Fair enough. Thanks again for the responses
So this error has come up numerous time in the forums, in particular here
size mismatch for 1.layers.1.2.weight: copying a param with shape torch.Size([2, 50]) from checkpoint, the shape in current model is torch.Size([1, 50]).
(However the fix to set the vocab of the classifier to the vocab of the language model isn’t addressing it.)
This is probably a stretch, but I’m guessing the issue has to do with that the language model was 1 column, whereas the classifier has 2 columns. so when I save a language model’s encoder then on a new machine create a classifier that loads the encoder, then load a saved classifier that’s where the mismatch is?
When you created the DataLoader for the language model, did you include two columns, or just one?
Usually when I see this, it’s because I mixed up data somewhere. I restart my Jupyter Notebook, and make sure to only load the proper data for what I’m trying to do, and it works.
If you’re sure you’re loading the proper DataLoaders and such, and you’re still stuck, here’s a tip that works from me. I like to start from scratch just to see where things went wrong. For example, when I’m testing errors like this, I’ll truncate my dataset so it’s very small (16 rows perhaps), train a language model on a single epoch, train a classifier with a single epoch, and see if the error persists. If so, you can easily switch variables around and retrain without having to wait hours for things to process.
Redoing everything seemed to help, the key is to make sure of consistency, same vocab, same encoder etc.,
I’m able to deploy on a separate machine, but inference takes a mighty long time – I’m using learn.save() as opposed to learn.export(). I was getting an error similar to here. The suggested solution was to upgrade the library, which I did ( now at fastai2 (0.0.16) and fastcore (0.1.16) ).
I now get this error instead:
learn.export()
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-26-fa5b61306ef3> in <module>
----> 1 learn.export()
~/.local/lib/python3.6/site-packages/fastai2/learner.py in export(self, fname, pickle_protocol)
497 #To avoid the warning that come from PyTorch about model not being checked
498 warnings.simplefilter("ignore")
--> 499 torch.save(self, self.path/fname, pickle_protocol=pickle_protocol)
500 self.create_opt()
501 if state is not None: self.opt.load_state_dict(state)
~/.local/lib/python3.6/site-packages/torch/serialization.py in save(obj, f, pickle_module, pickle_protocol, _use_new_zipfile_serialization)
368
369 with _open_file_like(f, 'wb') as opened_file:
--> 370 _legacy_save(obj, opened_file, pickle_module, pickle_protocol)
371
372
~/.local/lib/python3.6/site-packages/torch/serialization.py in _legacy_save(obj, f, pickle_module, pickle_protocol)
441 pickler = pickle_module.Pickler(f, protocol=pickle_protocol)
442 pickler.persistent_id = persistent_id
--> 443 pickler.dump(obj)
444
445 serialized_storage_keys = sorted(serialized_storages.keys())
TypeError: can't pickle SwigPyObject objects
How can I address this?
I haven’t seen that error before.
Personally, I use learn.save when I want to be able to continue training from that point. I use learn.export when I just want to do inference on another machine.
That said, I don’t think using either one would have an effect on inference times. If you’re doing inference in a batch, you can use learn.get_preds instead of learn.predict. Otherwise, you’re probably just seeing the difference between predicting on a GPU vs a CPU.
If you really want to test, you can force your GPU machine to run inference using only the CPU, and see how long it takes. I haven’t tried this on fastai2 yet, but this command might still work:
Is it possible to share your full notebook where this was working? If so, I might be able to figure it out and share the results here 
@sgugger Thanks for the transformers integration tutorial!
The “last” missing blocks in fastai2 are:
1°. An instance segmentation model (like maskrcnn from detecteron2/or just detectron2 integration - there are a plenty of FCOS models there: centermask, adelaidet, etc…).
2°. A graph neural network section.
Hey guys,
I was trying to learn inheritance in python and found a strange thing in fastai v2 between ‘Learner’ and ‘TextLearner’
`
@log_args(but=‘dls,model,opt_func,cbs’)
class Learner():
def init(self, dls, model, loss_func=None, opt_func=Adam, …`
`
@log_args(but_as=Learner.init)
@delegates(Learner.init)
class TextLearner(Learner):
“Basic class for a Learner in NLP.”
def init(self, model, dls, alpha=2., beta=1., moms=(0.8,0.7,0.8), **kwargs)`
Why init of Learner has args: dls then model and TextLearner as model then dls?
Can anyone please explain why it’s not a problem?
Thanks
Oops, it’s a typo. Will fix that.
Note that it doesn’t cause a problem since every application passes dls first then the model (so it’s just that the args are misnamed).
oh okay.
Question to the group:
I am trying to build a language model and the following code works:
data_lm = TextDataLoaders.from_csv(path, 'little_italy.csv', text_col='Answered Questions', is_lm=True)
I would like to do the same with the DataBlock API to have more flexibility so I tried this:
italy_lm = DataBlock(blocks=TextBlock.from_df('Answered Questions', is_lm=True),
get_x=ColReader('Answered Questions'),
splitter=RandomSplitter(0.1))
dls = italy_lm.dataloaders(data, bs=64, seq_len=72)
I am getting an error that says: AttributeError: 'Series' object has no attribute 'Answered Questions'
I tried doing italy_lm.summary(data) to debug and I get this:
[838 rows x 4 columns]
Found 838 items
2 datasets of sizes 755,83
Setting up Pipeline: ColReader -> Tokenizer -> Numericalize
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-86-1930d8083859> in <module>()
----> 1 italy_lm.summary(data)
13 frames
/usr/local/lib/python3.6/dist-packages/pandas/core/generic.py in __getattr__(self, name)
5272 if self._info_axis._can_hold_identifiers_and_holds_name(name):
5273 return self[name]
-> 5274 return object.__getattribute__(self, name)
5275
5276 def __setattr__(self, name: str, value) -> None:
AttributeError: 'Series' object has no attribute 'Answered Questions'
which I do not know how to interprete 
You should change get_x=ColReader('Answered Questions') to get_x=ColReader('texts') (can’t remember if it has an s or not).
That’s because tokenization puts your tokenized texts in a column named like that
2 Likes
 thanks a lot
thanks a lot even though creating the dataloaders works as expected and I can train the network, when I inspected the pipeline it still gives me an error:
Final sample: (TensorText([ 2, 8, 285, 8, 23, 8, 283, 15, 8, 9, 55, 16, 274, 14,
48, 74, 17, 97, 157, 22, 0]),)
Setting up after_item: Pipeline: ToTensor
Setting up before_batch: Pipeline:
Setting up after_batch: Pipeline:
Building one batch
Applying item_tfms to the first sample:
Pipeline: ToTensor
starting from
(TensorText of size 21)
applying ToTensor gives
(TensorText of size 21)
Adding the next 3 samples
No before_batch transform to apply
Collating items in a batch
Error! It's not possible to collate your items in a batch
Could not collate the 0-th members of your tuples because got the following shapes
torch.Size([21]),torch.Size([59]),torch.Size([59]),torch.Size([19])
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-73-1b741f3e22f1> in <module>()
----> 1 db_lm.summary(data)
6 frames
/usr/local/lib/python3.6/dist-packages/torch/utils/data/_utils/collate.py in default_collate(batch)
53 storage = elem.storage()._new_shared(numel)
54 out = elem.new(storage)
---> 55 return torch.stack(batch, 0, out=out)
56 elif elem_type.__module__ == 'numpy' and elem_type.__name__ != 'str_' \
57 and elem_type.__name__ != 'string_':
RuntimeError: stack expects each tensor to be equal size, but got [21] at entry 0 and [59] at entry 1
I would like to understand what is going on - i.e. why the subsequent steps work but .summary() is failing?
Building a classifier
I am trying to adapt this example for my application:

So far this is what I got:
def get_y(s):
return s['Classification']
dls_clas = DataBlock(
blocks=(TextBlock.from_df('Answered Questions', vocab=dls_lm.vocab, seq_len=dls.seq_len), CategoryBlock),
get_y = get_y,
splitter=RandomSplitter(0.1)).dataloaders(data, bs=128)
The error it returns me is:
/usr/local/lib/python3.6/dist-packages/fastai2/text/data.py in <listcomp>(.0)
43 self.o2i = defaultdict(int, {v:k for k,v in enumerate(self.vocab) if v != 'xxfake'})
44
---> 45 def encodes(self, o): return TensorText(tensor([self.o2i [o_] for o_ in o]))
46 def decodes(self, o): return L(self.vocab[o_] for o_ in o if self.vocab[o_] != PAD)
47
TypeError: unhashable type: 'L'
My main concern is how to specify that from the several columns that my dataframe contains the x is ‘Answered Questions’ and the y ‘Classification’. The remaining columns can simply be ignored. How can I specify it correctly?
@mgloria I’d suggest you use a ColReader for your get_x and get_y.
The reason why the stacking fails in the summary is because you have no item tfms that prepares the sequences and pads them up with specified pad token to be of equal size in a batch. However, I’m not too sure why they sequences in a batch aren’t padded to be of equal length while making a LM. I know they are made equal when building the classifier
1 Like
Is it possible to change the batch size for existing data loaders for a language model? I tried changing the dls.bs attribute but the actual batch size doesn’t seem to be affected. Is there a better way to do this without creating the data loaders from scratch?
print(learn.dls.bs)
128
learn.dls.bs = 64
print(learn.dls.bs)
64
x, y = learn.dls.one_batch()
print(x.shape)
torch.Size([128, 72])
Yep, that fixed it. Thanks!
I’ve made some progress on this. It appears the tensors are getting blanked out on the grad function:
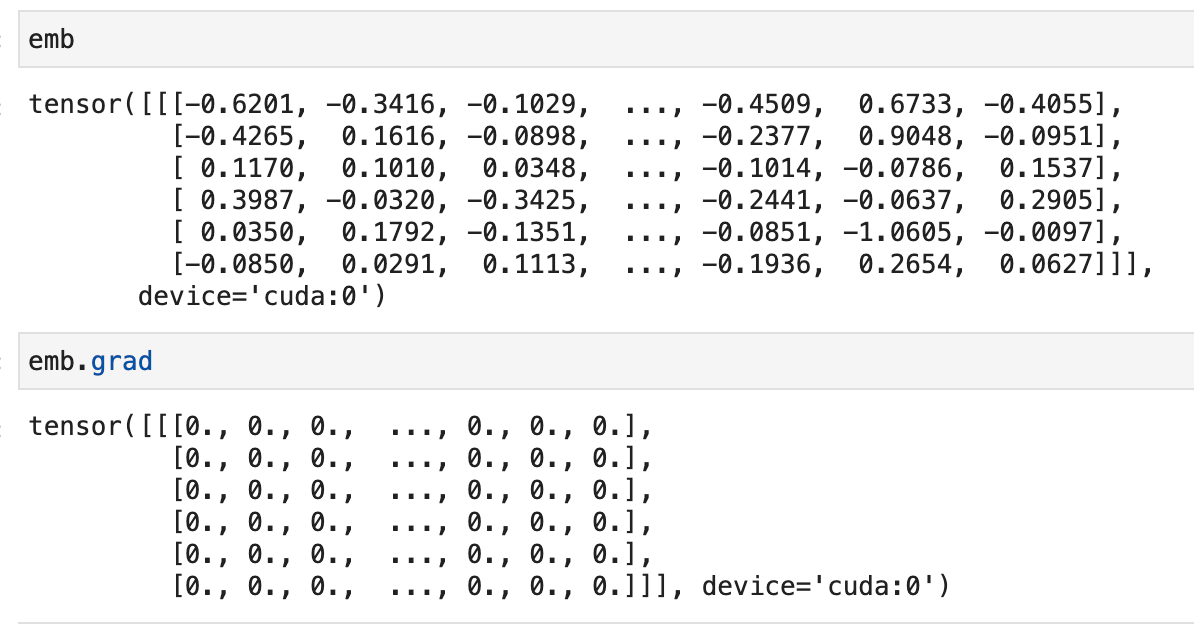
I’ve removed grad from the intrinsic_attention function, and it works now!
Used to be:
attn = emb.grad.squeeze().abs().sum(dim=-1)
Changed to:
attn = emb.squeeze().abs().sum(dim=-1)
Full function:
def intrinsic_attention(learn, text, class_id=None):
"Calculate the intrinsic attention of the input w.r.t to an output `class_id`, or the classification given by the model if `None`."
learn.model.train()
_eval_dropouts(learn.model)
learn.model.zero_grad()
learn.model.reset()
dl = learn.dls.test_dl([text])
batch = dl.one_batch()[0]
emb = learn.model[0].module.encoder(batch).detach().requires_grad_(True)
lstm = learn.model[0].module(emb, True)
learn.model.eval()
cl = learn.model[1]((lstm, torch.zeros_like(batch).bool(),))[0].softmax(dim=-1)
if class_id is None: class_id = cl.argmax()
cl[0][class_id].backward()
attn = emb.squeeze().abs().sum(dim=-1)
attn /= attn.max()
tok, _ = learn.dls.decode_batch((*tuplify(batch), *tuplify(cl)))[0]
return tok, attn

It concerns me that the earlier emb line has “requires_grad_(True)”, but I changed it to false and the result was the same.
Is the result inherently flawed without .grad on emb?
Wanted to post this quick example of running inference after you’ve created a text classifier using FastAI v2. It’s a little different than v1 and took me a little bit of time to find out.
from fastai2.text.all import *
defaults.device = torch.device('cpu')
path = Path('.')
learner = load_learner("./export.pkl")
f = open("/tmp/test.txt", "r")
test_file_contents = f.read()
_, _, losses = learner.predict(test_file_contents)
cats = [learner.dls.categorize.decode(i) for i in range(len(losses))]
predictions = sorted(
zip(cats, map(float, losses)),
key=lambda p: p[1],
reverse=True
)
print(predictions)
I can add a pull request to put this somewhere in the docs if wanted, but I’m not sure where it should go.
2 Likes