 loss strategy” by @lesscomfortable: (Copy paste from our slack group, Francisco’s words:)
“I think it’s more about generalizing predictive models. I don’t know if it applies to any model, it seems to be restricted to generalizing predictive series (predict next sound, next word, next stock price etc) to new tasks (classification).
It’s like being less ‘harsh’ when changing tasks. I think about it like 'hey I know that you know how to do this but slowly you will have to use what you know to do that” you’re telling the model ‘take your time to learn’ "
5 Likes
If I remember correctly the RCNN methods are either obsolete or most of what they can do is done better by SSD-type models. Maybe they’re higher accuracy? I saw some Facebook research on detecting faces in crowds. SSDs don’t use the region-proposal part of RCNNs.
There’s a discussion on RCNN/SSD history in the CS231N course, and fastai part2-2018 talks about the SSD-type method too.
EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
5 minute summary link:
The paper investigates 4 “Easy Data Augmentation” Techniques in NLP (!!)
- Synonym Replacement
- Random Insertion
- Random Swap
- Random Deletion
These are tested on 5 text classification data sets, using simple RNN and CNN (yes,CNN) architectures and the authors demonstrate some performance improvements, especially when using “smaller” subsets of training data
4 Likes
Sharing some papers that explore ethics issues of AI. Wanted to post a more comprehensive and better annotated list of blogs and papers, but I really need to stop letting the perfect get in the way of the good.  So here is a start:
So here is a start:
Ethics of AI: #Ethics
| Category | Title / Link | Summary |
|---|---|---|
| General | In Favor of Developing Ethical Best Practices in AI Research | Best practices to make ethics a part of your AI/ML work. |
| General | Ethics of algorithms | Mapping the debate around ethics of algorithms |
| General | Mechanism Design for AI for Social Good | Describes the Mechanism Design for Social Good (MD4SG) research agenda, which involves using insights from algorithms, optimization, and mechanism design to improve access to opportunity |
| Bias | A Framework for Understanding Unintended Consequences of Machine Learning | Provides a simple framework to understand the various kinds of bias that may occur in machine learning - going beyond the simplistic notion of dataset bias. |
| Bias | Fairness in representation: quantifying stereotyping as a representational harm | Formalizes two notions of representational harm caused by “stereotyping” in machine learning and suggests ways to mitigate them. |
| Bias | Man is to Computer Programmer as Woman is to Homemaker? | Paper on debiasing word embeddings. |
| Accountability | Algorithmic Impact Assessments | AI Now paper defining the processes for auditing algorithms. |
8 Likes
https://openreview.net/pdf?id=ryxepo0cFX
Really enjoyed this paper, gives very solid theoretical motivation for their new recurrent architecture called “AntiSymmetric RNN”. Well-designed experiments demonstrate improvements along virtually every dimension of interest over LSTM and GRU (less parameters, faster training, more stability, better end-results).
5 Likes
To Tune or Not to Tune?
Adapting Pretrained Representations to Diverse Tasks
5 minute summary: https://hackernoon.com/to-tune-or-not-to-tune-adapting-pretrained-representations-to-diverse-tasks-paper-discussion-2dabe678ef83
"Quick TL;DR
This paper focuses on sharing the best methods to “adapt” your pretrained model to the target task. (answering the question: “To Tune or Not to Tune?”)
It compares two approaches feature extraction  Vs Fine Tuning
Vs Fine Tuning 
(Yes the authors use emojis!)
There is also a quick guideline for practitioners:
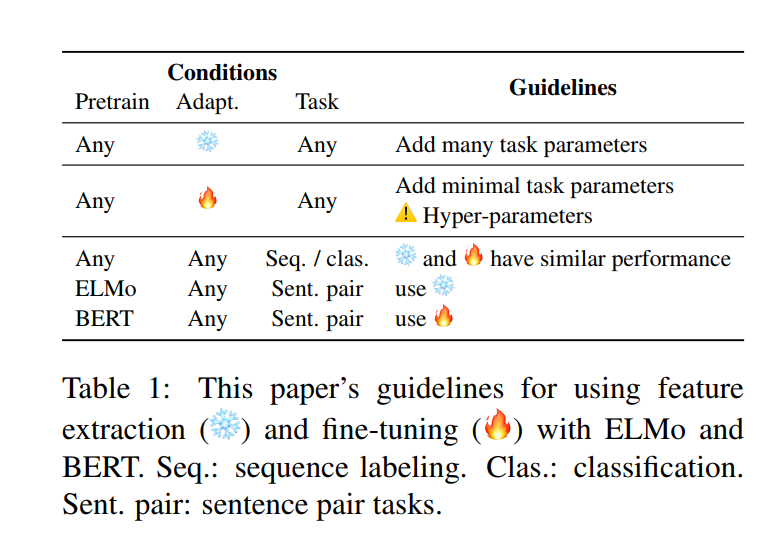
1 Like
#CV
Nice works on GANs:
- In High-Fidelity Image Generation With Fewer Labels", the authors propose a new approach to reduce the amount of labeled data required to train state-of-the-art conditional GANs.
- In Self-Supervised Generative Adversarial Networks authors exploit two popular unsupervised learning techniques, adversarial training and self-supervision, to close the gap between conditional and unconditional GANs.
The DeepMind team also updated the Compare GAN library, which contains all the components necessary to train and evaluate modern GANs.
4 Likes
You can find most of those techniques used by Jeremy here.
It seems that adding Label Smoothing is as easy as setting loss_func = LabelSmoothingCrossEntropy()
4 Likes
Nice 2018 paper discussing how matrix and tensor derivertives manipulation in Tensorflow and Pytorch are or were sub optimal and how to fix the problem.
There is also a nice write up by Oscar Chang on this and other topics here: https://crazyoscarchang.github.io/2019/02/16/seven-myths-in-machine-learning-research/
1 Like
#ADV
Pay Less Attention with Lightweight and Dynamic Convolutions
Authors show that a very lightweight convolution can perform competitively to the best-reported self-attention results. Next, they also introduce dynamic convolutions, which predict a different kernel at every time-step, similar to the attention weights computed by self-attention. The dynamic weights are a
function of the current time-step only rather than the entire context.
2 Likes
Thanks! This is super interesting!
1 Like

Here is a list of SOA for Object Detection, from this video: https://www.youtube.com/watch?v=53YvP6gdD7U
8 Likes
Photorealistic Style Transfer via Wavelet Transforms
This caught my eye the other day. They use wavelet pooling/unpooling for downsampling and upsampling to create more photorealistic style transfer images.
6 Likes
Generalised IOU. A Metric and A Loss for Bounding Box Regression. Solving, “It would be nice if IoU indicated if our new, better prediction was closer to the ground truth than the first prediction, even in cases of no intersection”
3 Likes
T-Net: Parametrizing Fully Convolutional Nets with a Single High-Order Tensor
From the abstract:
Authors propose to jointly capture the full structure of a neural network by parametrizing it with a single high-order tensor, the modes of which represent each of the architectural design parameters of the network (e.g. number of convolutional blocks, depth, number of stacks, input features, etc). This parametrization allows to regularize the whole network and drastically reduce the number of parameters.
They also show that their approach can achieve superior performance with low compression rates, and attain high compression rates with a negligible drop in accuracy, on both the challenging task of human pose estimation and semantic face segmentation
5 Likes
Very exciting new paper “Unsupervised Data Augmentation” just out today, if the claims are accurate  Works with all types of data including text and images.
Works with all types of data including text and images.
On the IMDb text classification dataset, with only 20 labeled examples, UDA outperforms the state-of-the-art model trained on 25,000 labeled examples. On standard semi-supervised learning benchmarks, CIFAR-10 with 4,000 examples and SVHN with 1,000 examples, UDA outperforms all previous approaches and reduces more than 30% of the error rates of state-of-the-art methods
Just want to add to this one that the concept introduced here of Training Signal Annealing (TSA) is also a really interesting idea to effectively remove the contribution to the gradients of examples in the dataset that the model is already classifying correctly above some threshold while this threshold gradually decreases starting from 1/num_classes to 1.
13 Likes
I found the experiments from Deconstructing Lottery Tickets: Zeros, Signs, and the Supermask interesting:
https://eng.uber.com/deconstructing-lottery-tickets/
The authors found that after training the LT networks, preserving the signs of weights and keeping the weights that are away from zeros using the supermask can draw out good performance (80 percent test accuracy on MNIST and 24 percent on CIFAR-10) without additional training.
1 Like
How Does Batch Normalization Help Optimization?
Batch Normalization controls the change of the layers’ input distributions during training to reduce the so-called internal covariate shift. The popular belief is that its effectiveness stems from that. However, the authors demonstrate that such distributional stability of layer inputs has little to do with the success of BatchNorm. Instead, they uncover a more fundamental impact of BatchNorm on the training process: it makes the optimization landscape significantly smoother.
1 Like