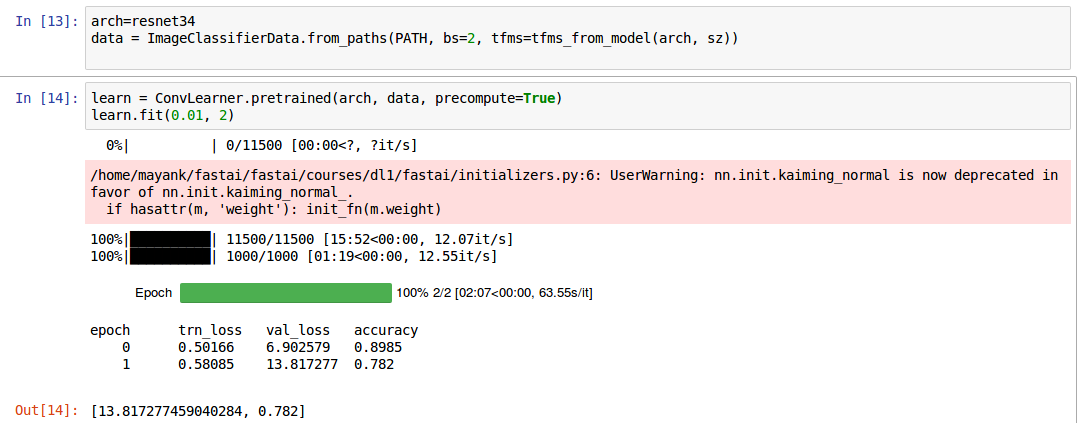
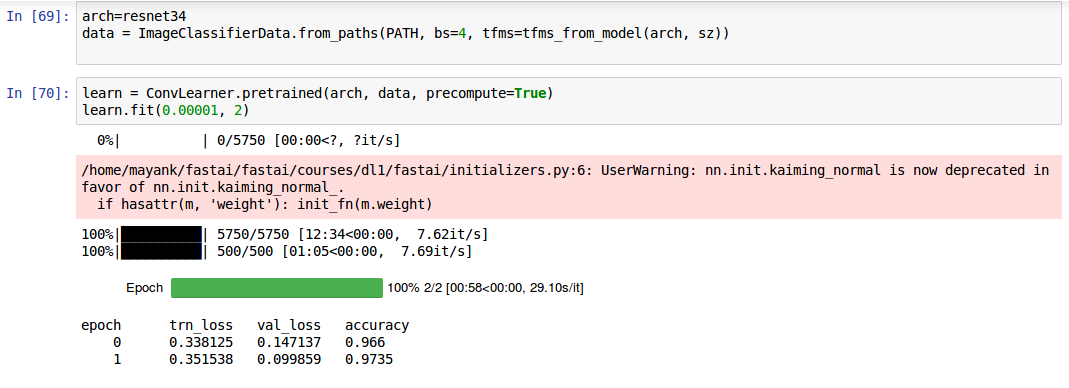
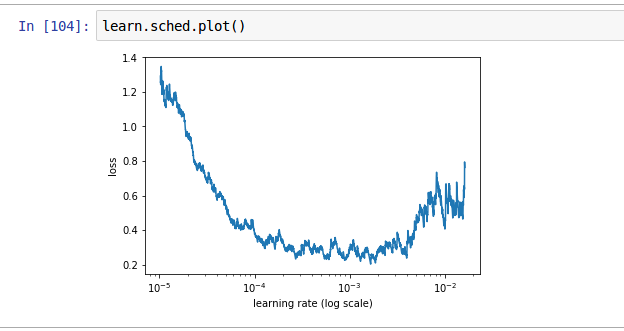
Hi! I’m a new learner and after 3 days of effort installing linux and setting up the environment to run fastai, I just managed to complete the dogs/cats training in Lesson 1. However, I’m getting very low accuracy and very high training and validation losses compared to the lesson video and what I’ve seen around the forum.
Here’s the results I’m getting:
One major thing I’ve done differently is that my GPU(Nvidia GeForce 940MX) is not supported by Pytorch’s precompiled binary, so I built it from source. That fixed the issue.
I was also getting out of memory issue with the default batch size, so I decreased it to 2 and restarted the jupyter notebook (I can increase batch size to 4 or 6 safely considering bs=2 used 500MB and I still have 1.3GB left in the card).
Could the very low batch size be contributing to my low accuracy and high losses?
To fix this, I changed my learning rate from 0.01 to 0.00001.
After I ran the lr_find() functon, my graph looked terrible. There were too many spikes in loss, but following the video instructions I chose the learning rate as 1e-5
(The original graph looked like this, but the loss spiked by ±0.2 throughout the learning rate.)
You did the right thing, you will want to decrease your learning rate with your batch_size, as it is much noiser. Your GPU should be now supported with PyTorch 0.4.0, mine is 930M. The support was gone for 0.3.1 and back with 0.4.0.
This is high variance problem.That is you are over-fitting you model.
Few things i suggest it.
Try early stopping
Add l2 regularizer
Add batch normalization
Reduce lr rate
Add dropouts.
Gotcha.
It’s great news that they’re supporting older GPUs again with 0.4.0 onwards - not everyone can afford the latest GPUs.
Is my understanding about learning rate vs batch size correct? I think it’s -
If the batch size is higher, there’s more images being processed at the same time, so the network can learn faster as it has more reference points.
If the batch size is lower, then less images are being processed at the same time, so the network has to learn slower in order to remove bias caused by the small sample(batch) size?
Other than reduce lr rate and over-fitting the model, I didn’t understand any of the other things
I just started learning and I’m on the first lesson. I hope I can figure out what the other things mean with time.