While dealing with big datasets, that do not fit in memory, if one wants to use .fit_one_cycle, all the data must be fed in a single epoch, right? How to actually do it? Via callback? If so, do you have the one, that feeds data while learning, or should I try to write my own?
There is nothing out of the box for dataframes that don’t fit into memory. You would need to write your own Transform to load it lazily.
There is nothing out of the box for dataframes that don’t fit into memory. You would need to write your own
Transformto load it lazily.
so, it is not a callback then?
While exporting a model with learn.export() I the error OverflowError: cannot serialize a string larger than 4GiB.
The usual fix for this issue is protocol=4, like here: pickle.dump(object, file, protocol=4).
Please consider updating the .export method. Thanks.
Assuming self.dl.items is a DataFrame, are you sure orig isn’t changed (hence can be used to restore value at the end)? I thought orig is first created as view, not a copy (unless values.copy(), or df = df.assign(...) is used):
df = pd.DataFrame({"X": [0,11,22,33,44]})
orig = df['X'].values
print(f"Original -- orig: {orig}, df['X'].values: {df['X'].values}")
df['X'] = df['X'].values[[4,0,2,3,1]]
print(f"Shuffled -- orig: {orig}, df['X'].values: {df['X'].values}")
gives:
Original -- orig: [ 0 11 22 33 44], df['X'].values: [ 0 11 22 33 44]
Shuffled -- orig: [44 0 22 33 11], df['X'].values: [44 0 22 33 11]
Hi, I have fond the way to do it, see in this thread Fastai2 tabular for out of memory datasets
1 Like
When in the order does FillMissing occur? I see that Categorify is 1 and NormalizeTab has 2, but FillMissing doesn’t have one. Would we presume 3 (or last?)
It seems TabularDataLoaders.from_df() fails if one of the categorical variables has actual None values (my data had this for some strange reason).
To recreate:
df = pd.DataFrame({'a':[1,2,None], 'b':[3,4,'tmp']})
df.iloc[2,1] = None # Pandas seem to cast None to NaN in the constructor
CategoryMap(df['a'], add_na=True) # works fine
CategoryMap(df['b'], add_na=True) # gives an error
The last line gives:
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-36-d98dc3407d7a> in <module>
----> 1 CategoryMap(df['b'], add_na=True)
~/anaconda3/envs/fastai2/lib/python3.7/site-packages/fastai2/data/transforms.py in __init__(self, col, sort, add_na)
209 # `o==o` is the generalized definition of non-NaN used by Pandas
210 items = L(o for o in col.unique() if o==o)
--> 211 if sort: items = items.sorted()
212 self.items = '#na#' + items if add_na else items
213 self.o2i = defaultdict(int, self.items.val2idx()) if add_na else dict(self.items.val2idx())
~/anaconda3/envs/fastai2/lib/python3.7/site-packages/fastcore/foundation.py in sorted(self, key, reverse)
360 elif isinstance(key,int): k=itemgetter(key)
361 else: k=key
--> 362 return self._new(sorted(self.items, key=k, reverse=reverse))
363
364 @classmethod
TypeError: '<' not supported between instances of 'NoneType' and 'int'
This is perhaps best fixed in preprocessing with df.fillna(value=np.nan) which gets rid of the None values?
1 Like
I am trying to follow the MultiCategory examples in https://github.com/fastai/fastai2/blob/master/nbs/40_tabular.core.ipynb. My particular dataset is formated similar to the “not one hot encoded” section that contains the _mock_multi_label. (it’s formatted like it’s output). I managed to get it working by following the one-hot-encoded labels and performed something like so:
vals = merged_df[y_names].unique()
c = []
for val in vals:
c += val.split(' ')
c = list(set(c))
def _mock_multi_label(df, classes=c):
targ_dict = {}
for c in classes:
targ_dict[c] = []
for row in df.itertuples():
labels = row.action.split(' ')
for c in classes:
targ_dict[c] = c in labels
for c in classes:
df[c] = np.array(targ_dict[c])
return df
df_main = _mock_multi_label(merged_df, c)
@EncodedMultiCategorize
def encodes(self, to:Tabular): return to
@EncodedMultiCategorize
def decodes(self, to:Tabular):
to.transform(to.y_names, lambda c: c==1)
return to
to = TabularPandas(merged_df, procs=[], cat_names=[], cont_names = cont_names,
y_names=c, y_block = MultiCategoryBlock(encoded=True, vocab=c), splits=splits)
This builds my DataLoaders just fine. From there, to not get an issue, we need to set dls.c to be the len() of c:
dls.c = len(c) 
I feel this process should not be this tedious, let me know any ideas. (Should the encodes/decodes be in the actual library too?)
I don’t understand your question. Those patched encodes and decodes are in tabular.core.
1 Like
I guess my question is will we ever support non-encoded multi-categorize? Instead of having to pre-process the one hot encode. Similar to how in the PLANETs we can pass in a delimiter to get_y. (I understand the two are separate from just MultiCategoryBlock, so this may not be straightforward to do)
If not, I’ll emphasize this in the docs
There is an example of that and the needed patches on MultiCategorize just after in the notebook.
Oh, though it’s not currently working. Guess there is a TODO to fix it missing.
2 Likes
For those interested, I’m working on trying to get fastai2 tabular to support multiple datatypes. This is based on my NumPy tutorial, and as we go along I think we’ll find a good way to integrate it to the ecosystem towards something we could possibly push to the main repo. If you’re interested in helping, see here:
Currently we’re looking at NumPy, cuDF, and others.
2 Likes
Does anyone know what the line
df[prefix + ‘Elapsed’] = field.astype(np.int64) // 10 ** 9
in add_datepart does exactly? I don’t really understand how to interpret the resulting feature.
Here is the full source code:
def add_datepart(df, field_name, prefix=None, drop=True, time=False):
"Helper function that adds columns relevant to a date in the column `field_name` of `df`."
make_date(df, field_name)
field = df[field_name]
prefix = ifnone(prefix, re.sub('[Dd]ate$', '', field_name))
attr = ['Year', 'Month', 'Week', 'Day', 'Dayofweek', 'Dayofyear', 'Is_month_end', 'Is_month_start',
'Is_quarter_end', 'Is_quarter_start', 'Is_year_end', 'Is_year_start']
if time: attr = attr + ['Hour', 'Minute', 'Second']
for n in attr: df[prefix + n] = getattr(field.dt, n.lower())
df[prefix + 'Elapsed'] = field.astype(np.int64) // 10 ** 9
if drop: df.drop(field_name, axis=1, inplace=True)
return dfHi,
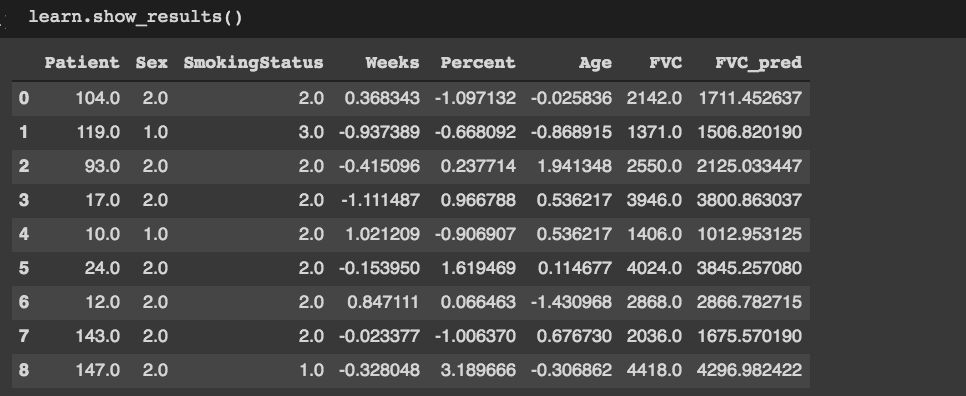
I’m trying to use tabular for a regression problem but am confused about the prediction output of the learner.
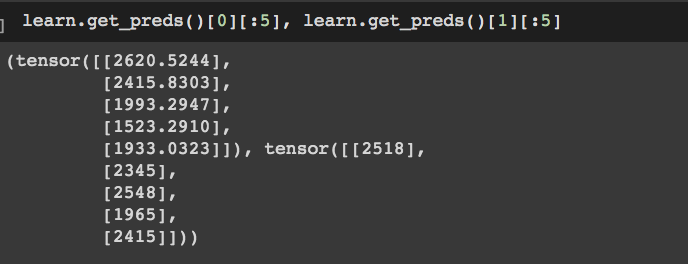
When I use learn.show_results(), I see the result in the y_pred column, but when I use learn.get_preds() it outputs 2 tensors and I can’t find documentation on what these are. Are they supposed to be the upper and lower confidence interval for the predictions?
If not, is there a way to get a a confidence interval for our prediction? This would be useful in the case of the latest Kaggle challenge for example: https://www.kaggle.com/c/osic-pulmonary-fibrosis-progression/overview/evaluation
Thanks,
Elliot
Can you provide a sample output of get_preds for one sample? (I haven’t played with regression much)
Hey Zach,
I’m trying to run something super simple to get a sense of the way to use fastaiv2 for it.
Get the data into TabularDataLoader:
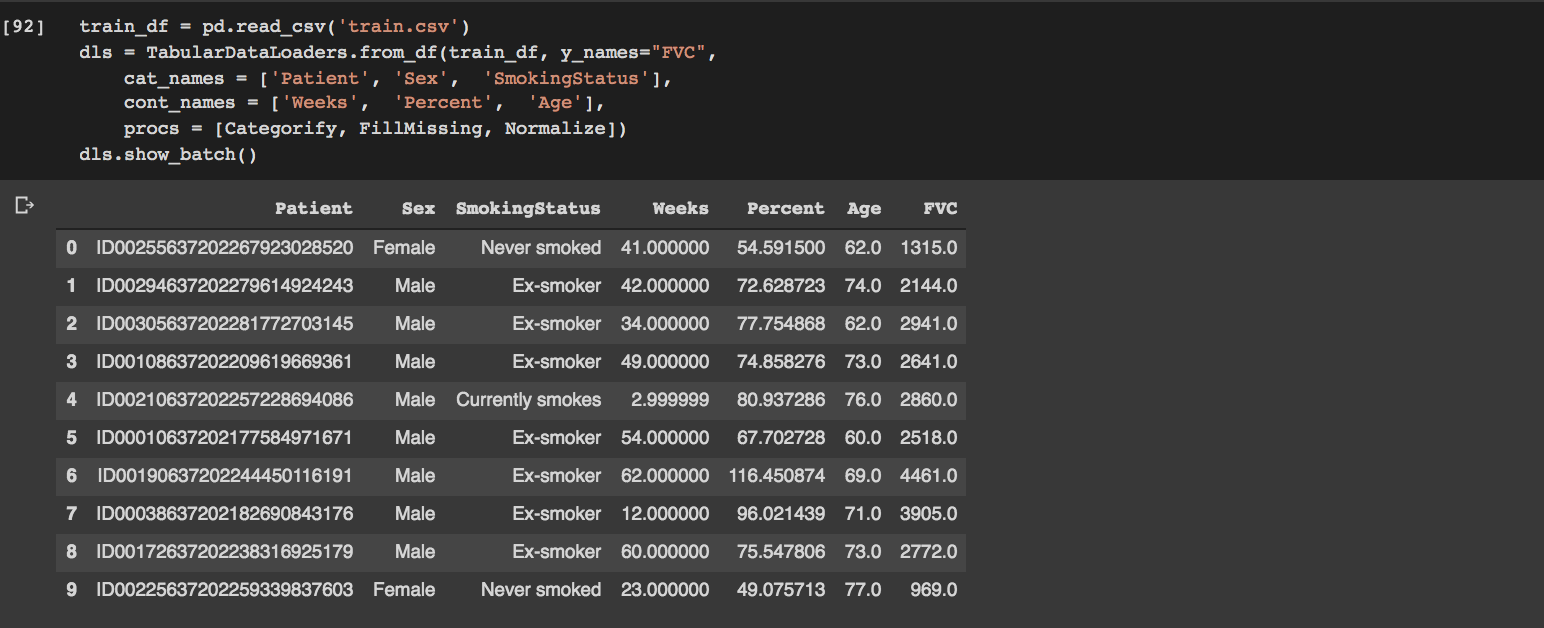
Train the model:
When I use show_results(), that’s what I’m getting:
And when I use get_preds() it returns a tuple of tensors looking like this (for the first 5 elements):
I might be wrong in the way I’m training or something else so please feel free to tell me if I’m completely off.
Thanks!
Hello, @muellerzr
I think there is a mistake in the code from the fastbook/09_tabular ,
in the image ,I run the code with the red underline and I got error,
I think it refers to xs_filt …
may you can clarify it ? it will be really nice,
Best regards,
Luis t

I have a random forest model and used TabularPandas() to do the normal preprocessing (Normalize, FillMissing and Categorify). Now I would like to share the model and the preprocessing with a partner without sharing the data. This example is listed in the documentation:
to = TabularPandas(df_main, procs, cat_names, cont_names, y_names="salary", splits=splits)
to_tst = to.new(df_test)
to_tst.process()
But that requires saving the entire to object, which includes the data. I couldn’t find way of just grabbing the procs from the TabularPandas object - any thoughts on this?
I want to test this on my side too but you should be able to do to_export = to.new_empty() and then export it for preprocessing.
1 Like