I’ve written a model for fake news classification with the use of text_classifier_learner. When I use a subset of 800 fake and 800 real news items(learn.fit_one_cycle(5)), however I end up getting either one single value of accuracy that repeats itself over multiple cyc_lens. For example, the output for the code in question looks like this:
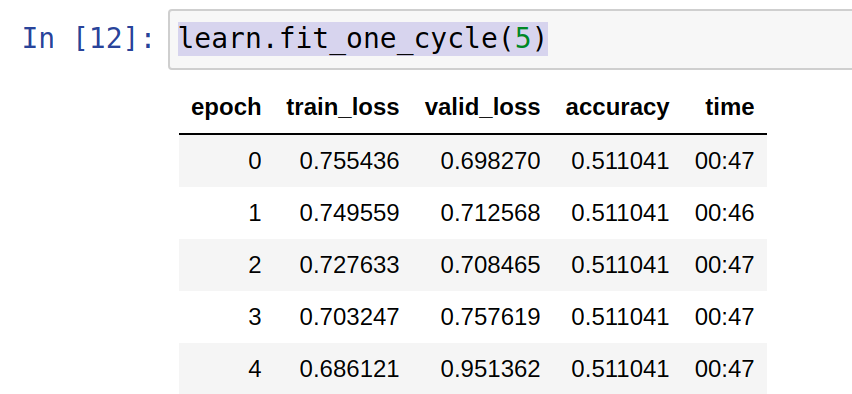
When I increase the valye of cyc_len to above 10, I see the same phenomenon, only this time, instead of one single value that repeats, it’s 2-3 different accuracies that repeat in batches.
However, when I increase the count of news articles to 21k+, then the accuracies are independant in the sense that they don’t repeat. However, even in this case, the accuracy swings wildly. It starts at 60, then keeps going down to 60 and up to 90 randomly.
I’m guessing there’s something super basic I’m missing here, and any leads would really help!
A few portions of my code that may be important:
`learn = text_classifier_learner(data, AWD_LSTM, drop_mult=0.5)`
full_train=full_train.dropna() data = (TextList.from_df(df=full_train, path=curr_dir, cols=2) .split_by_rand_pct(0.2) .label_from_df(cols=3) .databunch())
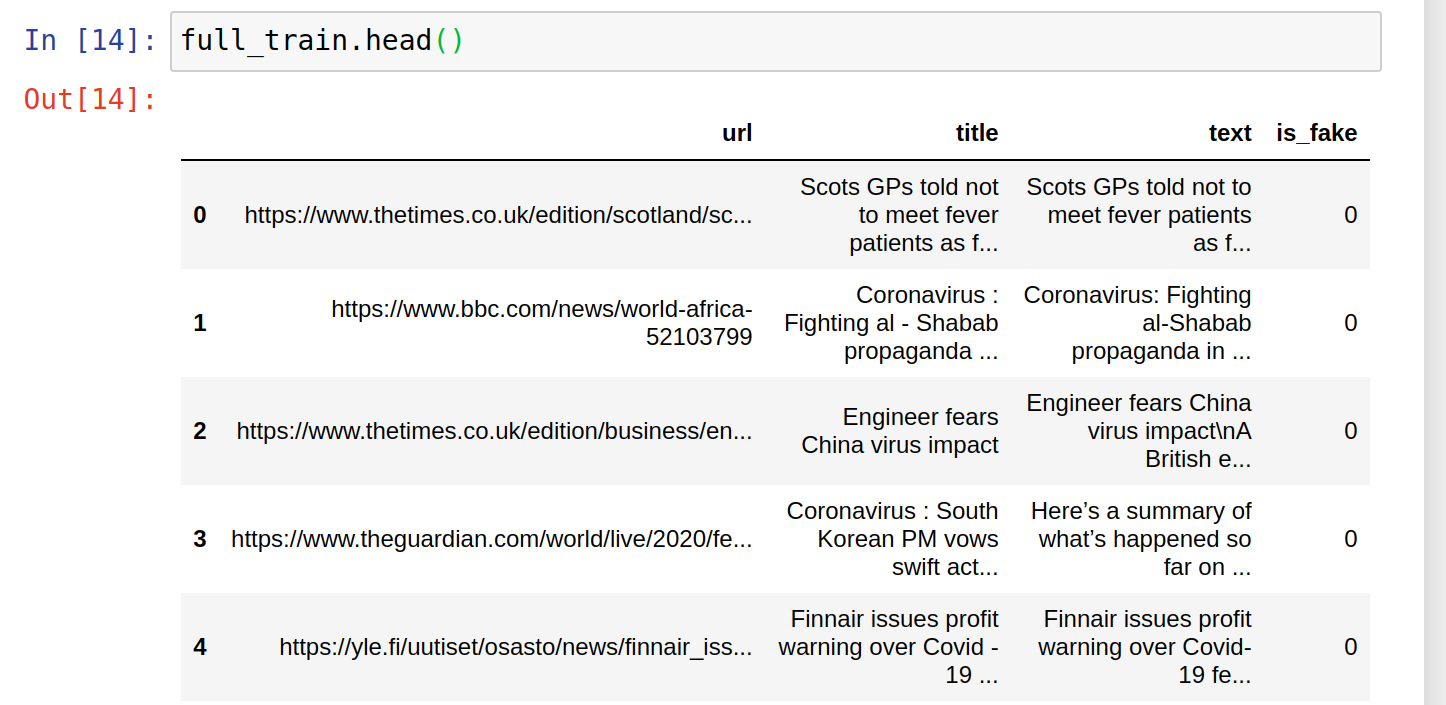
Any help would be appreciated!