After fighting through Santander’s unlabeled variables I started working on a credit card fraud dataset and see something similar.
Are there any good resources for how to think around feature engineering when you don’t know the variables (just finished watching Jeremy’s ML Courses)?
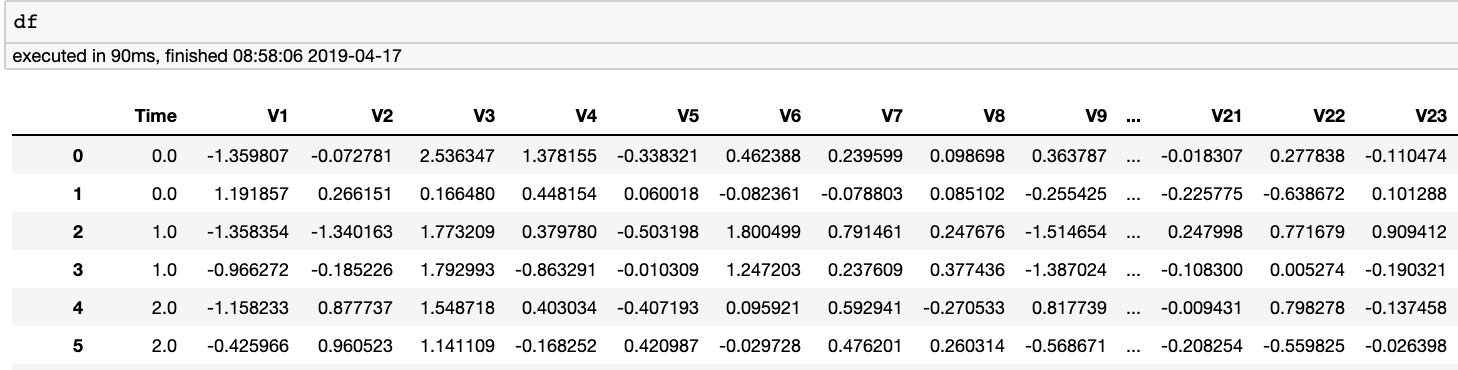
For example, the data we are given appears like this:
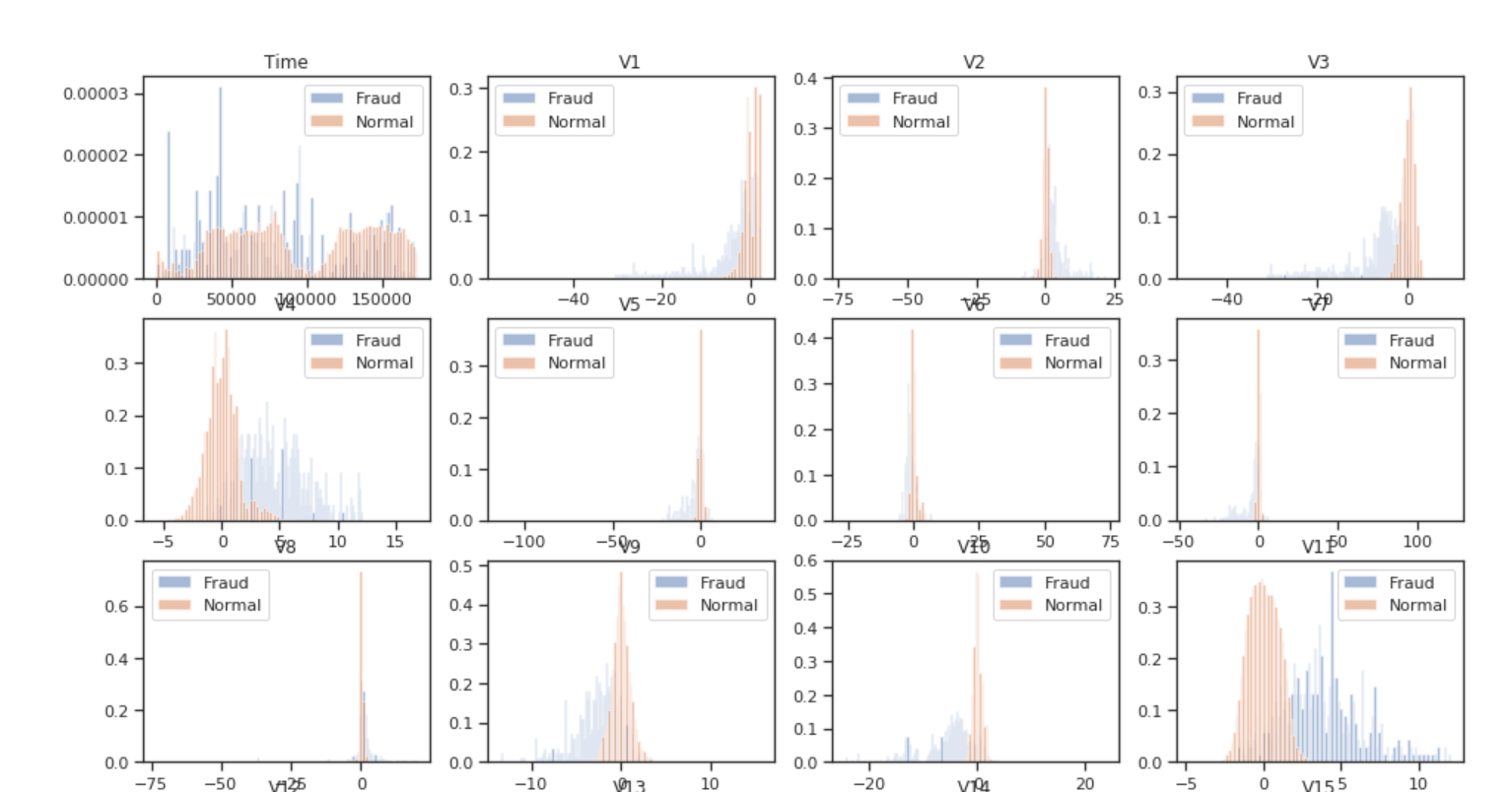
We can certainly see that the fraud instances and normal instances are distinct in the examples below. Can we make new features with it or will the NN pick up on it? For example, V4’s appears to have a split around .25. Should we make a V4_isAbove25 split feature?
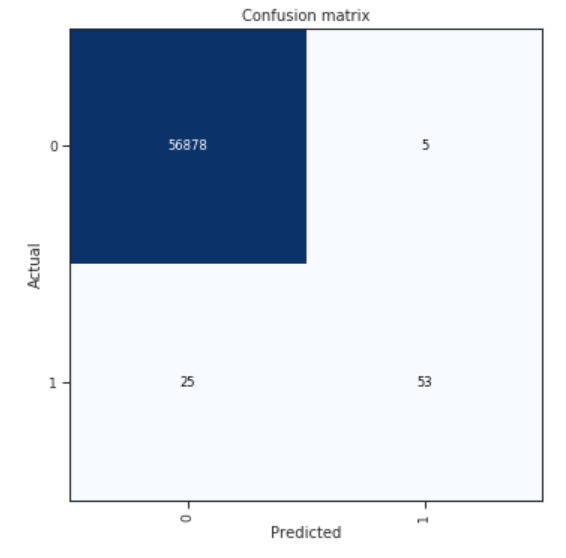
That being said, it’s not like we are doing that bad here. Then it might be just needing to mess around more with SMOTE and other unbalanced numbers strategies. We are just missing 25 instances. Which surprisingly when run on the test set gives a ridiculous AUC score of .9998 and accuracy of .9995