I’m running into the following situation quite often: I train a model with fit_one_cycle, the losses are nicely improving, but after I finished all epochs, I have the sense that I can keep training the model. And very often when I keep training it, the loss still improves nicely.
I’m wondering if others had similar experiences. What learning rate (and momentum) schedule do you use after the initial fit? Do you just call fit_one_cycle again with a lower lr? Do you fit using a low constant rate? Do you fit with a just the decreasing part of the schedule?
I thought now that we arrive at the fitting part of the course, it’s a good place to ask this question. I searched existing forum topics, didn’t find anything. Feel free to redirect me if it exists.
I think this is the important part - it is a matter of trial and error and finding what works for you. I also sometimes second guess myself and would train with one cycle and then rerun the training with manual LR annealing. Part of the reason is that the situation will be different from dataset to dataset and sometimes it can be quite hard to find optimal hyperparameters (lr, div_lr, number of epochs) especially with something as finicky as Adam.
It is also true that once I know what performance to aim for, I can usually find a good set of hyperparams to achieve an even better performance with one cycle and with a reduced number of epochs.
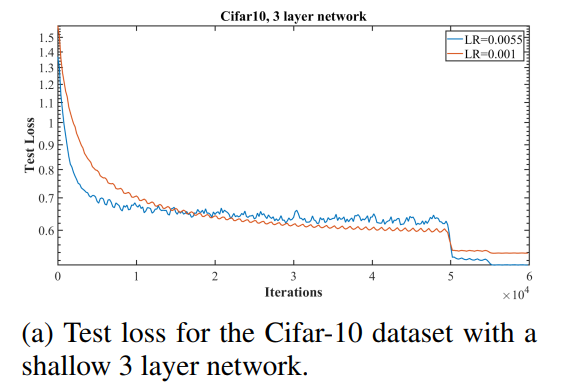
As a related observation, the key to taking full advantage of one cycle is to make sure that the network stays in the zone where it is just about to diverge for as long as possible. This is nicely evident in the loss graph (where first the loss decreases and than levels off or maybe even slightly climbs before taking a plunge again - the middle section should be as pronounced as possible).
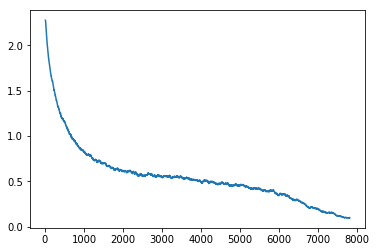
I am sorry I don’t have such a graph around and don’t have an easy way of producing it at the moment. I looked on my github and I found this which is not too far from perfect:
This was quite a tweaked training regime so this should be a decent loss curve, but what would make it probably even nicer is if the middle section was more horizontal or slightly slanting upwards. This is coming from training on cifar10 from a while back, so maybe the fact that I was training from scratch and that I aimed to minimize the number of epochs played into the ultimate shape.
Also, one other observation - empirically, setting gradient clipping to 1e-1 seems to work really well, especially when using some form of SGD (probably due to there not being a mechanism that would balance the relative size of the steps in various dimensions, so the big steps get really, really big with high lrs).
I feel there are no easy answers here I find one cycle is great to get you running if you are getting started and than it is superb once you are going for the extra ounce of performance. But for the middle ground where you just want to get decent enough performance and move on knowing that you have to a good approximation trained the network fully - well, this is a tall order. Especially if you have an inclination like myself to train for as short duration of time as possible Might be that firing off one cycle and training for a really, really long time (as in, overnight) would be another viable option (I am not too concerned of overfitting since using any architecture with batchnorm and potentially combined with dropout overfitting is very hard to do).
As a side note, the above is full of (at least to me) unverified hypotheses (such as the thought on why gradient clipping seems to work really nice with high lr SGD) but still thought I’d share as at least empirically the approach above seems to be working quite well.
There is some range of values for the LR where the model is just on the brink of diverging - for one cycle to work well you want want to train your model with an LR from that range for quite some time.
That would be at least my understanding. Problem is that prompted by your question I looked at a paper by Leslie Smith, the inventor of the one cycle policy and in it the author makes a similar claim but with regards to the loss but on unseen data…
Here the training was performed with a fixed LR decay schedule. I am not sure if this argument translates exactly to the shape of the training loss like in the plot I added to my original post.
It has been a while since I read those papers (all the papers by Leslie Smith are a great read!) and I also feel that some of what I wrote might not be accurate and might be overcomplicating things.
In reality, there is no secret formula - that should have been my main message. The papers are great and what they speak to among other things is to the value of training with a high learning rate for longer and not relying on the heuristic that if we see the training loss decrease we are in a good spot (we want generalization performance, not performance on the train set!). For many more nuggets of wisdom please consult the literature linked to above
But for all practical purposes, I either decay the LR manually when it seems like the model is ready for it (an approach I am fond of with Adam) or I train with an absurdly high learning rate, gradient clipping and the great fastai defaults using one cycle and probably preferably SGD… Though I now have an Adam phase in my life again so that statement is also not entirely correct…
Now, to completely throw everything I said out the window, I did run an experiment recently when working on a project involving CNNs… I first decayed the LR manually… and then proceeded to train using one cycle (separate runs, training from the beginning). Of course I assumed I would get better results if I messed with the hyperparams…
And guess what? All I had to do is run the training for a modestly high number of epochs (something like 1/3rd of the number of epochs I trained with manual annealing probably, or fixed piece-wise constant LR schedule IIRC the name of just decreasing the LR manually from the papers :D) and the best results that I got were… with fastai defaults and using my goto LR for starting to train with Adam, that is 1e-3…
So there we go. Read what I wrote above for (mild) entertainment value and other than that go train your networks using the defaults and the one cycle policy, but just make sure you train for long enough!
 I find one cycle is great to get you running if you are getting started and than it is superb once you are going for the extra ounce of performance. But for the middle ground where you just want to get decent enough performance and move on knowing that you have to a good approximation trained the network fully - well, this is a tall order. Especially if you have an inclination like myself to train for as short duration of time as possible
I find one cycle is great to get you running if you are getting started and than it is superb once you are going for the extra ounce of performance. But for the middle ground where you just want to get decent enough performance and move on knowing that you have to a good approximation trained the network fully - well, this is a tall order. Especially if you have an inclination like myself to train for as short duration of time as possible