Validation loss much higher than training loss at first epoch means either you have any issue with your model parameters or you haven’t properly setup the train/validation split. This could also happen when validation set have data that is not in train set or vice-versa.
2 Likes
If you have already split your image data into a train_df and valid_df how do you create a split using that with data_block? I need to do this because then I can modify (duplicate) train_df and still have separate valid_df which is untouched.
I think you can pass valid_df directly in split_from_df  (I am not sure though, I might need to dig into the code)
(I am not sure though, I might need to dig into the code)
If I have only one df and I modify it and then take random sample for valid_df it will probably get some of the modified images.
If you do it once then you will not mix up the data but if you are doing it more than once in your code then you might mix data.
Just a thought. If we could collect around 200 samples of learning rates and label them, we could use Image classification to automate the learning rate finder
2 Likes
If you want to start some group I’m more than happy to send some pictures for you.
I was training my model and noticed this. Can anyone tell me what it means?
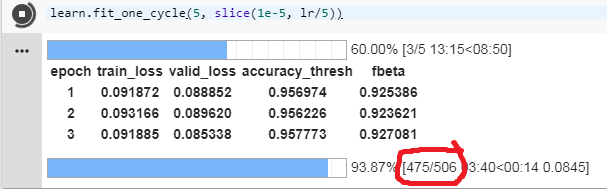
1 Like
Looking at the source code I was pretty sure it was the number of batches (so number of batches processed / total number of batches, for each epoch).
It seems to be the case : with the lesson1-pets notebook, here’s what it looks like for the training :
![]()
And here’s the size of the training and validation data sets (with a batch size of 64) :
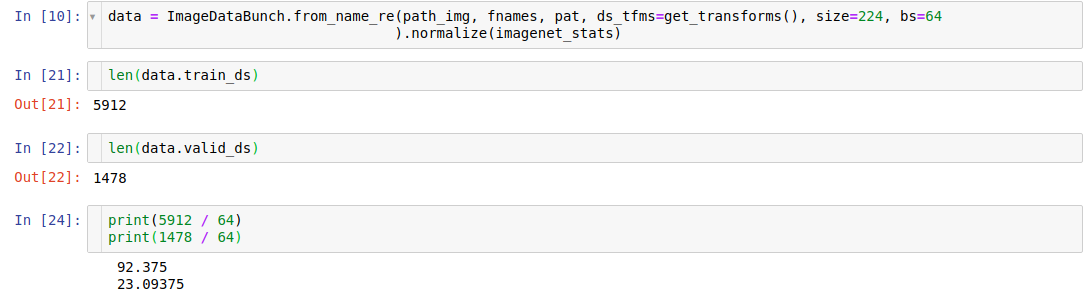
But I noticed something weird for the validation, because it shows up as 16, not 24 as I would have expected given the above :
![]()
So maybe the size of the batches are a bit bigger when the model is in evaluation mode because there’s no need to do backpropagation (thus no need to compute and store the gradients) ? If that’s the case I would be curious to know how’s the validation batch size is calculated
EDIT : I found it, the validation batch size is indeed different and is calculated with val_bs = (bs*3)//2, that makes sense :
Not really sure where’s that formula coming from though
5 Likes
while deciding the learning rate how is the learning rate 3e-5 vs 1e-5 ? what’s the multiple based on?
1 Like
Has anyone noticed a sharp drop in private-leaderboard score for resnet34 on planet when training further, beyond what’s in the lesson3-planet notebook? I noticed, twice now, if I train for multiple cycles instead of about 1 per stage per size, I get scores around 0.3 to 0.5 with a 0.3 threshold – even though my fbeta validation score is around 0.93. When I don’t train extra cycles, I get kaggle scores in the 0.9’s.
I wonder if this has to do with further training early on in finetuning the model – after the first cycle, you can bring down the training loss quite a bit without improving the validation loss appreciably – perhaps this narrows the search space of the model so later training becomes a bit handicapped in what it can do.
Or maybe I did some silly error somewhere – but it’s odd that it’s happened twice. Also maybe: perhaps that further training makes the model more confident in predictions – so the thresholding needs to be adjusted further before submission – but I am using an accuracy threshold metric set to 0.25, so that shouldn’t be it.
edit:
maybe you’re not supposed to run one_cycle multiple times or something? Instead, just use a longer cycles? I just got my 4th highest-ever score on planet, with the 20% validation-set hold-out, by using cycles of length 6 instead of 4 or 5… though at this point I wonder how far into statistical noise I am…
– also, I was trying out refreezing layers after unfreezing all, and finetuning that way. So far it hasn’t worked (although, and the odd thing about all this is, the loss and accuracy metrics never looked off, they just didn’t really improve … and then the test predictions just did terribly. interesting…)
edit 20181125:
I think I found what was killing performance:
In the image below I do an index-to-class mapping from the leard.data.c2i class-to-index dict. Cells [7] and [20] are both run afer initializing a new learner… the class-index one-hot mappings change…
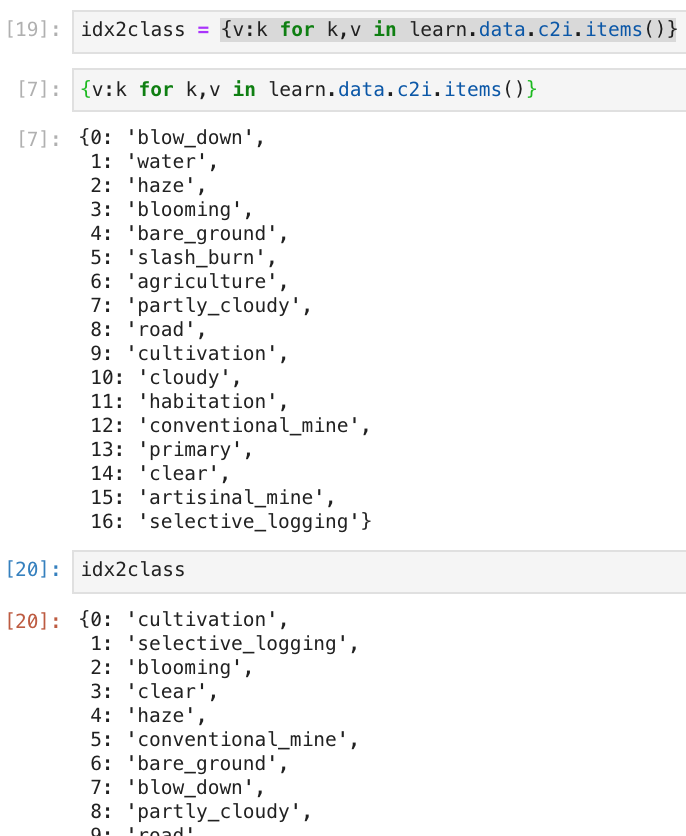
I tried testing when this happens, looks like whenever you start a new kernel you get a different mapping, even if you use np.random.seed(0) before setting up the data. I think I managed to get 2 different mappings within a single kernel session, but I wasn’t able to replicate that.
Loading the learner that created a set of predictions learn.load('...') does not change the mapping in learn.data.c2i.
This feels like something that can very easily trip someone up. @lesscomfortable or anyone: is it supposed to work this way or am I doing something wrong? Best I can imagine right now is to save the mapping dict along with a model or predictions, and reload them when you want to use an old model.
→ just a note, looks like this only happens when you restart your kernel. I did a bunch of tests and that’s the only thing that resulted in a different learn.data.c2i.
2 Likes
Your explanation for the batch size for validate set is correct. It is mentioned in the 001a_nn_basics that:
We’ll use a batch size for the validation set that is twice as large as that for the training set. This is because the validation set does not need backpropagation and thus takes less memory (it doesn’t need to store the gradients). We take advantage of this to use a larger batch size and compute the loss more quickly.
2 Likes
Thanks ! Any idea where the “twice as large” or, as it’s currently implemented in the fastai library, 1.5 as large is coming from ? It just works or is there an explanation ?
I’m not sure but might be 1.5 to guarantee it won’t use over memory. The library is updated so there are some parts that are not coherence with the dev notebook
I’m finishing testing, but I’ll soon push a change were classes will always be sorted if created from the labels (and not passed by the user). That should solve this tricky issue.
2 Likes
 hope to submit little fixes like that myself in the near future but in the meantime thanks!
hope to submit little fixes like that myself in the near future but in the meantime thanks!
the lesson 6 video seems to be not available now?
How can I get to it?
Looks like we are going to need a bigger test. https://nnabla.org/paper/imagenet_in_224sec.pdf It is all relative I guess, but a mini batch size of 68K doesn’t sound that mini. It just shows how SOTA has changed that 75% was the target accuracy when it used to take over a day.
A new link is posted to the edited down version - https://www.youtube.com/watch?v=U7c-nYXrKD4&feature=youtu.be
Hello. I’m trying to implement a siamese network with triplet loss for facial recognition using fastai-v1. I could figure out how to give a custom head for a pre-trained resnet network to get an “embedding” of sorts for the images. But I’m unable to figure out how to pass the loss function. I need to pass the loss function involving 3 outputs from the same network. I’m clueless as to how to proceed.
Any help / direction will be much appreciated, thank you!
1 Like
A thought popped up. Do you think Jeremy’s “change the learning rate between layer groups by 2.6” works because he experimentally discovered e (~2.7) ?
ie: a ‘natural’ scaling between layer groups? I mean, you see log-this and log-that everywhere in deep learning, so…?
2 Likes
Number of batches (i.e) size of training dataset/batch size