How do we fetch the list of filenames from our dataset with the new updates to the library?
I’m running on planet-amazon. 10 days ago I was able to just call:
idx2class = {v:k for k,v in learn.data.train_ds.ds.class2idx.items()}
to convert class indices back to class-names, and:
fnames = [f.name.split('.')[0] for f in learn.data.test_ds.ds.x]
to get the filenames. But the .data.<xyz>_ds no longer has the .ds attribute I was using.
I checked the changelog and searched around the forums, but anything I found was from about a month ago. I’ll edit this post with the answer if I find it.
edit:
so looks like you can call:
learn.data.train_ds.x.items
to get the list of filepaths (and also for .valid_ds and .test_ds).
Is this the ‘right’ way to do it? And is this guaranteed to match up with predictions on the validation and test sets?
edit2:
Think I found how to get your class-to-index mapping:
learn.data.train_ds.y.c2i
It’s gotten more intuitive: (“where can I find filenames?” → take a look at where the data comes from: .<blah>_ds.x.<blah>; “where can I find how classes are one-hot encoded?” → look where the labels are stored: <blah>_ds.y.<blah>
unfreeze() function generally unfreezes all layer. I could not locate any fast.ai function which allows me to unfreeze last x layers and not all the layers…Can anyone please help me on this?
Why my validation loss is much higher than training loss even in first epoch? I though this is our goal but what I’m doing wrong when this is happening first epoch. Second epoch valid loss decrease a little bit faster than train loss.
Difficult to answer without more info but it could be that by chance the pretrained weights performe better on the training set than the validation one. Shouldn’t happen with a large enough and well chosen validation set though. It also could be that the model had already seen some of the training data, because you already trained on it or some of the data the pretrained weights was trained on is also in your training set.
To be clear, having a validation loss much higher than the training loss is not the overall goal, because that means you’re overfitting (so not generalising very well).
[quote=“Lankinen, post:245, topic:24987, full:true”]
Why my validation loss is much higher than training loss even in first epoch? I though this is our goal…[/quote]
No, our goal is to build an accurate model that generalises well. In lesson 2 Jeremy explained that if you start out with a very high validation loss, you may want to take a look at your learning rate, as it may be too high.
Well if that’s the first time you train the model on this data I don’t really get why you would start by overfitting. Did you use the learning rate finder and the one cycle policy ?
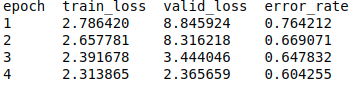
Depending on your data 60% seems like a high error rate.
Yeah, I use learning rate finder before this and one cycle policy. 60% is actually pretty good at this problem but if I’m doing something wrong then it might get even better results. Could it somehow be plausible that valid_loss should be train_loss and vice versa?
I don’t think fastai would have such a big bug
I don’t really know what’s going on apart from what I already suggested and without a closer look at your notebook / your data
I have done the modelling and validation also. Now there are hundreds of image with their image id and i need to classify them as test data. I could not locate any function from fast.ai to send as image data bunch and get classification result with object id name…May be i am missing something…Can anyone please help me on this?
Just wanted to share that I’ve found that watching the videos multiple times has been super helpful.
I watched all 5 videos once. (Super overwhelmed, but continued nevertheless)
When I got back to watching from video 1 again, its almost like the brain had enough time to let everything watched simmer, and it was MUCH easier to register and understand.
So in case anyone is finding things overwhelming, I’d recommend spaced repetition.
Your brain is a neural network as well , so more repitions, more layers, more epochs, better learning.
I am trying to train a deep learning model. I am getting following error while running learn.fit_one_cycle(4):
RuntimeError: Traceback (most recent call last):
File “/opt/conda/envs/fastai/lib/python3.6/site-packages/torch/utils/data/dataloader.py”, line 138, in _worker_loop
samples = collate_fn([dataset[i] for i in batch_indices])
File “/opt/conda/envs/fastai/lib/python3.6/site-packages/fastai/torch_core.py”, line 92, in data_collate
return torch.utils.data.dataloader.default_collate(to_data(batch))
File “/opt/conda/envs/fastai/lib/python3.6/site-packages/torch/utils/data/dataloader.py”, line 232, in default_collate
return [default_collate(samples) for samples in transposed]
File “/opt/conda/envs/fastai/lib/python3.6/site-packages/torch/utils/data/dataloader.py”, line 232, in
return [default_collate(samples) for samples in transposed]
File “/opt/conda/envs/fastai/lib/python3.6/site-packages/torch/utils/data/dataloader.py”, line 209, in default_collate
return torch.stack(batch, 0, out=out)
RuntimeError: invalid argument 0: Sizes of tensors must match except in dimension 0. Got 320 and 180 in dimension 2 at /opt/conda/conda-bld/pytorch-nightly_1542185950098/work/aten/src/TH/generic/THTensorMoreMath.cpp:1319
I have used labels from csv file, and images are in one folder. Image name has one specific label. It returns the images with ‘data.show_batch(rows=3, figsize=(7,6))’. While training I am getting error

 , so more repitions, more layers, more epochs, better learning.
, so more repitions, more layers, more epochs, better learning.