Hello folks,
I’d like to present you a project I have been working on, about making neural networks smaller and faster without degrading their performances. This has been an active subject of research recently, especially because most of our neural network are meant to be deployed on resource constrained devices such as mobile phones, drones, autonomous cars, …
I will present you two techniques: sparsification and pruning of a (convolutional) neural network.
Sparsifying the network
The first technique that I’d like to present you is the sparsification of a network, sometimes called pruning but, the goal being to make the neural network sparser (i.e. having some weight values of 0), I prefer the former denomination. This sparsification technique can be done on different granularities or levels: weights, vectors, kernel or even complete filters. The goal is similar to a l_1 regularization, but with a more aggresive behaviour because we force the weights to be zero.
There are several ways to do that and I won’t go into to much details about all techniques, but I will try to explain one of them, that I implemented for fastai. It comes from a paper called To prune, or not to prune: exploring the efficacy of pruning for model compression. The basic idea is to make the network gradually sparser by zeroing the smallest weights in terms of l_1-norms. This is done by following the scheduling:
with s_i and s_f being respectively the initial and final sparsity percentage, t_0 the starting sparsifying training step, \Delta t the sparsifying frequency. This gives a behaviour of sparsification as follows:
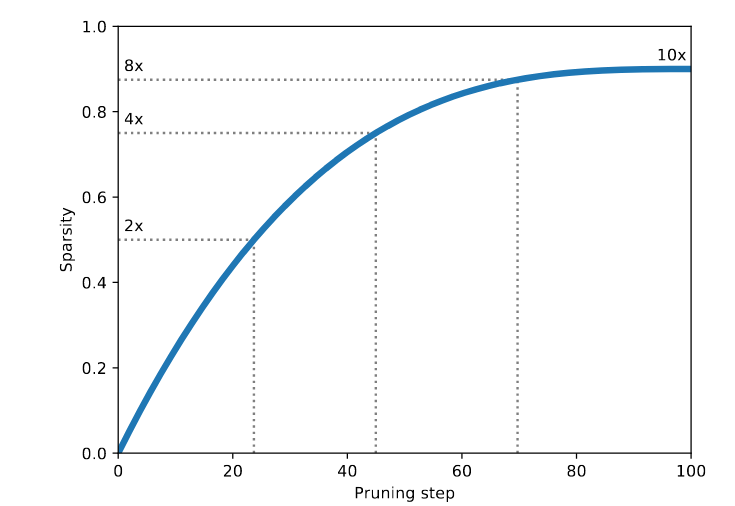
The scheduling is made so that an aggressive sparsification is done at the beginning, when the network is the most over-parametrized, and then gradually slowing down the process until the final sparsity value.
By applying this technique to a neural network, we then have a network that can be really sparse, but it is difficult to take advantage of this sparsity since it makes each convolution filter to contain several zeroes, that still must be stored as parameters and also computed during each forward pass.
The idea I implemented is thus to make this sparsification technique even more aggressive, and to sparsify not the weights individually, but complete convolution filters. By this mean, a zeroed filter can then be completely removed, meaning that we don’t have to store its values nor use it in the computations anymore.
Pruning the network
Here is the technique I call Pruning because now, the goal is to litterally remove some parts of the network. After having applied the sparsification at the level of filters, we can now remove them, because they are useless.
The idea is to remove a zeroed convolution filter in a layer i. This can be done as follows:

The filter in layer i is removed, so the activation map corresponding to this filter is also removed and, as the activation map is missing, the corresponding kernels in the layer i+1 are also removed. So for a convolution layer of k \times k filters, with m inputs and n outputs, removing a filter corresponds to remove k \times k \times m_i parameters in layer i and k \times k \times m_{i+1} parameters in layer i+1.
Removing filters and their corresponding feature maps is pretty straight-forward in simple CNNs such as VGG but this significantly grows in complexity when you have residual connexions like in ResNets.
The code is available here and the sparsification part is based on the work of @karanchahal, but made into a fastai Callback. Currently, sparsification at the level of weights and filters is available but the pruning is only for basic CNN architectures.
Please remember that this is WIP, and also that I am not a professional developper, so please be indulgent and don’t hesitate to give me feedback/advices and to contact me if you want to contribute. I am convinced that work in the direction of reducing the storage/computation costs of neural network would be beneficial to everyone !